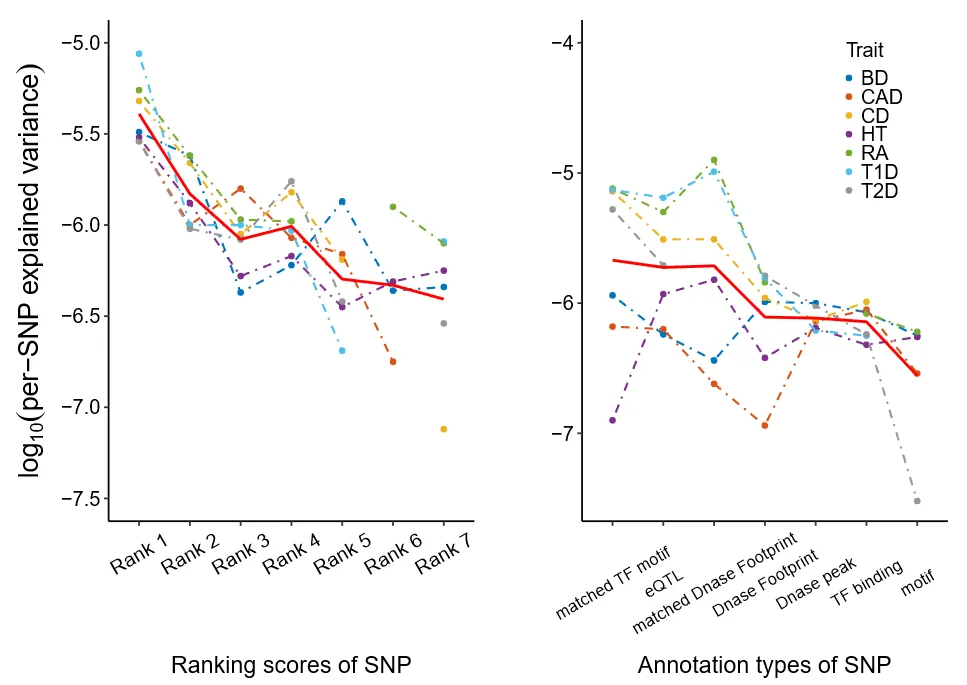
基于RegulomeDB数据库的SNP排序评分与注释类型,计算各功能区域内平均每个SNP所能解释的表型方差与遗传力。结果表明,评分越高(即功能证据越强)的SNP,其对七种疾病性状的贡献越大,证实注释可作为先验信息指导建模(图1)。
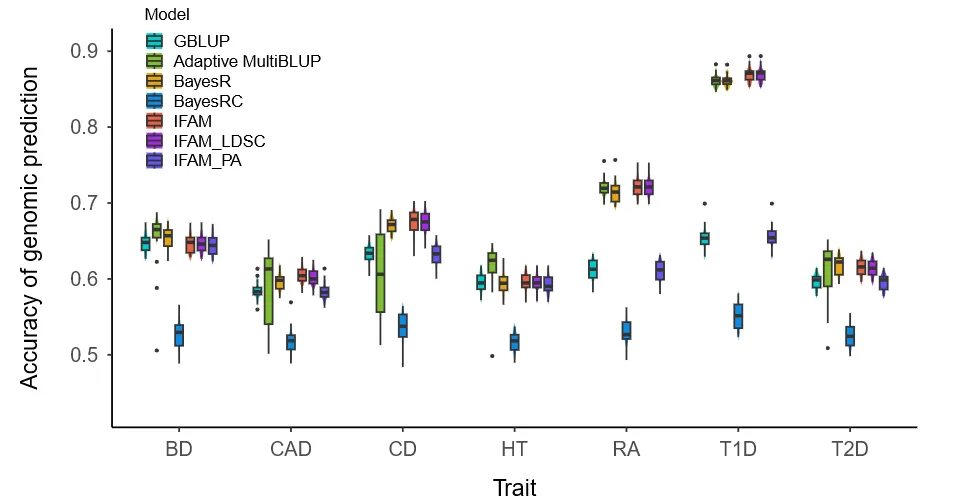
IFAM相比GBLUP平均提高AUC达9.46%,对T1D提高32.98%;使用LDSC注释或随机伪注释后精度下降,而BayesRC对注释质量高度敏感。IFAM在稳健性和精度间取得最佳平衡(图2)。
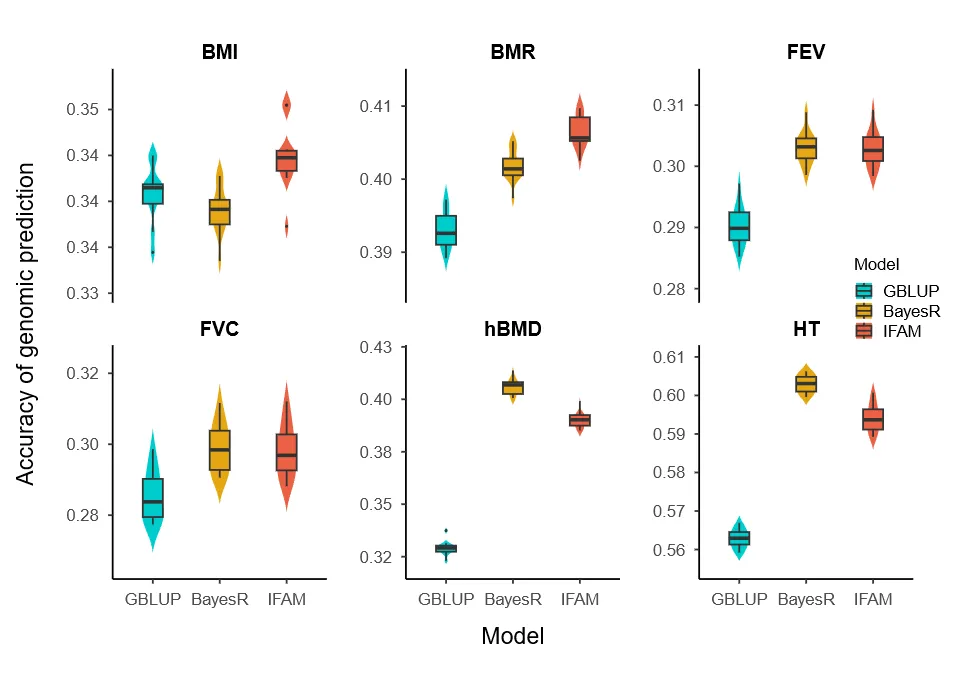
在六个性状中,IFAM与BayesR精度相近(平均提升约6%),但IFAM预测偏倚更接近1。未合并注释的多随机效应模型精度下降43%,证明自动合并策略对UKB规模数据的方差组分稳定估计至关重要(图3)。
图3:不同模型在英国生物银行(UK Biobank)数据集上的预测性能
IFAM对所有七个性状均优于GBLUP,背膘厚改善最明显(+7.90%);相比Adaptive MultiBLUP平均提高52.57%。使用伪注释后精度降至GBLUP以下,证明IFAM对生物学信息的敏感性(图4)。
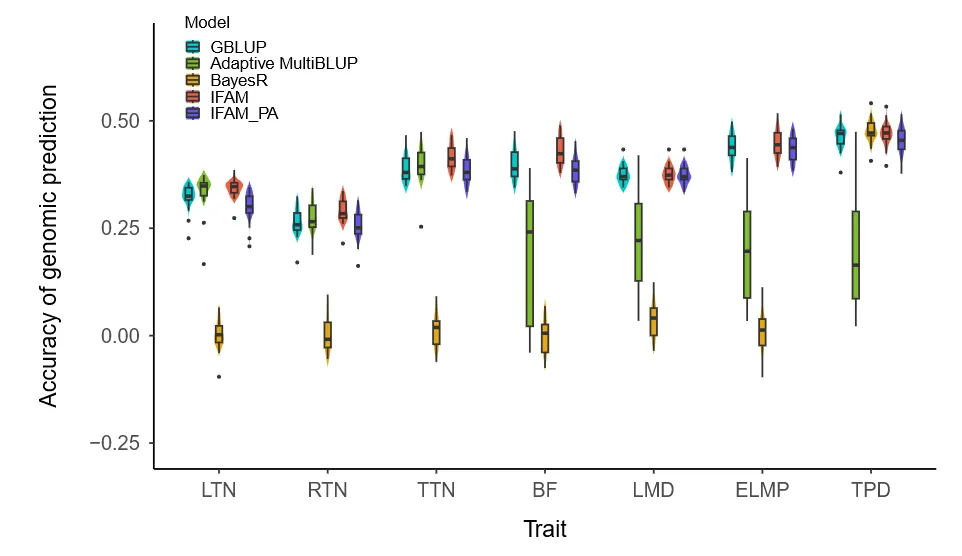
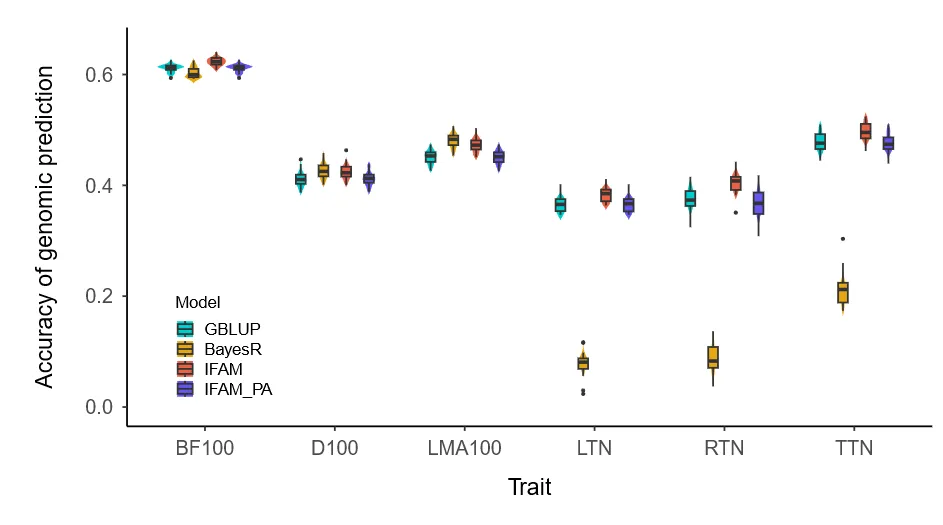
IFAM比GBLUP平均提高4.09%,且优于未合并模型(+5.58%)。Adaptive MultiBLUP因估计遗传值方差为零而失败,BayesR在乳头数性状上表现不佳。IFAM兼具高精度、稳健性与计算效率(图5)。
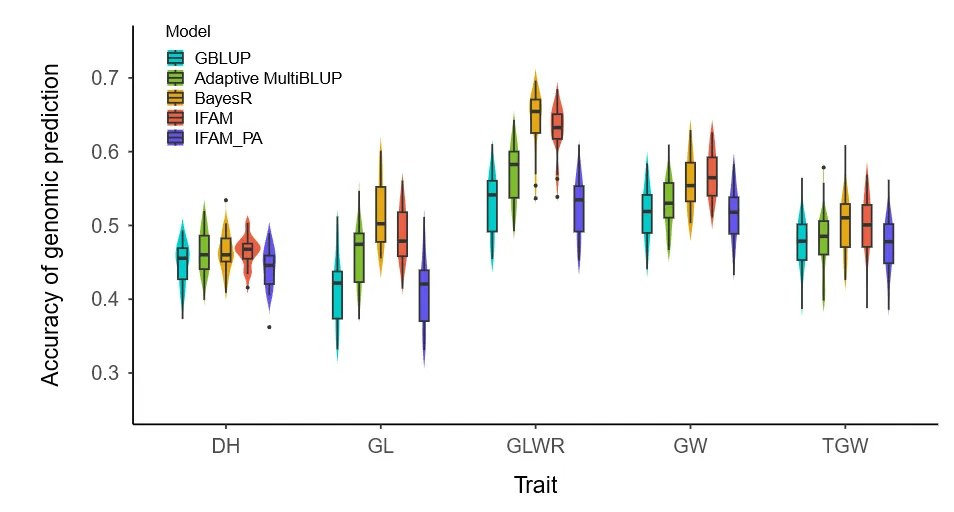
IFAM比GBLUP平均提高10.83%,粒长宽比增益达18.15%;精度略低于BayesR(-1.54%)但偏倚更优,且运行时间从数小时减至数分钟。伪注释后精度下降10.33%,证实模型对真实注释的依赖性(图6)。









 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
