标题:Untangling multi-species fisheries data with species distribution models
期刊:Reviews in Fish Biology and Fisheries (IF=6.845)
第一作者:Matthew N. McMillan
通讯作者:Matthew N. McMillan
First published:15 May 2024
DOI: 10.1007/s11160-024-09863-1
渔获量的长期变化趋势是监测捕捞对种群的影响的重要依据。渔捞日志的渔获量数据常以多物种合并的形式记录,这给单物种的资源评估带来困难,尤其在非目标物种随着时间推移逐渐成为捕捞的目标物种时,物种水平的渔获量信息变得十分重要。物种分布模型(SDMs)为将聚合的渔获量数据分配到各个物种提供了一种可行的工具,但当前对其利用还不够充分。本研究以摩顿湾的两种龙虾(Thenus australiensis和Thenus parindicus)为例,展示了如何利用物种分布模型拆分聚合的历史渔获量数据,从而获得物种水平的渔获量变化趋势,并识别捕捞目标物种的转移等捕捞行为的变化。本研究将为研究人员和管理人员利用聚合的多物种渔获量数据进行单物种的资源评估提供参考。
渔捞日志是评估捕捞对种群影响的重要数据来源,但其常因各种原因存在缺陷。例如,多物种渔获物被合并记录,使得具有不同生物学和生态学特征的物种难以单独进行评估。这种聚合数据常见于最初作为副渔获物被捕捞,随后因资源变化或市场需求转变而成为目标物种的情况。此外,气候变化也会促使物种分布的变化,进而改变渔业目标物种。当需要对单个物种进行评估时,物种在时空分布上的差异便可用于拆分聚合的渔捞日志数据。
物种分布模型最初用于根据气候、地形等因子预测物种分布,现已广泛应用于资源管理,如预测捕捞目标物种的分布、评估兼捕的风险以及构建丰度指数等方面。但在渔业管理中,利用物种分布模型拆分多物种渔获量数据的应用仍较少。本研究以分布在澳大利亚昆士兰东海岸摩顿湾的两种扁虾属的龙虾(Thenus spp.)为例,展示如何设计和使用物种分布模型对渔获量进行分配。这两种龙虾分别是偏好栖息在岩礁环境中的Thenus australiensis(岩礁性龙虾)和偏好栖息在泥浆底质中的Thenus parindicus(泥底性龙虾),它们分布于澳大利亚北部的亚热带和热带海域,且约80%的渔获量产自昆士兰东海岸的底拖网渔业。1988年至2021年间,该区域的渔捞日志将两种龙虾合并记录为一个多物种混合体。随着近年来市场需求的转变,对两个物种分别开展资源评估已经迫在眉睫。因此,本研究将把聚合的历史渔获记录拆分为物种水平的渔获量数据,以研究两个物种捕捞率的长期变化趋势,并进一步支撑后续的管理决策。
1.模型范围与数据收集
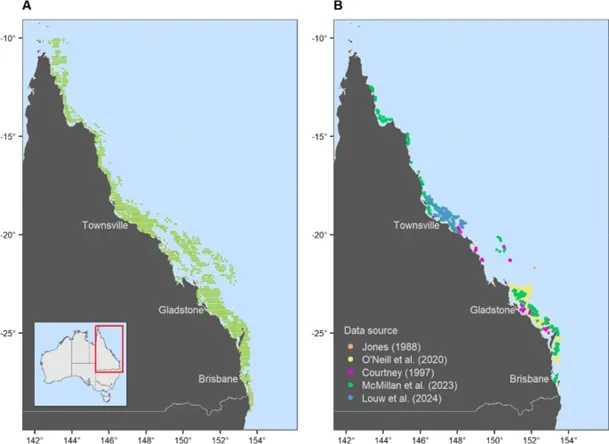
研究以摩顿湾(Moreton Bay)龙虾捕捞记录覆盖的空间范围作为模型的空间域(图1A)。本研究整合了多个来源的数据(图1B),包括:渔业生产监测、物种丰度普查、生物学特性研究以及 “渔民观察员计划”。在“渔民观察员计划”中,渔民在捕捞现场对渔获物进行拍照,通过照片鉴定物种并记录经纬度和时间。为确保数据的可比性,所有调查均在夜间使用相似的底拖网进行,作业的水深为10−80米。
图1. 1988 年至 2021 年摩顿湾龙虾渔获量数据(A)与物种组成数据(B)的空间分布
2.变量选择
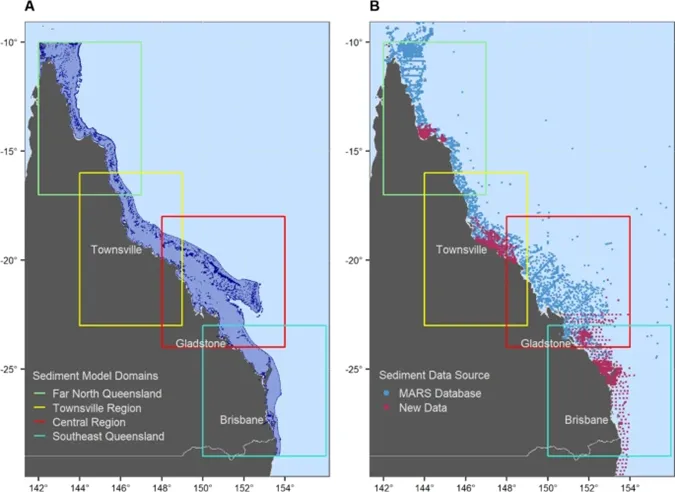
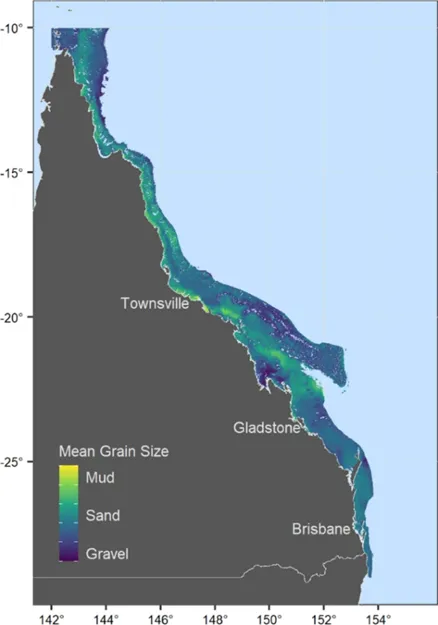
在本研究中,基于栖息地偏好的解释变量被用来模拟物种分布。由于两种龙虾对沉积物粒径有明显的差异化偏好,研究专门对研究区域的沉积物分布进行建模,将其作为比深度和水文学指标更具信息量的变量。此外,为了减少计算负荷,将研究区域分成四个大小相似的子区域(图2A)。然后,将这些子域的数据拼接成整个模型域的沉积物分布的栅格图层。进一步地,本研究结合来自Geoscience Australia的公开数据和项目收集的新数据(图2B),应用随机森林算法,生成高分辨率的沉积物分布图,作为物种分布模型的预测变量(图3)。解释变量包括水深、坡度、与礁石的距离以及水流速度等。
图2. 物种分布模型的空间域及4个子区域(A)及沉积物点数据的空间分布(B)
图3 研究区域内沉积物类型的分布模拟
3.模型构建
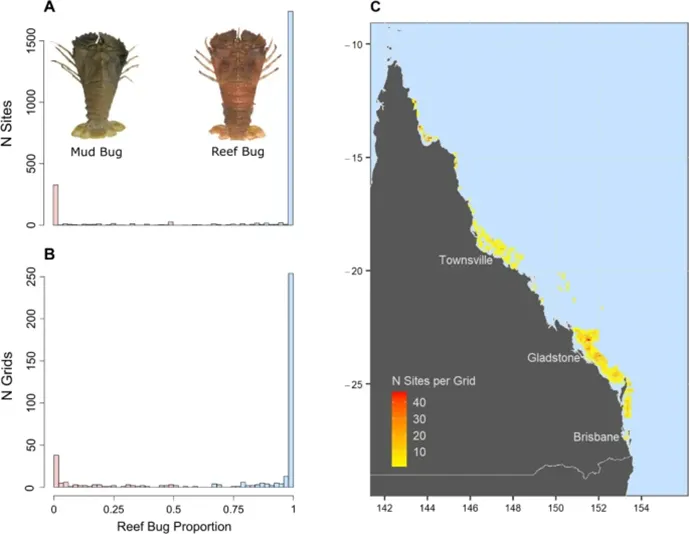
在本研究中,模型的响应变量为每个物种的比例。使用 R 语言软件中的 'gbm' 包中的伯努利提升回归树对二项响应进行建模,提升回归树的数量使用 'dismo' 包中的 k 折交叉验证功能进行优化,每次模型构建中仅使用不共线的变量集。根据每个渔获地点预测的优势物种比例,将1988年至2021年间的渔获量记录拆解,并重新分配到物种水平,以便进行更准确的渔业趋势分析。每个物种的名义单位努力捕捞量渔获量通过将年捕捞量除以渔业中记录的年努力量计算。
图4. 基于采样点(A)和网格数据(B)的物种优势度及训练集数据中每个网格的采样点数量(C)
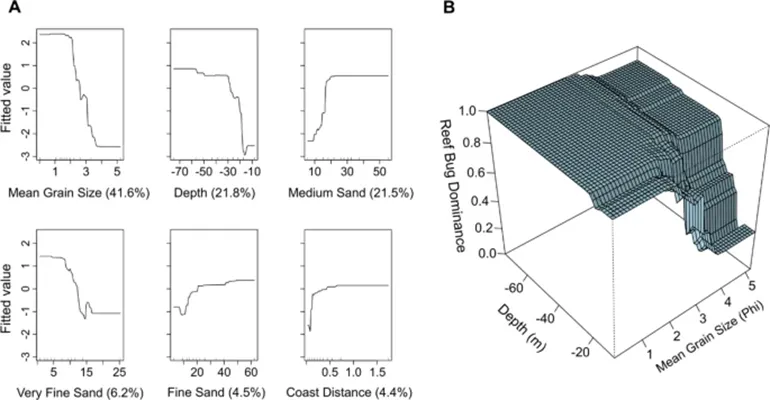
预测物种分布的最佳模型包含 6 个关键解释变量:沉积物平均粒径、水深、沉积物中砂含量、极细砂含量、细砂含量以及离岸距离(图5A)。该模型在解释数据变异方面表现良好,在预测物种优势度时具有极高的准确率,且所需预测变量数量相对较少。
模型拟合函数表明,礁岩性龙虾更可能出现在沉积物粒径较粗、深度较大、离岸距离较远,同时中砂和细砂含量较高、极细砂含量较低的区域(图5A)。此外,平均粒径与水深之间存在明显的交互作用(图5B):在深水且沉积物较粗的环境中,礁岩性龙虾占优势;而在浅水且细粒沉积物的环境中,则主要由泥底性龙虾占优势。
图5. 物种分布模型的预测变量的拟合函数(A)与平均粒径和深度对物种分布的影响的交互作用(B)
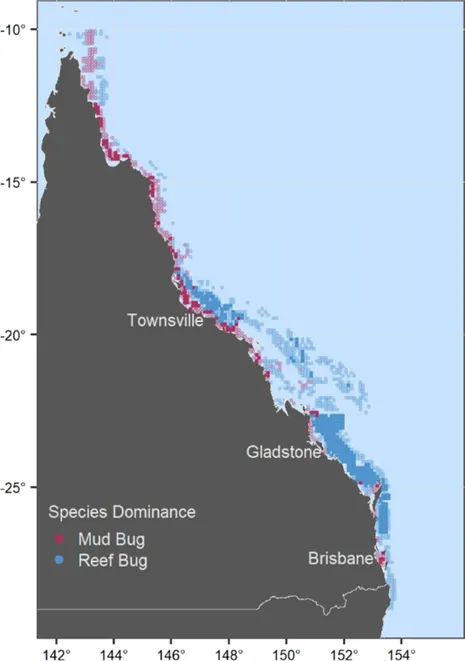
在整个龙虾渔业的范围内,大多数的网格被预测为礁岩性龙虾占优势,这一结果与训练数据中的观察结果以及渔民的实际经验相一致。泥底性龙虾则主要分布在近岸浅水、细粒沉积物占主导的区域(图6)。
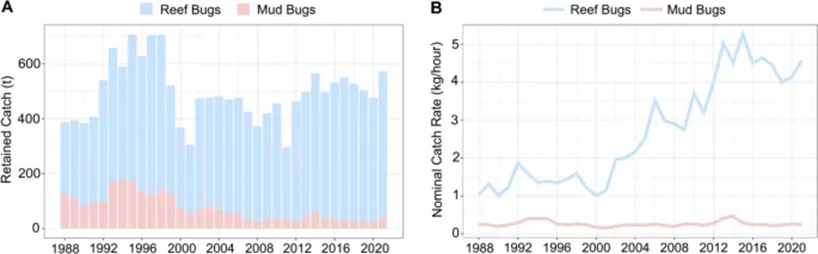
同时,这一方法也首次揭示了该渔业物种组成的长期变化趋势:从 1988 年到 2021 年,礁岩性龙虾在总渔获量中的比例由 67% 增加到 93%(图7A)。同时,名义单位努力捕捞量渔获量的变化表明,自21世纪初以来,礁岩性龙虾的捕捞率显著上升(图7B)。
图7. 1988−2021年摩顿湾龙虾的渔获量在两个物种之间的分配情况(A)与两个物种名义单位捕捞努力量渔获量(B)的变化
在本研究中,由于两种龙虾之间存在明显的栖息地分离,模型能够较为明确地将渔获量的记录归属于对应物种,从而显著提高了模型性能。对于分布存在较大重叠的物种,可以考虑引入时间变量以将季节性变化纳入模型。一些物种具有迁移行为、活动性较强,而另一些物种的栖息地则比较固定,这会导致不同物种的季节性丰度变化。个体发育阶段的栖息地变化也可能影响模型结果,本研究通过仅使用超过最小捕捞规格的龙虾个体作为训练数据,避免了幼体分布对模型的干扰。此外,种群规模变化也可能影响物种分布。当种群规模增长时,个体可能扩展到适宜性略差栖息地;而当种群规模减少时,分布范围可能收缩到核心栖息地。因此,在分析长期数据时,应确保模型的空间范围能够覆盖整个时间序列中的捕捞区域,从而减少种群变化带来的影响。
本研究系统展示了利用物种分布模型拆分聚合的多物种渔获量数据的方法框架。通过整合多来源的调查数据与公开的环境数据,结合机器学习算法,成功将聚合的龙虾渔获量数据分配至物种水平。模型的预测结果验证了物种栖息地偏好的显著差异,并揭示了渔业捕捞的目标物种从泥底性龙虾向礁岩性龙虾的转变,为后续的资源评估提供了重要参考。该方法适用于具有空间分布差异的多物种渔业,尤其当物种栖息地偏好明确时效果更佳。随着公开环境数据的增加与机器学习工具的普及,物种分布模型在聚合的多物种渔业数据的拆分中的应用前景广阔,能够为渔业资源的精细化和适应性管理提供技术支撑。
编辑 |徐俊伟 李姗霖
审核 |张崇良
排版 |宗铭妍