数据准备与预训练
作者从全球范围收集了三类卫星数据:
MODIS(250/500 m,7 波段,8 天分辨率,约 1.57M 图像)
Landsat‑8/9(30 m,6 波段,4–7 天分辨率,约 13.39M 图像)
Sentinel‑2(10/20 m 统一为 10 m,10 波段,5 天分辨率,约 10.28M 图像)
每张图像被裁剪为 224×224 像素,并随机采样 3–32 帧的时序序列。预训练监督信号来自全球 30 m 土地覆盖产品 GLC_FCS30D:对每个图像块,根据地理坐标统计其中 8 类主要地物(农田、森林、灌木、草地、湿地、水体、裸地、城市)及背景的面积占比,得到一个 9 维分数向量 p。模型学习从输入卫星图像预测该向量,损失函数为 L1 损失。
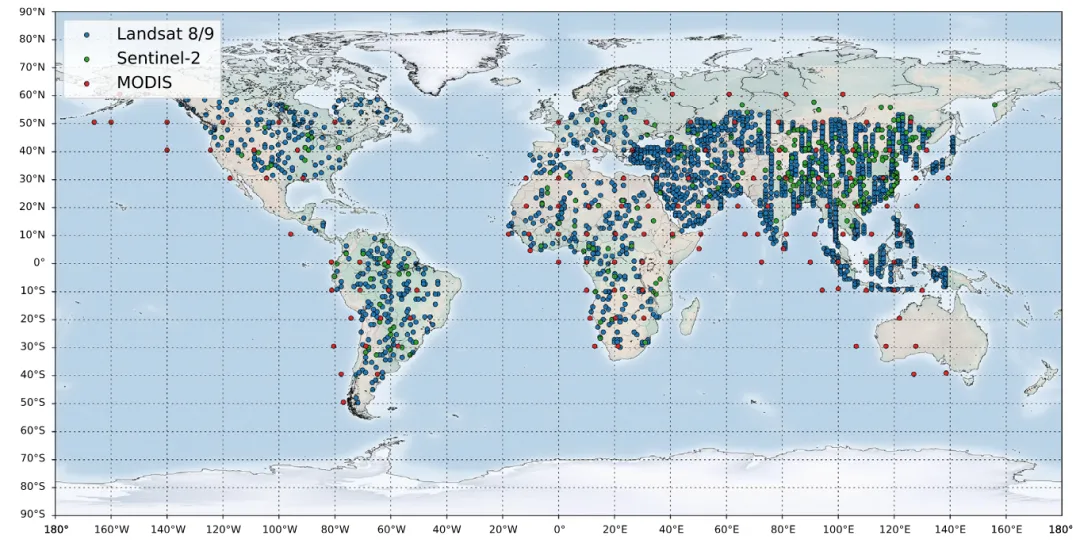
图1 研从全球范围内收集的预训练样本的空间分布,这些样本来源于Sentinel-2、Landsat-8/9和MODIS。
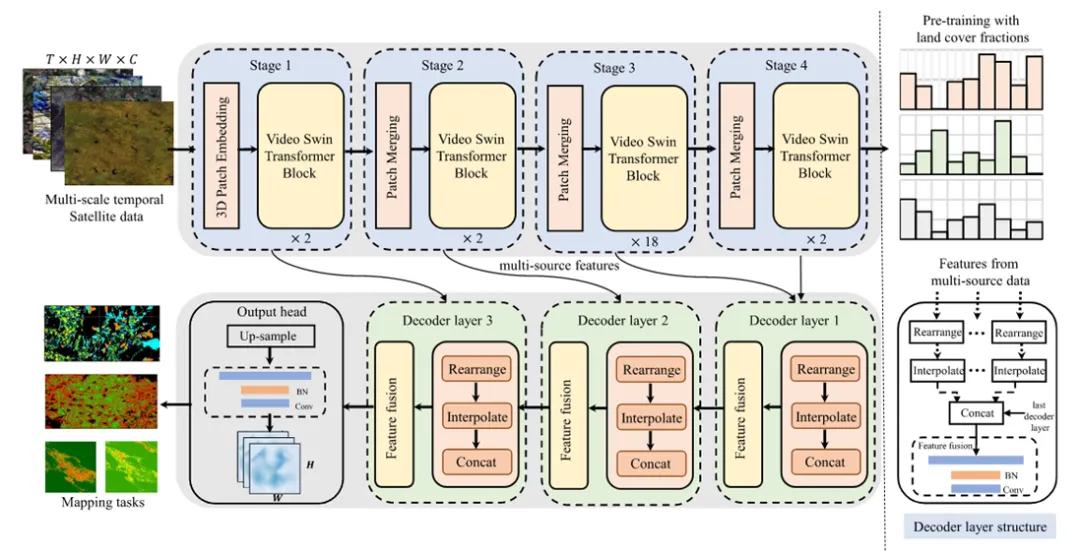
骨干网络:改进的Viedo Swin Transformer
为了避免传统的ViT固定 16×16 大 patch 会造成不可逆的空间细节损失,田块边界容易模糊。作者采用了Video Swin Transformer,层次化特征提取,类似 U-Net/CNN 多尺度结构,更适合像素级农业制图。作者还进行了创新型的改造,时空同步降采样,每次降低空间分辨率时,也合并相邻时间帧,支持 3–32 帧变长输入。这种设计支持可变长度输入,并将计算量(FLOPs)降低 60–70%。
图2 基础模型AgriFM的结构包括四个阶段。输入的卫星序列( MODIS、Landsat - 8 / 9、Sentinel - 2)由特定的量纲参数表征:T表示每个序列(随机选取3 ~ 32帧)的时间长度,W和H表示空间宽度和高度(均固定为224像素)。光谱波段数C根据数据源的不同而不同。解码器的目的是对特征进行上采样和融合,以产生映射结果,每个映射结果由各自的标签标记。
Mean-Teather抗噪声预训练
由于 GLC_FCS30D 产品本身存在分类误差,作者引入 Mean‑Teacher 框架:一个教师网络的参数由学生网络的指数移动平均(EMA)得到,学生不仅学习拟合真实分数,还要与教师网络的输出保持一致。这有效抑制了标签噪声,提升了预训练的稳定性。
多源数据融合
三种数据分辨率和覆盖特性不同,不强制空间对齐,而是让不同传感器分别输入同一模型;以土地覆盖分数作为“语义桥梁”,在特征空间形成一致表征。
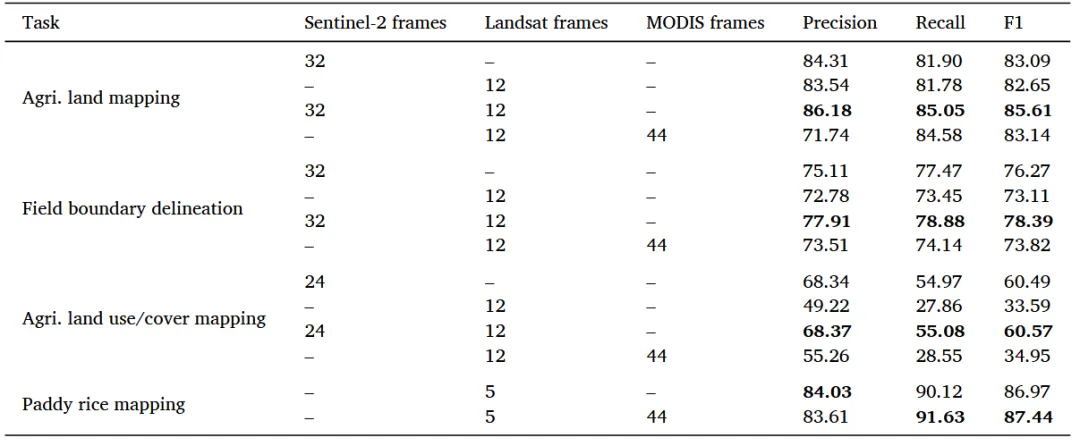
表1 不同卫星数据源在不同空间分辨率( Sentinel-2 : 10m和20m。Landsat 8 / 9 : 30 m ; MODIS : 250 m和500 m)和时间配置下的性能。数据源列中的数字表示时间帧计数。
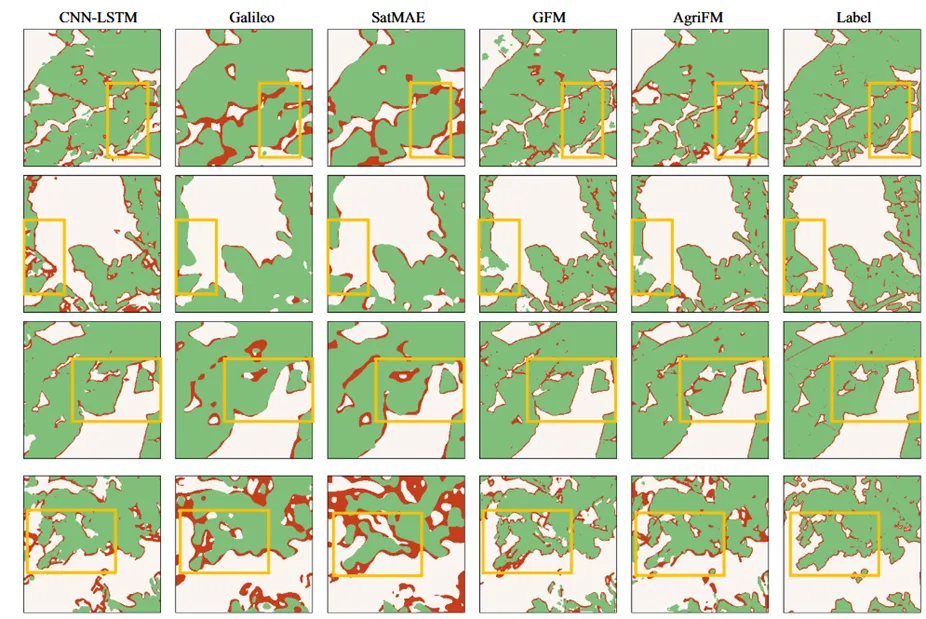
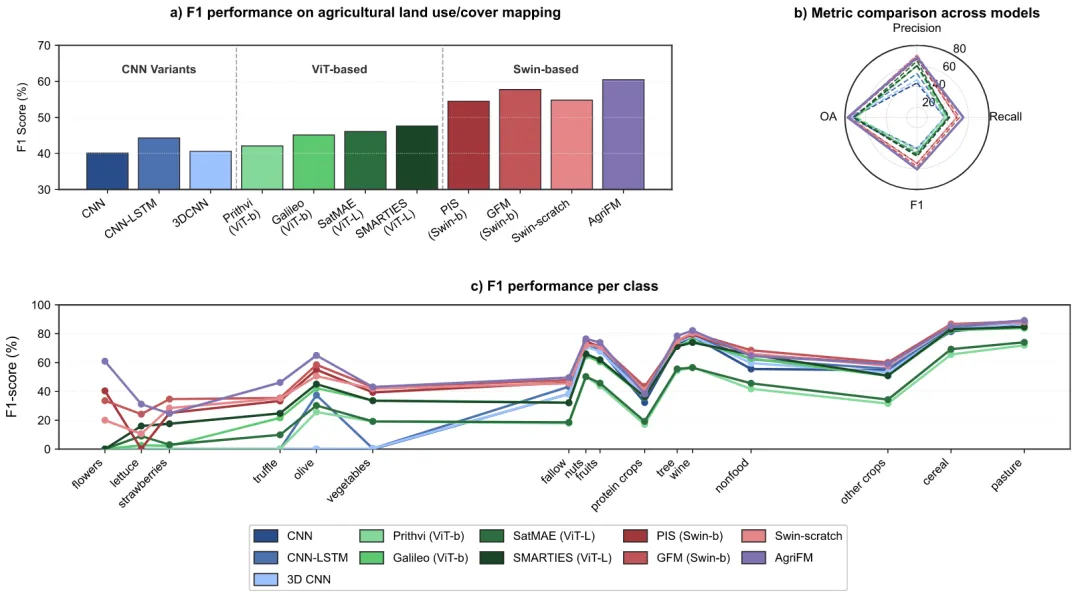
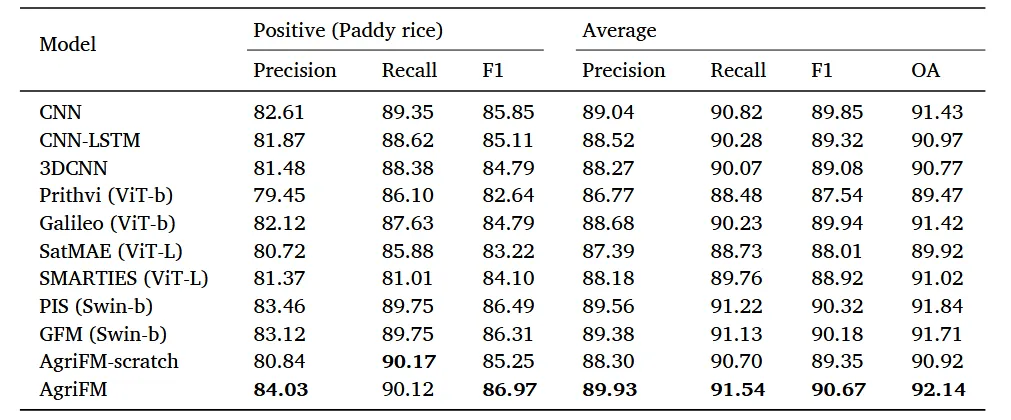
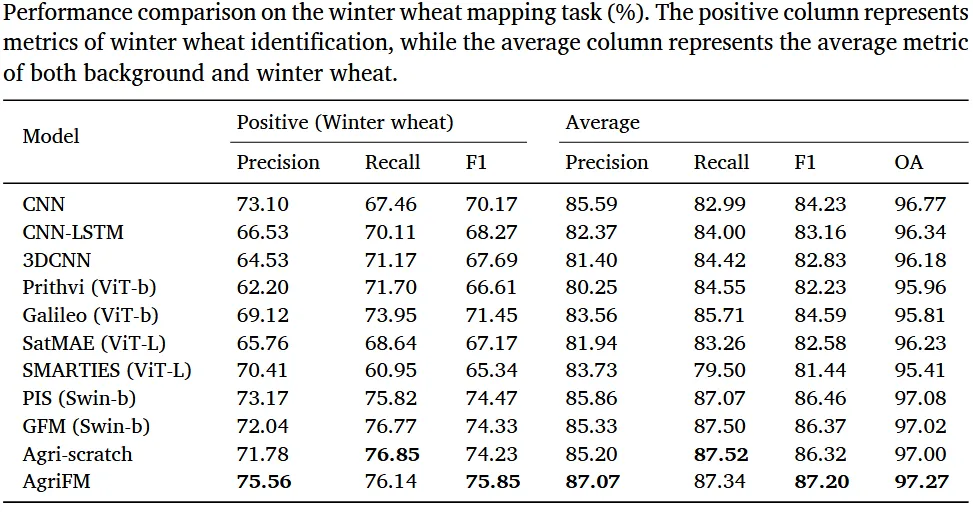
预训练后,一个 U‑Net 风格的解码器从骨干的四个 stage 提取多尺度特征,逐级上采样并拼接,最终输出像素级预测。下游任务包括:农业用地制图(二分类)、地块边界提取(边缘检测)、农业土地利用/覆盖分类(16 类)、水稻制图(亚洲,HLS30+MODIS)、冬小麦制图(亚洲,MODIS)。
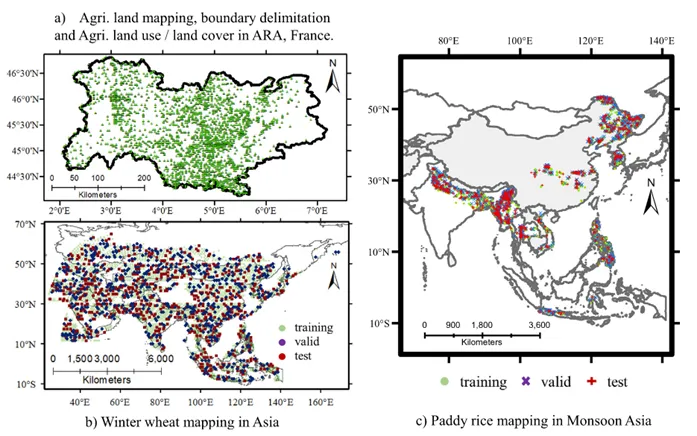
图3 为下游制图任务提供研究区域和数据集的详细信息。






 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
