推荐阅读 | 内蒙古农业大学王洪波教授团队:基于YOLOv10n的温室大棚番茄成熟度检测算法研究
基于YOLOv10n的温室大棚番茄成熟度检测算法研究
王洪波(1978—),男,汉族,中共党员,内蒙古土左旗人,工学博士,教授,内蒙古农业大学机电工程学院硕士研究生导师、学院教授委员会委员,机械设计教研室主任兼党支部书记。主要从事农牧业机械智能化以及生物质资源利用技术等方面的研究工作,同时承担机械原理、机械设计基础、现代设计理论与方法等课程的教学工作。第四届中国草学会草业机械专业委员会委员,第六届华北地区机械原理教学研究会理事。主持项目7项,代表性论著20余项,发明专利6项。
李君茂1 黄子露1何冬黎2夏凌奇1王洪波1
黄子露1何冬黎2夏凌奇1王洪波1
1.内蒙古农业大学机电工程学院,呼和浩特 010018;2.内蒙古第一机械集团股份有限公司,包头 014010
 摘 要针对温室大棚番茄采摘机器人的果实识别需求,本文提出了一种基于YOLOv10n框架的改进型目标检测模型YOLOv10n-SPPF-LSKA。该模型通过引入Kernel Warehouse Conv(KWConv)模块降低了计算资源需求,并将传统特征金字塔网络(FPN)优化为双向特征金字塔网络(BiFPN),增强了上下文信息捕获能力,减少了模型参数量。此外,在SPPF特征拼接后加入LSKA模块,利用大可分卷积核注意力机制强化重要特征权重,有效提升了模型对目标形状的敏感性,降低了纹理依赖性。试验结果表明:YOLOv10n-SPPF-LSKA在mAP指标上提升1.3%,计算量仅为6.7 G FLOPs;与RT-DETR、Faster-RCNN、SSD、YOLOv5、YOLOv7和YOLOv8等模型相比,该模型在检测精度和速度方面均具有显著优势,为番茄采摘机器人的智能化发展提供了技术支持。
摘 要针对温室大棚番茄采摘机器人的果实识别需求,本文提出了一种基于YOLOv10n框架的改进型目标检测模型YOLOv10n-SPPF-LSKA。该模型通过引入Kernel Warehouse Conv(KWConv)模块降低了计算资源需求,并将传统特征金字塔网络(FPN)优化为双向特征金字塔网络(BiFPN),增强了上下文信息捕获能力,减少了模型参数量。此外,在SPPF特征拼接后加入LSKA模块,利用大可分卷积核注意力机制强化重要特征权重,有效提升了模型对目标形状的敏感性,降低了纹理依赖性。试验结果表明:YOLOv10n-SPPF-LSKA在mAP指标上提升1.3%,计算量仅为6.7 G FLOPs;与RT-DETR、Faster-RCNN、SSD、YOLOv5、YOLOv7和YOLOv8等模型相比,该模型在检测精度和速度方面均具有显著优势,为番茄采摘机器人的智能化发展提供了技术支持。 关键词番茄果实检测;YOLOv10n;金字塔网络;注意力机制;采摘机器人
关键词番茄果实检测;YOLOv10n;金字塔网络;注意力机制;采摘机器人本文来源:内蒙古农业大学学报(自然科学版)2025年第46卷第6期
基金项目:内蒙古自治区科技创新引导项目(Kcj1-202205)
番茄是温室大棚中的一种重要作物,目前仍以人工采摘方式为主,工作效率低且成本较高[1-2]。为实现高效快捷的番茄采摘,精准的目标检测技术必不可少[3-5]。目标检测可以为机械化采摘提供目标信息,从而实现番茄机械化采摘。因此,提高目标检测技术的准确性对于提高采摘效率具有重要意义[6-7]。随着深度学习、计算机视觉技术的快速发展,基于深度学习的目标检测方法已在果蔬采摘方面得到了应用[8-9]。近年来基于深度学习的卷积神经网络成为了研究热点,也被应用到了果蔬识别中[10-12]。目前,目标检测大致分为两大主流算法,One-stage和Two-stage[13-15]。在One-stage算法方面:胡继文等[16]为提高松木表面缺陷检测精确度,提出了一种改进RT-DETR的检测模型RIC-DETR,精确率达到了95.4%。Kaukab等[17]开发了深度融合(NBR-DF)方法的非目标背景去除,使用YOLOv5实现的NBR-DF通过使用多模态信息作为输入,提出了一种基于注意力的深度融合模块,对多模态特征进行自适应融合,并进行了相关试验,结果表明,NBR-DF方法的实时检测准确率平均达到0.964。Yan等[18]提出了基于BottleneckCSP模块和注意力机制的改进YOLOv5模型,有效提高了遮挡的检测精度。Liu等[19]提出一种改进的YOLOv5模型,实现果园中柑橘的识别和计数,经过试验验证,识别精确率达到了98.40%。Sun等[20-21]用轻量级的ShuffleNet和GhostNet结构替换了YOLOv5的Backbone和Head,提出了YOLOv5-PRE,实现了快速准确的检测。在Two-stage算法方面:Gao等[22]使用Faster R-CNN模型对遮挡苹果果实进行了检测,试验结果表明,该模型对遮挡苹果果实的平均检测准确率达到了80.00%~90.00%。Chen等[23]提出了一种基于遗传算法和反向传播的两阶段训练方法来训练新的Faster GG-R-CNN模型,平均精度达到94.57%。Seo等[24]基于Faster R-CNN,并使用色调值来开发番茄果实基于图像的成熟度标准,识别的准确率达到90.20%。在诸多学者的研究中,改进模型在果实遮挡检测中取得了显著进展,但由于其较高的计算复杂度和冗余参数设计,导致计算量大、检测延迟高,这严重制约了农业机器人等在实时性要求较高的场景中的实际应用。此外,在温室环境中,果实目标由于光照、遮挡、密集程度等因素的影响,导致目标识别效率低。为保证温室环境下番茄目标检测精度,同时提高温室环境下番茄目标检测速度,本文基于YOLOv10n目标检测框架,提出的番茄果实成熟度检测模型YOLOv10n-SPPF-LSKA不仅参数量和计算量相对较小,而且还保证了较高的精确率。模型引入LSKA注意力机制,采用大卷积核深度可分离卷积,通过扩大感受野捕获目标的整体形状特征,而非依赖易受光照影响的局部纹理,对光照变化的敏感度低,降低了误检和漏检的概率。LSKA通过水平和垂直卷积提取长距离空间依赖关系,增强对遮挡目标边界的感知能力,通过对卷积输出进行通道压缩后,经Sigmoid生成空间权重图,动态增强遮挡目标的可见区域;采用双向跨尺度连接,将高层语义特征与底层细节特征动态融合,当底层特征因遮挡丢失目标位置时,高层特征可通过上下文推断辅助定位,提升遮挡目标的识别率。这为番茄果实采摘机器人提供目标信息,为自动化采摘提供理论依据。1材料与方法
温室番茄图像数据采集于呼和浩特市土默特左旗农庄采摘园。为保证数据集的多样性,增强模型的鲁棒性,提高模型的泛化能力,于2023年5月中旬采集了不同时间段、不同成熟度、不同拍摄角度、不同距离、不同光照角度的番茄果实图像,剔除因拍摄因素造成的不清晰图像,最终得到2 080张番茄图像,如图1所示。▲ 图1不同场景下的温室番茄图像
Fig.1Images of tomatoes in different scenes in a greenhouse
数据集构建过程涉及图像标注与数据分类2个核心环节。本研究通过Labelimg工具对图像进行人工标注,并采用YOLO数据格式规范。现行国家标准GH/T 1193—2021依据颜色与大小特征,将番茄成熟度划分为6个阶段:未熟期、绿熟期、变色期、红熟前期、红熟中期和红熟后期。其中红熟中期与红熟后期果实着色面积分别为40%~60%和60%~100%,温室栽培环境下仅采收这2个成熟阶段的果实[25]。本试验将检测目标整合为3个类别:将着色面积低于40%的未熟期至红熟前期的果实归为未成熟类(标记为green);着色面积40%~60%的红熟中期的果实划为待成熟类(标记为salmon pink);着色面积超过70%的红熟后期的果实划为成熟类(标记为red)。图2展示了具体的图像标注示例。完成标注工作后,系统自动生成与图像文件同名的txt标注文档,并按7∶1∶2的比例将标注数据划分为训练集(1 456张)、验证集(208张)、测试集(416张),确保图像文件与标注文件名称对应。▲ 图2标注完成的数据集示例▲ Fig.2Example of a labelled completed dataset注:green为未成熟类;salmon pink为待成熟类;red为成熟类。
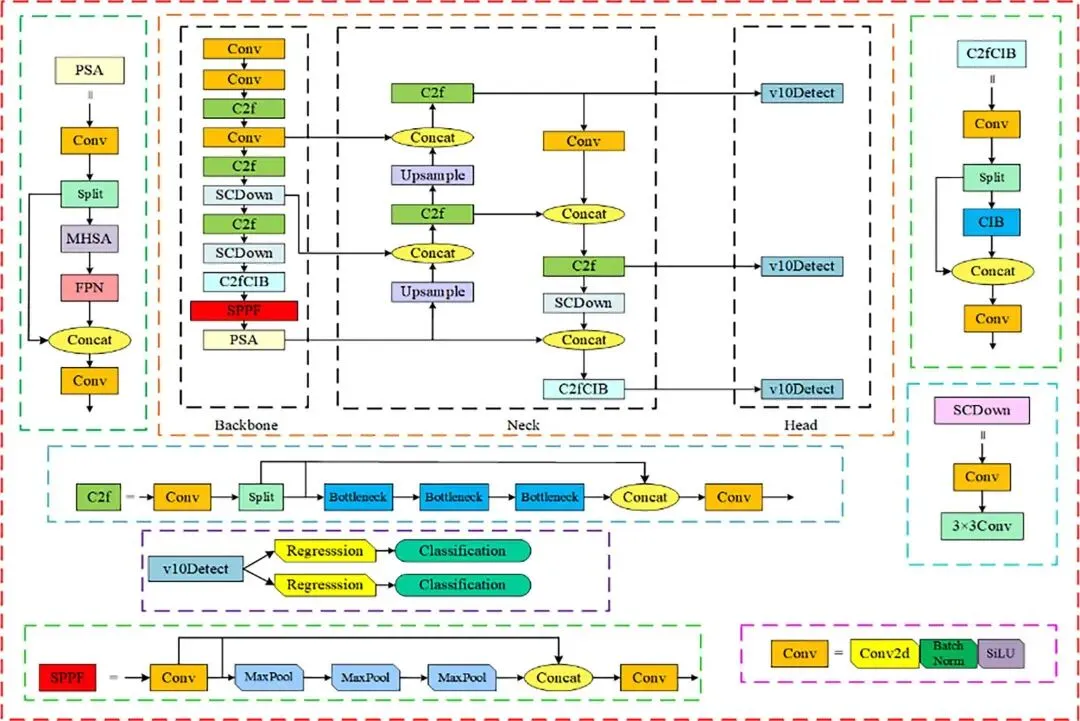
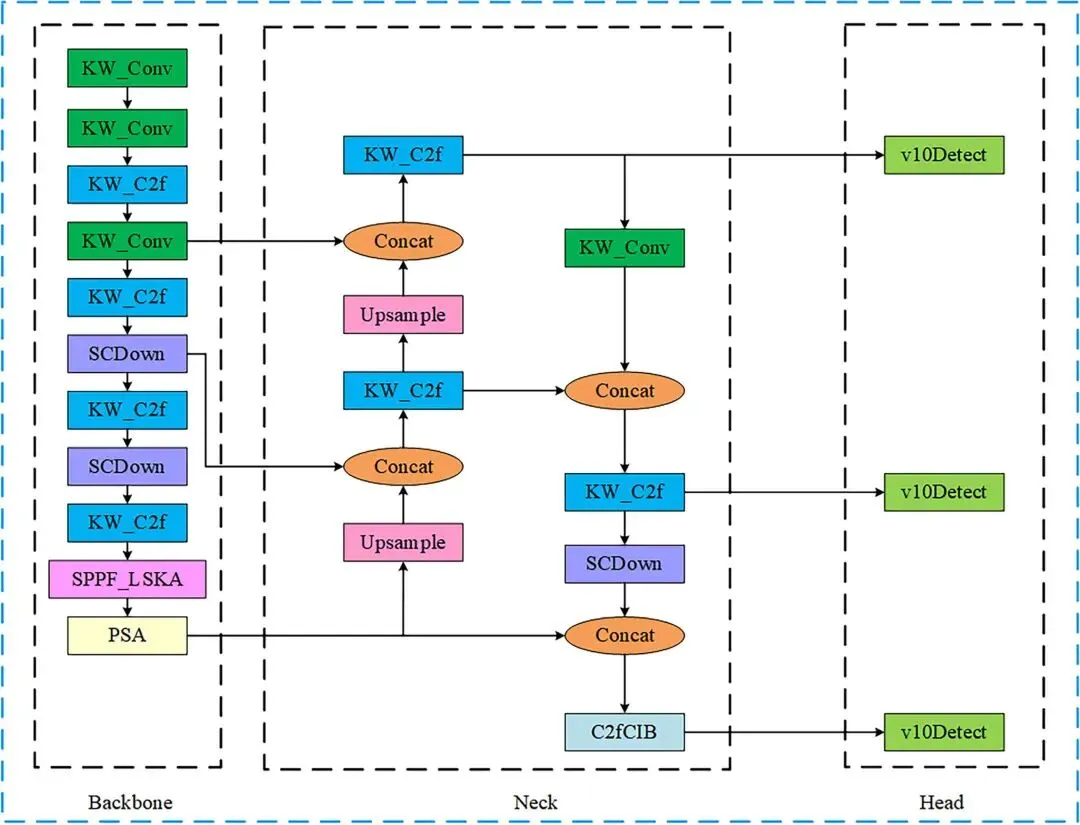
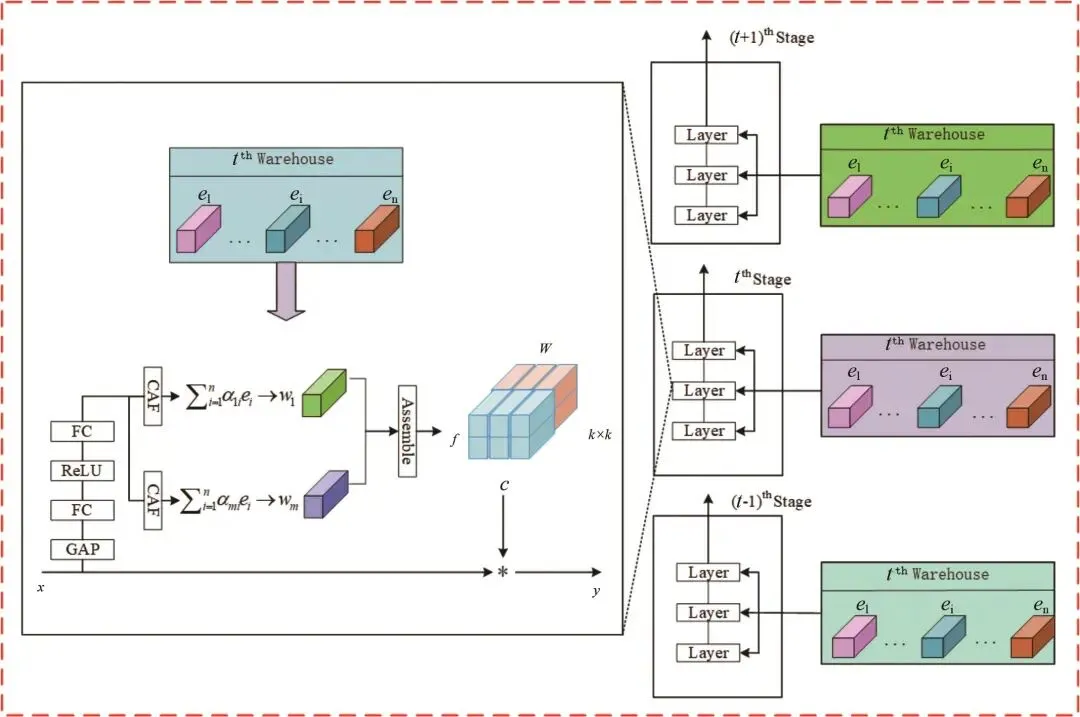
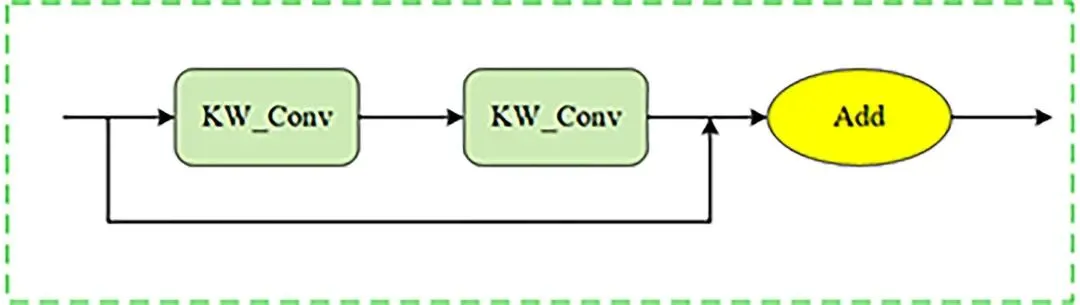
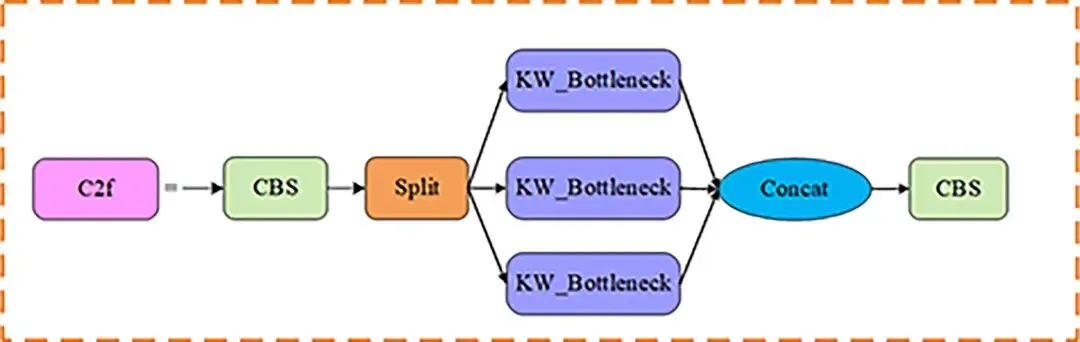
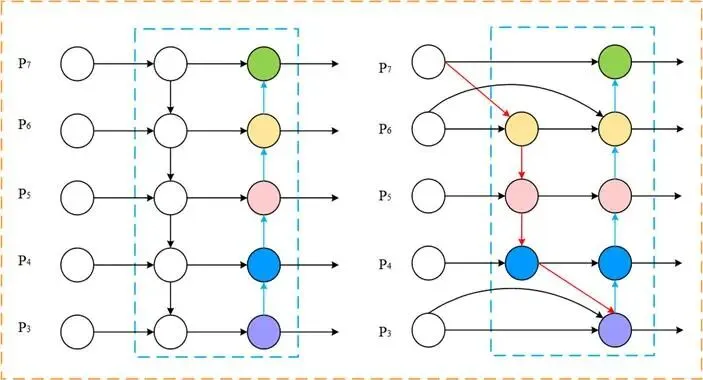
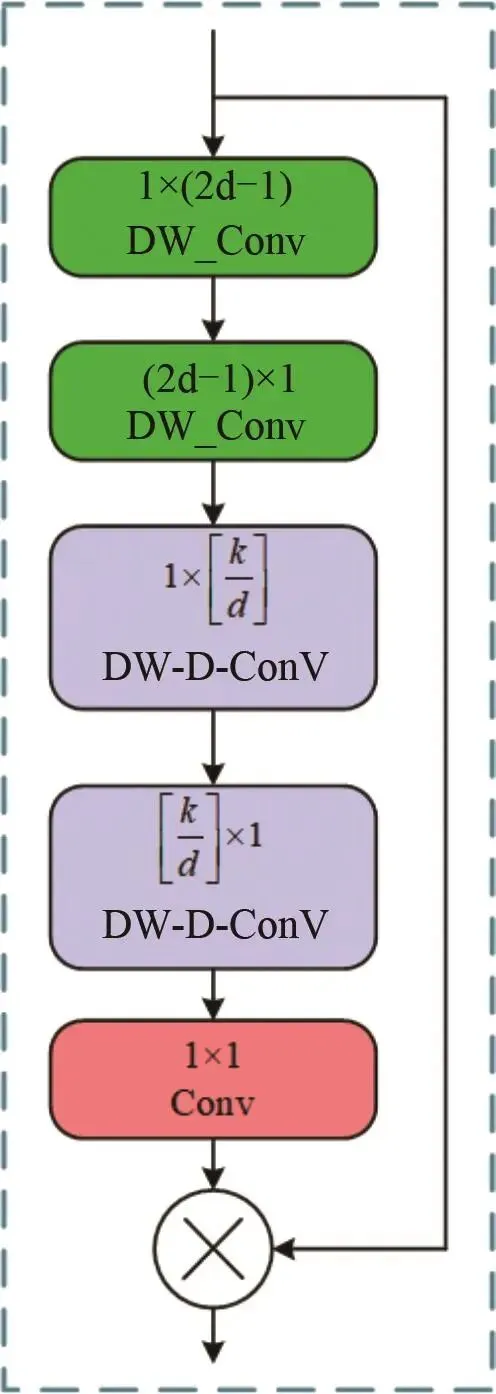
本文以YOLOv10n为基础模型,其结构如图3所示,其网络模型主要由输入部分、主干网络、颈部网络、头部网络4个部分组成[26-28]。YOLOv10n采用高效的特征提取网络CSPDarkne。这个网络通过多个卷积层、批标准化和激活函数将输入图像转换为高维特征图;使用特征金字塔网络(FPN)来融合来自不同尺度的特征,以增强对不同尺寸目标的检测能力;使用锚框机制,用于捕捉不同形状和尺寸的目标。▲ 图3YOLOv10n网络结构图▲ Fig.3YOLOv10n network diagram改进的YOLOv10n模型网络结构如图4所示,从以下3个方面进行了改进:▲ 图4改进的YOLOv10n目标检测模型▲ Fig.4Improved YOLOv10n object detection model①通过构建全局共享的“核仓库”(Kernel Warehouse),动态选择或组合卷积核,替代传统静态卷积核,优化模型的复杂度,在减少冗余参数的同时,提升了特征表达能力。②对原有的YOLOv10n算法中的特征金字塔网络(FPN)结构进行了改进,采用双向特征金字塔网络(BiFPN)来取代原始的FPN结构。BiFPN通过加强不同尺度特征之间的信息流动和融合,减少模型参数量,提升了模型在不同尺度上对番茄识别特征的检测能力。③在SPPF的特征拼接后,添加LSKA注意力机制,有效提升了目标检测系统的性能。LSKA注意力机制使用了可分离卷积,有效降低了计算资源的消耗;通过增强重要特征的权重,提升模型对目标形状的敏感性;减少在复杂环境下对纹理信息的过度依赖,从而使模型更具鲁棒性。1.2.3Kernel Warehouse Conv模块动态包络通过研究n个静态核的线性混合并权衡其样本所关联的关注度,展现出优于普通包络的性能,然而,这会使包络的参数数量增加n倍,从而使得动态包络的优化变得困难。而Kernel Warehouse包络利用ConvNet中同一层和相邻层的卷积参数依赖关系, 重新构建了动态卷积,不仅增强了同一层连续核之间的包络参数依赖性,还有效地平衡了参数效率和表达能力之间的关系。如图5所示。▲ 图5Kernel Warehouse结构示意图▲ Fig.5Schematic diagram of the Kernel Warehouse structure首先,核分区通过捕捉同一卷积层内的参数依赖关系,对线性混合中的“核”进行了重新定义,通过核分割将静态核划分为多个不兼容、尺寸相同的“核单元”,以增强相同体积团块内参数的依赖性。核分区后,内核单元w1、…、wm被视为“本地内核”,并引入一个共享存储库,其中包含n个内核单元。共享存储库作用于相邻卷积层中的每个核单元,进一步提高了模型的表达能力。KW卷积通过输入相关的标量注意力,利用线性混合学习,实现静态的动态组合。这种设计不仅有效地调整了模型的大小,而且在保持相同的卷积参数的同时灵活地调整了表示能力,提高了模型的性能。仓库的构建与共享利用了相邻卷积层间的参数依赖,重新诠释了“组装核”的概念,并构建出一个大型仓库,其中包含多个局部核,以支持跨层的线性混合共享。而对比驱动的注意函数则专注于解决在具有挑战性的环境下跨层线性混合学习范式下的注意力优化问题,从而对“注意力函数”进行了新的诠释。通过这些组件的协同作用,Kernel Warehouse在有限的卷积参数预算下展现出了高度的灵活性,使得能够以足够大的核数来达成参数效率和表示能力的理想平衡。此外,Kernel Warehouse还引入了关注机制。这一机制能够进一步增强模型的注意力集中能力,提高了模型在处理复杂任务时的性能。如图6和图7所示,利用了Kernel Warehouse重构原始网络瓶颈和C2f模块,这个新结构增强了连续层之间的包络参数依赖性,增强了网络学习能力,降低了模型的复杂度,同时也降低了模型在边缘设备上部署的难度。▲ 图6KWConv模块▲ Fig.6KWConv modules▲ 图7KW_C2f模块▲ Fig.7KW_C2f modulesBiFPN(bidirectional feature pyramid network)是一种用于图像特征融合的先进网络结构,主要用于目标检测任务,目的是增强多尺度特征的表示能力,提高目标检测的性能。与传统的特征金字塔网络(FPN)相比,BiFPN通过引入双向信息流和特征融合机制,提供了更为高效和灵活的特征整合方法。BiFPN的结构主要包含以下4个组成部分:特征金字塔层、加权特征融合、上采样操作和下采样操作。BiFPN通过结构优化与动态融合机制,实现了多尺度特征的高效交互,成为轻量化检测模型的核心组件之一,为后续研究提供了重要的设计范式。BiFPN结构如图8所示。▲ 图8BiFPN结构图▲ Fig.8BiFPN structure diagram1.2.5Large Separable Kernel Attention 注意力机制LSKA将深度卷积层的二维卷积核分解为级联的水平和垂直一维卷积核,在注意力模块中直接使用具有大卷积核的深度卷积层,无需额外的块。LSKA注意力模块通过优化二维卷积结构实现特征增强,其工作机制可分为3个核心处理阶段:①基础特征提取阶段:通过水平和垂直2个正交方向的一维卷积操作,对输入特征进行方向性特征编码。这种正交分解策略在保持特征表达能力的同时,显著降低了计算复杂度,形成初始的空间注意力分布。②多尺度上下文融合阶段:采用可调节扩张率的空间扩展卷积构建层次化特征处理架构。通过调整卷积核的感知范围,该模块在不增加参数量级的情况下,实现了跨尺度的空间特征交互,有效捕捉局部细节与全局语义的关联性。③动态特征增强阶段:经过特征融合层的整合处理,生成具有空间自适应的注意力权重矩阵。该矩阵通过逐元素乘法作用于原始特征映射,形成具有显著区域增强效应的特征表达。这种动态调节机制使网络能够自适应强化关键特征区域的信息响应。LSKA注意力机制通过利用大且可分离的卷积核及空间扩张卷积来捕捉图像的广泛上下文信息,生成注意力图,并通过这个注意力图加权原始特征,以此增强网络对于重要特征的关注度,提高模型的性能。将一个k×k卷积分解成(2d-1)×(2d-1)的深度卷积(DW-Conv)、k/d×k/d的深度扩张卷积(DW-D-Conv)和1×1的卷积(Conv),再将深度卷积和深度扩张卷积分解成横向、纵向2个层次,最后再将各卷积核相连。LSKA结构如图9所示。▲ 图9LSKA结构图▲ Fig.9LSKA structure diagram2结果与分析
本研究在标准化的试验环境中进行,试验与训练所用的操作系统为Windows11,CPU为12th Gen Intel(R) Core(TM) i5-12500H 3.10 GHz,GPU为NVIDIA GeForce RTX 3060 Laptop GPU,运行内存16 GB。CUDA 版本为12.0,在PyTorch2.1.0深度学习框架下,采用Python3.10.14进行实现。视觉样本进行了规范化预处理操作,具体包含2个关键步骤:首先实施像素尺寸统一化处理以消除数据异质性,其次采用多样化的数据扩充策略来提升算法适应性。试验平台严格遵循可验证性原则进行参数配置,从而确保试验数据的有效性和研究结论的客观复现可能。采用精确度(precision, P)、召回率(recall, R)、平均精度均值(mean average precision, mAP)和模型参数量来表达模型的检测性能。 | 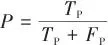 | (1) |
| 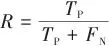 | (2) |
| 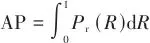 | (3) |
| 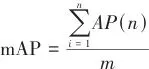 | (4) |
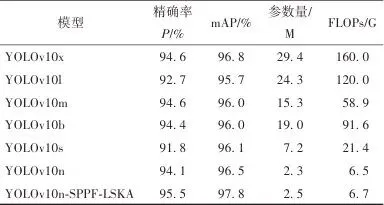
式中:TP表示正样本被预测为正样本的个数,即正确预测番茄成熟度等级的个数;FP表示负样本被预测为正样本的个数,即错误预测番茄成熟度等级的个数;FN表示负样本被预测为负样本的个数,即番茄成熟度等级被错误预测的个数;m表示所检测番茄目标类别的数量;mAP作为多类别检测任务中最重要的评估指标之一,能够综合反映模型在不同类别上的检测性能。为了更好地分析改进的YOLOv10n模型对番茄果实成熟度的检测性能,本文将改进的YOLOv10n模型和YOLOv10系列模型进行了对比试验,来验证改进模型的检测效果。对比试验结果如表1所示。▼ 表1对比试验结果▼ Table 1Compare the results of the test
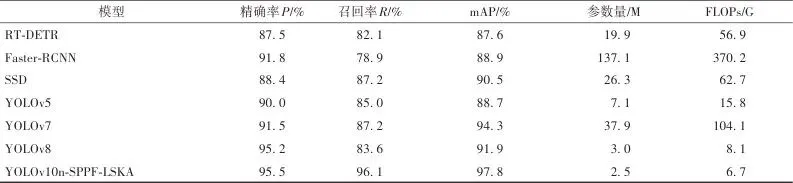
如表1所示,YOLOv10n目标检测模型相比其他YOLOv10系列目标检测模型,在保证了较高的mAP前提下,其参数量最小,便于移动端的部署。改进的YOLOv10n-SPPF-LSKA模型相比YOLOv10n基础模型仅增加了0.2 M参数量,但精确率提升了1.4%,平均精度均值提升了1.3%,在满足轻量化需求的同时,兼顾了更高的精度,能够实现温室大棚环境下采摘机器人对番茄果实的精准、高效识别,更加利于番茄采摘机器人的采摘。为了全面评价改进的YOLOv10n-SPPF-LSKA模型对番茄果实成熟度的检测效果,在保证试验条件一致的前提下,本研究选用了RT-DETR、Faster-RCNN、SSD、YOLOv5、YOLOv7和YOLOv8等6种目标检测模型进行性能对比。试验对比结果如表2所示。▼ 表2不同模型对比结果▼ Table 2Comparison of results between different models
如表2所示,改进的YOLOv10n-SPPF-LSKA模型的精确率、召回率、平均精度均值分别为95.5%、96.1%、97.8%,对比其他检测模型,改进的YOLOv10n-SPPF-LSKA模型在平均精度均值上相比RT-DETR、Faster-RCNN、SSD、YOLOv5、YOLOv7和YOLOv8模型分别提高了个10.2%、8.9%、7.3%、9.1%、3.5%、5.9%,表明了YOLOv10n-SPPF-LSKA模型在温室大棚番茄成熟度检测中具有更高的精确性。综合来看,YOLOv10n-SPPF-LSKA模型在检测性能、资源使用和模型轻量化上呈现出了均衡而优异的性能,对温室大棚番茄成熟度检测的效果更好。为了评价改进的YOLOv10n-SPPF-LSKA模型检测番茄果实成熟度的效果,训练好的模型通过416张测试集图像进行检测精度的验证,图10、图11分别为YOLOv10n、YOLOv10n-SPPF-LSKA模型在光照及遮挡和密集下的检测实例图。▲ 图10光照情况下番茄果实检测效果图
Fig.10Rendering of tomato fruit detection under light conditions
▲ 图11遮挡和密集情况下番茄果实检测效果图
Fig.11Detection renderings of tomato fruits in occlusion and density
由图10可知,在光照情况下,YOLOv10n模型对番茄果实的识别率较低,平均识别率为62.0%,且有漏检情况,而YOLOv10n-SPPF-LSKA模型对番茄果实的识别精确率相比YOLOv10n模型有很大的提高,平均识别率为82.5%,提升了20.5%。由图11可知,在遮挡和果实密集情况下,YOLOv10n模型对番茄果实的平均识别率达到了91.2%,而YOLOv10n-SPPF-LSKA模型对番茄果实的平均识别率达到了93.0%,提升了1.8%。这表明YOLOv10n-SPPF-LSKA模型可以有效地检测出番茄果实的成熟度,并且识别率较高。更加复杂场景中所采集的图像,如光照、遮挡、重叠的图像,改进的YOLOv10n-SPPF-LSKA模型均可以实现有效检测。3结论
本文基于YOLOv10n模型改进了番茄果实成熟度检测模型,实现了对温室大棚的番茄果实成熟度快速准确检测。主要结论如下:①提出了基于YOLOv10n模型改进的YOLOv10n-SPPF-LSKA模型,使用了计算量较低的Kernel Warehouse Conv(KWConv),将传统的特征金字塔网络(FPN)结构更新为双向特征金字塔网络(BiFPN),增强对上下文信息的捕获,减少模型参数的数量。另外,在SPPF的特征拼接后,加入LSKA模块,提升模型对目标形状的敏感性,同时减少对纹理的依赖。试验结果表明:该模型对于检测番茄果实成熟度的精确率为95.5%,召回率为96.1%,mAP为97.8%;通过消融试验结果可知,改进的YOLOv10n-SPPF-LSKA模型相比YOLOv10n基础模型仅增加了0.2 M参数量,但精确率提升了1.4%,平均精度均值提升了1.3%,在保证模型轻量化的同时,实现了更高的检测精度,满足温室大棚环境下番茄果实成熟度快速、准确地检测。②改进的YOLOv10n-SPPF-LSKA模型与RTDETR、Faster-RCNN、SSD、YOLOv5、YOLOv7和YOLOv8等主流模型相比,平均精度均值分别提高了10.2%、8.9%、7.3%、9.1%、3.5%、5.9%。试验结果表明,改进的YOLOv10n-SPPF-LSKA模型更加轻量化且精度较高,基本满足采摘机器人工作的实时性需求。③在光照情况下,YOLOv10n-SPPF-LSKA模型对番茄果实的平均识别率达到82.5%,相比YOLOv10n模型提升了20.5%;在遮挡和果实密集情况下,YOLOv10n-SPPF-LSKA模型对番茄果实的平均识别率达到了93.0%,相比YOLOv10n模型提升了1.8%。这表明YOLOv10n-SPPF-LSKA模型可以有效地检测出番茄果实的成熟度,并且识别率较高。更加复杂场景中所采集的图像,如光照、遮挡、重叠的图像,改进的YOLOv10n-SPPF-LSKA模型均可以实现有效检测。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
