在现代乳制品行业的生产链条中,从牧场端的饲养管理到挤奶厅的生产采集,数据链路的构建构成了精准畜牧业的基础设施。随着全球乳业规模化程度的不断加深,特别是在美国、欧洲、新西兰以及以色列等农业技术领先的国家,动辄数千头规模的牧场已经无法依赖传统的人工视觉观察与经验判断来维持运营效率。这种高度集约化的生产模式要求建立一套不依赖主观经验的客观监测体系,而农业物联网算法正是这一体系的核心处理引擎。
在现代牧场的数据链路中,底层硬件传感器(如安装于牛只颈部或腿部的三轴加速度计、计步器、智能耳标,以及安装于挤奶机器人内部的奶流计、电导率仪和红外热成像摄像头)负责持续采集高频的物理和生理信号。然而,这些原始传感器数据通常伴随着极高的环境噪声,且呈现出高度的非线性与时序特征。农业算法的核心价值,即在于建立一条严密的输入数据 - 处理逻辑 - 输出决策因果关系链条。算法通过对离散、杂乱的时序数据进行滤波、特征提取、基线对比与模式识别,将物理信号转化为可执行的商业与医疗决策变量(如疾病预警标签、排卵窗口期推荐、产奶量及采食量预测指标)。
我们旨在剥离底层代码实现与复杂的数学推导,专注于解析乳制品领域主流农业算法的核心运行逻辑。通过系统性地剖析疾病预警、繁育监测以及精准饲喂等具体场景下的算法因果链条,揭示当前技术体系如何通过纵向个体历史数据的动态对比与多变量交叉验证,消除群体生理异质性带来的认知偏差,并探讨行业向机器学习范式转移过程中的技术演进与物理瓶颈。
------ 商情编辑部
疾病的早期预警是降低牧场兽药支出、减少非自愿淘汰率的关键环节。在算法介入之前,疾病的发现往往滞后于临床症状的显现。现代算法逻辑通过捕捉生理指标的微弱偏差,将干预时间点大幅提前。
乳腺炎(Mastitis)是导致乳企经济损失的核心疾病之一。在自动化挤奶厅或自动挤奶系统(Automatic Milking Systems, AMS)中,识别乳腺炎的基础输入变量主要包括特定电导率(Electrical Conductivity, EC)、单次产奶量以及奶流速。
电导率升高的底层生理学因果链条在于:当乳腺组织发生炎症反应时,血管通透性增加,导致血液中的钠离子和氯离子大量渗漏进入乳汁,从而显著改变了乳汁的电解质浓度,使其导电性能急剧上升。然而,在算法处理逻辑的构建中,直接设定绝对的电导率报警阈值是无效的。不同品种、不同泌乳天数(Days in Milk, DIM)乃至不同胎次的奶牛,其基础电导率存在显著的个体差异;同时,硬件端测量时管道内混入的空气泡沫也会导致电导率读数出现随机波动。
为应对这一问题,高精度商业系统(如以色列Afimilk系统)在硬件端采用无气泡设计的测量槽,确保流体静止后才进行电导率测定。在算法处理逻辑上,核心机制为动态基准线对比(Dynamic Baseline Comparison)。算法会在每次挤奶时提取电导率数据,并使用指数加权移动平均(EWMA)或简单滚动窗口算法,计算该特定个体在过去10天内的电导率平均值,以此作为该个体的动态生理基线。当前挤奶批次的实时测量值将被输入偏差函数,当偏差幅度超过历史方差的特定倍数时,算法将标记该读数为异常偏移。
然而,大量实证研究表明,仅依赖电导率单一变量的预警算法,其灵敏度(Sensitivity)通常仅徘徊在61%至78%之间,存在较高的漏报率与假阳性率。为了进一步提升预警的特异性(Specificity),前沿算法引入了多变量交叉验证与动态线性模型(Multivariate Dynamic Linear Models)。在这一逻辑框架下,算法的输入矩阵被扩展,新增了产奶量下降比率、乳糖偏离度以及由项圈收集的夜间反刍时间缩短比例。
通过偏最小二乘法(Partial Least Squares, PLS)或多元累积和(Multivariate Cumulative Sum, MCUSUM)控制图,算法计算多个生理时序变量之间的协方差与联合概率分布。因果链条表现为:当算法同时捕捉到电导率出现正向偏离、单次产奶量出现负向偏离,且夜间反刍时间低于滚动均值这三个维度的数据特征时,多变量模型会输出极高置信度的临床或亚临床乳腺炎预警标签。这种交叉验证机制有效排除了由于硬件误差或单次应激导致的单一指标波动,大幅提高了预警准确率。
跛行(Lameness)不仅引发动物福利问题,还会导致采食量下降与发情表现减弱。传统的跛行监测依赖于人工对牛群行走的步态进行评分(Locomotion Scoring),该方法主观性强、耗时且漏报率极高。现代物联网系统主要依赖绑定于奶牛腿部或颈部的三轴加速度计(3-axis Accelerometers)来收集输入数据。
跛行算法的输入数据为连续采集的高频(通常为30 Hz或更高)X、Y、Z三轴加速度物理量:
处理逻辑的第一步是信号去噪。牛只在牛舍内发生的偶然碰撞、硬件自身的震动都会产生高频噪声,算法通常应用中值滤波器(Median Filter)对原始高频信号进行平滑处理,还原真实的运动轨迹。
第二步为步态特征提取(Feature Extraction)。算法通过寻找加速度曲线上的周期性波峰与波谷,将连续的数据流切分为独立的步态周期,并精准提取出站立相(Stance Time)、摆动相(Swing Time)、每日总步数、日均躺卧时间(Lying Time)等核心指标。
在生理因果链条上,患有跛行的奶牛为了减轻疼痛,会本能地延长患肢在空中的摆动时间,缩短着地负重的时间,同时全天的总体躺卧时间会发生代偿性增加。初级基础算法通过对比当天的站立/躺卧时间比例与历史均值,输出异常偏差标签。但在实际的集约化牧场环境中,牛群调群、天气突变或饲喂时间的改变同样会引起行为时间预算的剧烈变动,导致高假阳性报警。
为此,高级时间序列分类算法被引入,以ROCKET(RandOm Convolutional KErnel Transform)算法为代表。该算法的输入不再是单日的静态统计量,而是提取时间序列中的斜率特征(Slope Features),即步数、躺卧时间在连续多天内变化率的斜率矩阵。ROCKET算法通过生成大量具有不同长度、权重和膨胀率的随机卷积核,对个体的时序特征向量进行卷积运算,捕捉隐藏在数据序列中的动态演进模式。
其核心优势在于,ROCKET模型并不比较个体与群体均值的差异,而是专注于个体自身的时序动态演变,这使其能够捕捉到跛行发展过程中渐进的、细微的步态恶化。算法最终输出的决策不仅能够准确区分健康与跛行状态(精度超过90%),还能够通过分类结果,将牛只分配到不同的干预名单中,例如指导修蹄师决定该牛只是需要常规的预防性修蹄(Corrective Claw Trimming, CCT),还是需要针对性的治疗性修蹄(Therapeutic Claw Trimming, TCT)。
发情识别(Estrus Detection)的准确率直接决定了牧场的繁殖周期、产犊间隔以及整体的经济产出。奶牛的发情周期通常为21天左右,受体内雌激素(Estrogen)水平飙升的生理驱动,发情期个体在行为上会表现出显著的活动量激增、试图跨爬同伴以及焦躁不安。
传统依赖计步器或颈圈的发情识别系统,其基础输入数据主要为三维加速度数据。由于硬件算力限制,早期的处理逻辑首先将三轴数据转换为一个无量纲的单一活动指数(Activity Index)。随后,为了剔除日常活动噪声(如采食过程中的移动、前往挤奶厅的走动),算法通常采用K均值聚类(K-means Clustering)将全天的数据方差划分为低、中、高三种活跃状态。
支持向量机(SVM)或决策树(Decision Trees)等机器学习算法被用于处理设定时间窗口(通常设定为0.5小时至1.5小时)内的数据切片。算法持续计算当前时间窗口内的活动指数,并与过去数天的同时间段进行对比。当活动量正向偏离历史均值达到预设标准差倍数时,系统触发发情嫌疑信号。
然而,单纯依赖活动量激增的判断极易受到非发情因素的干扰。例如,合群、转栏应激、甚至环境温度骤变,都会导致群体性的活动量异常。为了提升识别的阳性预测值(Positive Predictive Value, PPV),多维特征融合逻辑成为当前算法的主流(如DeLaval的DeepBlue AI模型)。
在这一逻辑下,当算法捕捉到活动量激增这一正向信号时,系统会同步提取同一时间窗口内的反刍时间与采食时间数据。生理学因果规律表明,发情期奶牛由于高度亢奋,其常规的采食与反刍行为会发生显著的按比例下降。算法通过比对活动量剧增与反刍量锐减这一组负相关的数据交叉特征,能够极为有效地剔除由于环境应激引发的假阳性报警。
尽管多维行为监控极大提高了识别准确率,但在确立精确的排卵窗口期以指导人工授精(Artificial Insemination, AI)时,行为数据仍存在时间轴上的宽泛性。前沿算法逻辑开始整合更为底层的生化模型:乳汁孕酮(Progesterone)浓度的时序概率模型。
其生物学因果链条在于:发情行为发生时,伴随着黄体的退化,孕酮水平急剧下降至谷底;排卵后,黄体重新形成,孕酮水平会呈指数级回升。复杂的数学模型(如IMP4生物模型)以既往的确诊发情事件作为时间轴的原点基准,通过监测挤奶机器人提取的牛奶中孕酮水平变化,构建个体的生殖周期概率分布图。在算法的最终判定阶段,系统进行严格的布尔逻辑(AND)联合运算:只有当加速度传感器输出的高活动量伴随低反刍标签,与孕酮模型输出的低孕酮窗口期在时间轴上实现重合验证时,算法才会输出最高置信度的适时授精推荐时间点。这种深度交叉约束机制,几乎消灭了由于传感器佩戴误差产生的错误报警,显著降低了牧场的精液浪费与空位天数。
必须指出,算法的底层逻辑设计高度受制于农业物理环境的约束。
在北美和北欧占主导的集约化舍饲系统(Confinement Systems)中,奶牛每天的活动范围被严格限制在卧床与采食通道之间,其基础物理位移极小,因此任何因发情引发的活动量激增信号都极为清晰,易于捕捉。
然而,在全球领先的放牧型乳业国家(如新西兰、爱尔兰),其主要的生产模式为全天候牧草放牧(Pasture-based Grazing)。在这种场景下,奶牛每天需要花费90%至95%的时间在广阔的草场上漫步、采食与反刍。这种伴随采食的长期行走活动,极易被传统算法误判为发情前期的烦躁走动,导致大量假阳性报警的产生,严重削弱了算法的可靠性。
针对这种特定的高噪声环境,新西兰等地的科技企业(如Halter系统)及研究机构使用的项圈算法(如Smartbow、CowManager系统)对其底层逻辑进行了彻底的重新校准。
处理逻辑中,算法引入了对头部空间姿态角的三维判别以及对颚部运动频率的解析:
只有在扣除放牧基线后,剩余的高频度不规则震动(即由于跨爬、被跨爬或急速奔跑产生的瞬间高重力加速度峰值),才会被输入到最终的发情概率判定函数中。这一基于放牧场景特征解耦的信号分离算法,成功跨越了传统算法在开阔草场应用中的技术瓶颈。
饲料成本通常占据现代乳企总运营支出的50%以上。通过算法精准预测奶牛个体的干物质摄入量(Dry Matter Intake, DMI)并拟合其产奶潜力,是实现配方精准投放、群体分群管理以及劣势个体淘汰决策的数据基石。
个体的产奶量在单次完整的泌乳周期(行业标准通常设定为305天)内的演变轨迹并非简单的线性分布,而是呈现出典型的非线性特征:分娩后初期产奶量迅速攀升,并在数十天后达到峰值,随后进入长达数月的缓慢衰退期直至干奶。在产量预测算法中,Wood's 泌乳曲线(Wood's Lactation Curve,数学上称为不完全伽马函数)是应用最为广泛且经典的参数化建模工具。
算法通过Levenberg-Marquardt非线性最小二乘法或高斯-牛顿算法等迭代拟合手段,对牧场每日自动收集或DHI(Dairy Herd Improvement)每月测定的产奶量历史数据进行拟合,求解以下核心函数模型:
在此公式中,Yt 表示在泌乳周期的第 t 天时的预测日产奶量,a,b,c 为算法需要估计的模型参数。这一优美简洁的方程之所以被广泛采纳,在于其参数直接对应了乳腺组织发育的底层生理机制 :
参数 a (a>0):代表初始泌乳潜力的缩放因子,反映了奶牛在分娩之初的绝对产能起点水平。
参数 b (b>0):作为幂函数的指数,控制了曲线到达泌乳高峰前的上升斜率。在生物学因果链条上,它对应了分娩后乳腺分泌细胞数量的快速增殖与分泌活性的急剧提升。
参数 c (c>0):作为指数衰减项的系数,控制了泌乳高峰过后的产量下降速率。在生理学上,它表征了随着泌乳期延长,乳腺分泌细胞进入自然凋亡与衰老的过程。
一旦通过早期产奶数据解算出这三个参数,牧场管理软件便能够通过导数运算衍生输出一系列关键性的前瞻预测指标。例如,算法通过令模型的一阶导数为零,可以精准计算出个体的理论高峰奶达到时间(tmax=b/c)与理论高峰产量(Ymax=a(b/c)be−b)。此外,算法进一步通过评估这些参数的复合函数形式(如计算 −(b+1)lnc)来量化个体的泌乳持久力(Persistency),即到达产奶高峰后维持高水平产出的能力。
在学术界,经常将参数化的Wood模型与基于细胞生化机理的Dijkstra机制模型(包含细胞增殖率、死亡率等微观方程的复杂积分)进行对比。尽管Dijkstra模型在解析细胞机理上更具深度,但Wood曲线凭借仅需三个参数即可实现的极高宏观拟合优度与鲁棒性,成为商业软件的首选。该算法逻辑最终输出的商业决策在于:算法能够基于奶牛分娩后最初几十天的产奶数据流,可靠地计算出定积分值,前瞻性地预测该个体在305天结束时的全期总产量。若该预测总产量无法覆盖预期饲料成本的盈亏平衡点,算法系统将自动把该牛只列入干奶或提前淘汰的建议清单中,从而不断优化整个牛群的饲料转化率体系。
确定了牛群的预期产出(产奶量)后,输入端干物质摄入量(DMI)的精确测算是防止能量负平衡(引发产后酮病)、避免过度饲喂(导致脂肪肝及严重饲料浪费)以及精准投喂TMR(全混合日粮)的前提。然而,在大群饲养环境中,除了使用造价高昂的自动称重采食槽外,直接物理测量每头牛的单日DMI几乎是不可能完成的任务。
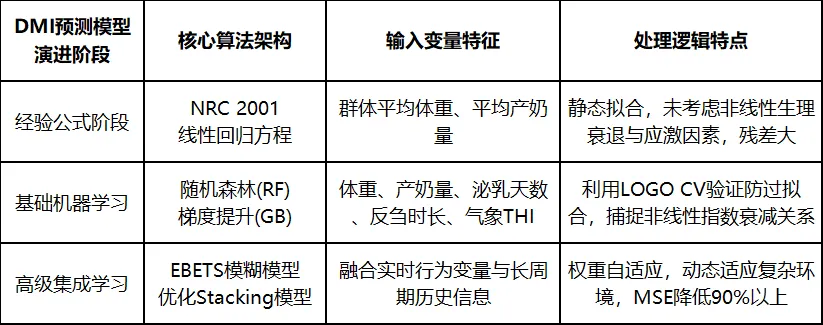
早期的预测系统普遍依赖于传统的静态经验公式(如经典的NRC 2001线性回归方程),主要基于群体的平均体重与平均产奶量构建。但此类线性模型在面对泌乳中后期的个体行为差异,以及高温高湿等环境应激时,其预测残差会显著放大。当前的测算算法正经历向多源特征融合的机器学习(Machine Learning, ML)演进的进程。
现代DMI预测算法的输入变量矩阵涵盖了三个维度的时序特征 :
表型与产能指标:个体准确体重(BW)、单日实际产奶量(Milk Yield)、当前的泌乳天数(DIM)。
高频行为传感指标:由项圈或耳标解算出的每日反刍总时长、采食时间占比、整体活动量水平。
微气候气象数据:牛舍内的实时温度、湿度以及衍生计算的温湿度指数(THI)。
在处理这些输入数据时,算法必须解决变量间高度非线性交互的难题。例如,随着泌乳周数的推进,DMI的下降呈现出非线性的指数级衰退趋势;而当温湿度指数越过应激阈值时,牛只的采食量会出现断崖式而非线性的下跌。为此,算法架构普遍采用了随机森林(Random Forest)、梯度提升树(Gradient Boosting, GB)、乃至基于多层网络架构的堆叠集成学习(Stacking Ensemble Learning)等模型。
为了保证机器学习模型不会由于死记硬背训练集中特定牛只的历史数据而产生过拟合现象,算法在训练验证阶段严格遵循留一群体交叉验证(Leave-One-Group-Out Cross Validation, LOGO CV)逻辑。即在模型训练过程中,每次都将某一头特定奶牛的完整生命周期数据作为测试集完全隔离,强制算法模型学习各项生理、行为与环境特征之间的深层物理映射关系,从而确保算法在部署到未见过的全新个体时,依然能够保持预测的精确度。
最新的研究进展显示,如基于改进金枪鱼群优化算法的堆叠模型(ITSO-optimized Stacking model)或基于误差进化的Takagi-Sugeno模糊模型(EBETS Fuzzy Model),通过结合历史信息的自适应权重调整,能够将预测的均方误差(MSE)较传统模型降低90%以上。通过特征重要性提取工具(如SHAP值分析)的回溯验证,算法证明了体重和产奶量是主导DMI预测的最核心权重因子,而反刍时间与环境温度起到了关键的微调作用。最终,该算法每日输出单头牛的绝对干物质摄入量(公斤/天),当这一预测数值与群体的实际投喂消耗量结合,算法即可计算出个体的剩余饲料消耗量(Residual Feed Intake, RFI),这一高阶指标将被直接输出至繁育与育种系统,用于指导选育拥有高饲料转化效率基因的优良后代。
随着牧场物联网(IoT)节点部署密度的几何级数增长以及传感器硬件计算算力的提升,乳制品行业的数据处理中枢正经历一次深刻的范式转移:从第一代依赖静态均值的规则阈值报警,全面向第二代具备自我演化能力的机器学习模式识别过渡。在这一进程中,新的算法框架不断引入的同时,也暴露出物理世界复杂环境带来的严峻技术瓶颈。
在乳腺炎监测领域,传统的电导率与产奶量监测均属于滞后性指标,必须在挤奶动作发生时才能获取数据。为了实现真正的连续性无接触监测,红外热成像(Infrared Thermography, IRT)被视为获取局部炎症表面温度骤升的新型高维数据源。当乳腺组织受到病原微生物侵染而发生免疫级联反应时,局部血管显著扩张导致血流量增加,从而表现为乳房皮肤表面温度比健康状态高出1至1.5摄氏度。
由于在规模化牧场中依赖人工手动在热成像画面中截取感兴趣区域(Region of Interest, ROI)毫无效率可言,前沿的预警逻辑已将深度卷积神经网络(CNN)架构作为核心处理引擎。例如基于SegFormer或CLE-UNet架构的语义分割算法,其底层处理逻辑包括在特征提取层中嵌入通道注意力机制(Channel Attention Mechanism),使得网络能够聚焦于更具代表性的热辐射特征通道。模型通过边界框约束或基于椭圆拟合的几何计算逻辑,能够自动抵抗背景墙壁、地面以及奶牛躯干其他部位的红外辐射干扰,精准地从复杂热成像视频流中分割出乳房区域以及眼部区域(通常将眼部温度作为内部核心体温的校准参考依据)。提取出的最大皮肤表面温度将被用作评估指标,该指标与体细胞数(SCC)呈现高度的正相关性。通过深度学习模型的自动化连续检测,系统能够实现无接触情况下的隐性乳腺炎极早期拦截,从而减少抗生素的非必要使用。
尽管深度学习等机器学习模型在实验室数据集上表现出极高的分类精度,但在将其下放至乳制品商业实体牧场部署时,不可避免地遭遇了物理世界的显著技术瓶颈。
首要瓶颈在于环境物理噪声引发的严重数据漂移(Data Drift)。例如,在上述的红外热成像(IRT)算法应用中,牧场环境内存在的强烈太阳光直接辐射、局部气流风速的变化、挤奶厅的地面积水反光,以及最致命的:乳房表面粘附的粪便与泥垢覆盖,都会严重干扰热辐射率的精确测定,造成输入源数据的物理层失真。为了解决这一问题,算法的预处理逻辑被迫变得更加冗长,必须引入挤奶前后的自动刷洗确认信号作为触发条件,并实时接入气象站数据,以微气候的温度和风速变量作为补偿性校准系数,才能保证输出的可靠性。
第二个核心瓶颈是数据传输带宽与云计算高延迟之间的尖锐矛盾。当部署了行为监控系统时,每个绑定在奶牛腿部或颈部的三轴加速度计如果以30Hz的采样率连续不断地产生高频原始数据,一个拥有上千头奶牛的中型牧场每日将产生以TB级别计算的海量未压缩数据流。传统物联网架构倾向于将所有节点的全量数据通过无线网络回传至云端中央服务器进行集中式模型推断。这一拓扑结构远远超出了偏远农场极其有限的无线局域网或蜂窝网络的传输承载力,并会导致极高的网络延迟,进而使牧场管理者错失对急性跛行或短暂发情窗口期的最佳干预时机。
由此,底层算法与硬件部署模式正加速向边缘计算(Edge Computing)架构演进。在这一全新的拓扑结构下,经过知识蒸馏或网络剪枝处理的轻量级算法模型(如精简版的随机森林分类器或低维卷积网络)被直接嵌入部署到奶牛佩戴的微控制器(即项圈或计步器内的芯片)以及牛舍内的雾计算节点(Fog Nodes)中。
传感器在本地物理设备上直接实时执行高频时序信号的平滑、降维与特征分类任务。其处理逻辑不再对外发送高维度的原始加速度三维曲线,而是通过芯片内部计算定性后,仅通过网络对外输出极低带宽的特征标签(例如,仅发送每小时内采食累计20分钟、反刍35分钟、发情概率达到0.8等离散状态变量)。这种端云协同(Edge-Cloud Hybrid Architecture)模式下,节点至云端的回传数据量可锐减逾84%,既保障了底层算法对跛行等急性行为偏离进行早期筛查的毫秒级实时响应,又有效维持了系统硬件极低的网络能耗需求,极大延长了传感器的电池寿命。
综合本篇对乳制品领域主流农业物联网算法底层逻辑的推演与拆解,我们必须客观看待当前技术的实际应用边界。这些复杂的统计算法与机器学习模型,其本质功能并非要完全替代兽医学的病理学临床诊断,而是在规模越来越庞大的牛群管理中,构建一道高通量、不间断运转的数字化过滤网。
从通过电导率动态基准与多变量交叉验证筛查隐性乳腺炎,到提取三维加速度斜率特征运用时序卷积网络监测步态跛行;从在重噪声放牧环境中剥离特征捕捉发情窗口,再到利用经典Wood泌乳曲线与集成学习架构预测个体的产奶潜力与干物质摄入量,算法发挥核心作用的逻辑在于:通过识别连续高频时序数据中偏离基线的微弱信号,将人类管理者的干预节点大幅提前到了临床症状显现或产能实质性损失发生之前。
然而,这些算法模型在提升乳企降本增效能力的进程中,仍受到数据碎片化的严重制约。当前牧场的数字化现状是,活动量监测算法(如项圈系统)、挤奶厅产量与电导率监测算法、以及精准饲喂系统算法,往往分属于不同硬件供应商构建的封闭商业生态系统中。这种缺乏互操作性的数据孤岛,使得各维度物理指标与机理学数学模型无法实现无缝的底层融合,阻碍了反映奶牛全生命周期状态的全要素数字孪生(Digital Twin)模型的有效构建。
展望未来技术的演进趋势,随着农业物联网通信协议的逐步统一以及开放API架构的推行,跨硬件平台的传感器多模态数据整合将成为底层技术发展的必然路径。与此同时,针对农场主普遍担忧的数据隐私与所有权归属问题 ,联邦学习(Federated Learning)技术将为行业提供解决方案。在无需将各牧场底层原始数据汇聚至中心服务器的前提下,算法模型能够在各个牧场边缘端进行本地化训练与参数共享,从而在保护商业机密与数据主权的同时,不断迭代进化出更具鲁棒性的全局预测模型。
只有在底层算力架构与跨界数据生态实现深度融合的背景下,农业算法才能在提升群体饲料转化效率、彻底减少抗生素依赖的进程中确立更为精准的决策边界,最终推动全球乳业工业体系真正迈向环境友好且经济可持续的数据驱动闭环。

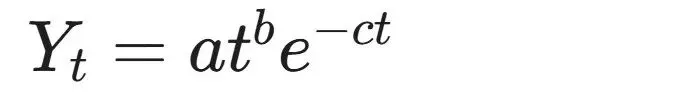

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
