近日,中国农业大学农学院汪海团队在植物学权威期刊《Nature Plants》在线发表了题为“Deep learning-based semantic matching of cis-regulatory DNA sequences facilitates the prediction of gene function”的重要研究成果,这是我国基因组人工智能领域首篇Nature Plants。该研究开发了深度学习模型PhytoBabel,首次实现了极远缘物种(如分化1亿6千万年的单子叶与双子叶植物)转录调控DNA序列的语义匹配,用于转录调控区关键碱基发掘、跨物种知识迁移和基因功能预测;作为该模型的一个应用案例,研究者利用PhytoBabel模型在玉米中预测了多个全新的形态发生调控因子,并实验验证了它们在玉米体细胞胚胎发生中的关键功能。该研究打通了“转录调控序列→语义→基因功能”的推断链条,为反向遗传学提供了新的跨物种知识迁移工具(https://doi.org/10.1038/s41477-026-02231-w)。
解析基因功能是遗传学和基因组学的重要目标。但在许多物种中,通过遗传、生化和生理学实验获得功能解析的基因比例很低。例如,玉米中仅有0.5%的基因获得功能解析,拟南芥中这一比例为28%。即使是大肠杆菌和酿酒酵母模式种,也仍然存在大量功能未知的基因。随着基因编辑技术的普及,反向遗传学成为新基因发掘的主要手段。推测一个基因所编码的蛋白质生化功能,往往通过将其与已知生化功能的蛋白质进行序列或结构相似性比对,从而实现知识迁移。然而,如何准确地预测基因的生理功能,为实验验证提供候选基因,仍然充满挑战。
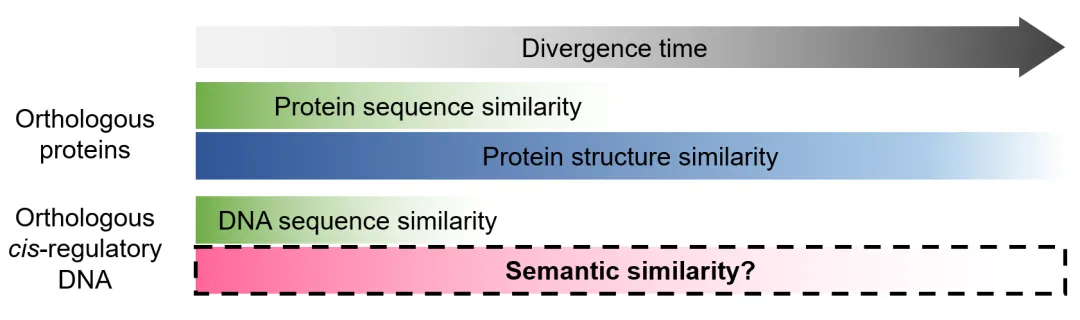
本文的故事开端于一个人们早已习以为常到视而不见的现象:转录调控区DNA序列的进化速度远快于蛋白质序列的进化速度。在双子叶和单子叶植物之间,直系同源基因历经1亿6千万年的分化,蛋白质序列仍然高度相似,但它们的转录调控区DNA序列已沧海桑田面目全非,无法进行全局或局部对位排列。因此,本研究提出一个假设:尽管直系同源基因的转录调控区在DNA序列层面已不相似,但序列所承载的“语义”可能仍然保留。这类似于在直系同源蛋白质的分化历程中,蛋白质“三维构象相似性”比“序列相似性”可以保留更长的时间。
图 1 直系同源的转录调控区DNA序列在进化中逐渐失去序列相似性(较快)和语义相似性(较慢),类似于直系同源蛋白质在进化中逐渐失去序列相似性(较快)和结构相似性(较慢)。
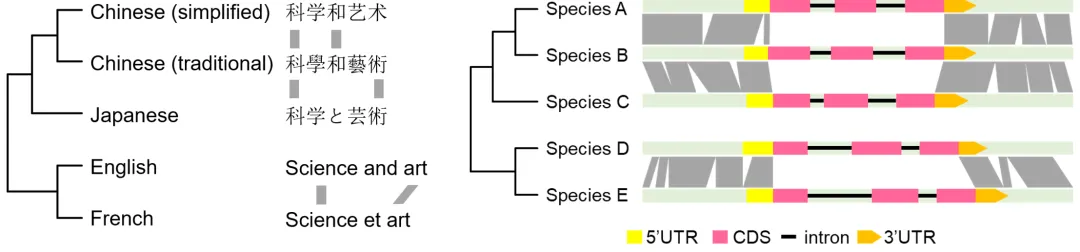
另一个类比是人类的语言:关系密切的语言之间可以对位排列,而关系疏远的语言之间不存在相同的字符,只能互相语义翻译。那么,极远缘直系同源基因的转录调控序列是否具有语义相似性,这种相似性又该如何解析呢?作者从大语言模型中寻找灵感。
图 2 与人类语言相似,进化会抹去转录调控区DNA序列的序列相似性。
大语言模型是如何学习人类语言的?人工神经网络和人脑一样,针对不同的学习任务,需要探索最合适的学习方式。最常用的学习方式是“基于掩码的自监督学习”,即随机遮掩句子中的一些词语,让模型根据上下文预测这些被遮挡的词语,类似于小学生语文考试中的填字题(如下图所示)。这种学习方式似乎非常“反直觉”。想象让一个人类婴儿出生后不接触真实世界,只看填空题,训练几个月后,在人类所有学科达到博士水平!该训练方式是否有助于通往AGI (人工通用智能,即与人类相当或超越人类的触类旁通能力) 仍然存在巨大争议,但近几年大语言模型的飞速发展证明了它的有效性:语料无需大规模人工标注(省钱省力),可以最大限度利用人类千百年来积累的海量语料,模型被迫学习数据中潜在的结构和上下文关系,为后续在特定任务上进行微调提供了一个非常好的起点。
图 3 基于掩码的自监督学习类似于小学生语文考试中的填字题。
但是,上述基于掩码的自监督训练方式对转录调控DNA序列难以取得较好的效果。这是因为转录调控DNA和人类语言相比,“废话”较多,位置熵(Positional Entropy)较高。人类语句中,改一个字往往会破坏其含义;而转录调控DNA序列被大自然设计成了“打不垮炸不烂”的鲁棒风格,可以承受较多碱基的改变却基本维持其表达量和时空特异性。因此,如果对转录调控序列做基于掩码的自监督学习,模型在大多数情况下面临“预测成什么碱基都对”的局面,难以学到有效信息。当然,人类语言中偶尔也会出现特例----如果让模型对《玛卡巴卡之歌》做掩码预测:“玛卡巴卡阿卡哇卡米卡玛卡嗯,玛卡巴卡阿巴雅卡伊卡阿卡噢”。模型:心态崩了!
图 4 生命以负熵为食,通过摄取负熵对抗熵增定律。但是高等生物转录调控区DNA序列的功能约束(functional constraint)甚至弱于《玛卡巴卡之歌》,以维持其功能鲁棒性。
第二种学习方式是依赖于外界标注的监督学习。例如,在一个在线影视网站上,用户可以对电影写下点评文字,并给出打分。如果将打分作为点评的标签,可以训练一个以点评文字为输入、以打分为输出的语言模型。与此相似,在生物学中,一段DNA序列往往拥有很多标签,例如基因结构注释信息或基因表达量、表观遗传标记、染色质可及性、转录因子结合等注释信息(统称为分子表型)。一个基因组DNA变异,如果影响人类疾病表型或作物田间性状,必然首先影响某种分子表型。训练一个以DNA序列为输入,以上述标签为输出的模型,可以帮助我们预测基因组DNA变异的分子表型效应,进而预测其在人类基因组中的致病性或对作物田间表型的效应以及可能的分子机制。但是在植物中缺乏人类ENCODE计划那样包罗万象的高质量分子表型数据,因此这种训练方法在植物中的应用较为受限。
人工智能实际上还有另一种(也是最不常用的)学习人类语言的方式:语义配对。在这种方式中,将大量来自不同语言的成对的句子输入模型,让模型预测两句话是否具有相同的含义。这种训练方式受限于语料太少(双语读物比单语读物少几个数量级),且翻译家往往倾向于“信达雅”的意译,而不是严格的逐词逐句翻译。实际上,只有宗教经典(如《圣经》)是逐词逐句翻译的。但是,对于生命之树上的无数物种,如果我们把每个物种的基因组想象成一门语言,把“直系同源基因对”的调控区DNA序列想象成“语义相同”的句子,“语义配对”的语料则十分丰富,足以训练深度学习模型。
从另一个角度看,这种训练方法和对比学习 (contrastive learning) 在底层逻辑上有异曲同工之妙。用一个例子解释对比学习的基本思想:将同一张图片经过不同“数据增强”(如裁剪、翻转、颜色调整)得到的两个版本视为“正样本对”。将来自不同图片的样本视为“负样本对”。目标是让神经网络模型学习到的表征(representation)能够使得正样本对在特征空间中尽可能接近,而负样本对尽可能远离,迫使模型学习到对各种扰动不变的关键视觉特征。在本研究中,大自然亿万年的沧桑变迁在DNA上留下的变异构成了“数据增强”。
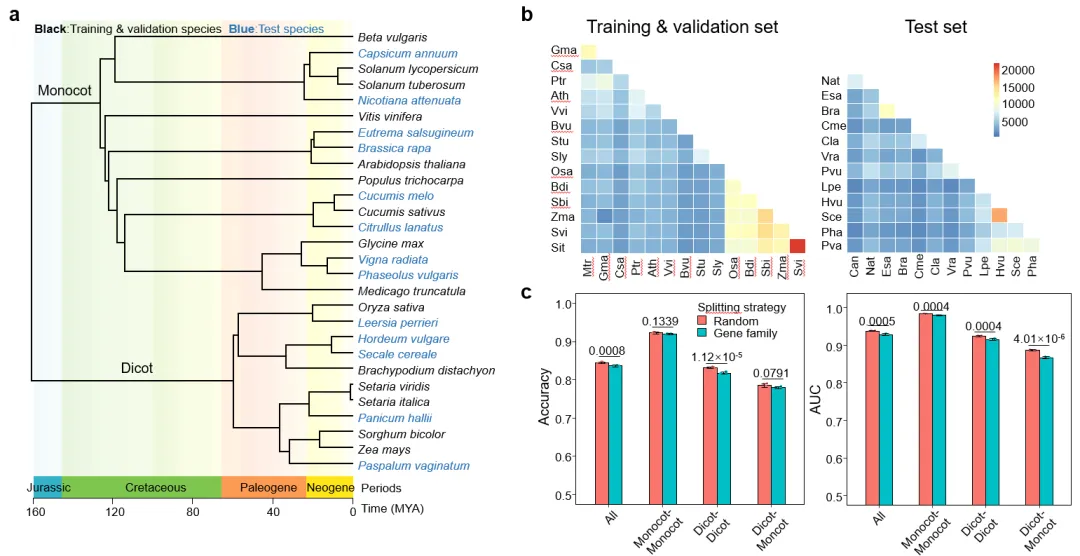
基于这一思路,研究团队选取了15个具有高质量基因组的植物物种(9个双子叶和6个单子叶物种)的52万对RBH(reciprocal best hit)基因对,提取其转录调控序列用于训练和验证模型,使用额外的13个物种(8个双子叶和5个单子叶物种)的30万对RBH基因对,提取其转录调控序列作为测试集,测试模型的准确度。该模型命名为PhytoBabel,该名字来源自《圣经·旧约·创世记》中巴别塔(Babel Tower)的故事:人类联合起来兴建希望能通往天堂的高塔;为了阻止人类的计划,上帝让人类说不同的语言,使人类相互之间不能沟通,计划因此失败,人类自此各散东西。这一故事和植物登陆后的扩散和物种分化有内在相似性。
在模型架构创新方面,本研究开发了共享权重的残差网络处理每条序列及其物种信息,再通过注意力机制评估序列间的语义相似性。研究人员测试了大量的模型架构相关参数的组合,最终确定了最适合本任务的架构。模型架构设计和优化过程十分关键,正如美国作家弗兰克·赫伯特在他的史诗级科幻巨著《沙丘》中所指出的--“Many have remarked the speed with which Muad'Dib learned the necessities of Arrakis ... we can say that Muad'Dib learned rapidly because his first training was in how to learn”。
图 6 PhytoBabel模型成功实现远缘物种调控区对应关系预测。
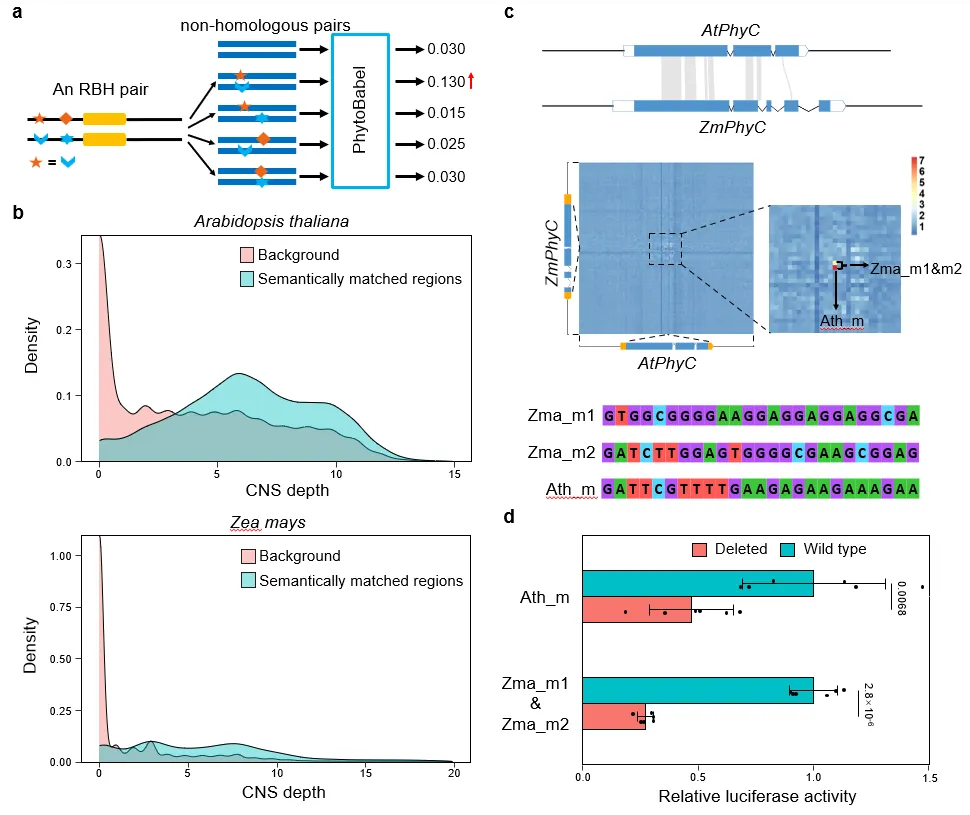
研究人员进一步利用上述PhytoBabel模型寻找“极远缘直系同源”序列间语义相同但序列不同的碱基。这些转录调控碱基体现了过去1.6亿年间转录因子和基因组结合位点的共进化,同时也是未来基因编辑改良的重要靶点。研究人员开发了虚拟DNA短片段替换的算法,该算法在拟南芥-水稻和拟南芥-玉米直系同源序列对中分别鉴定出40,197和38,640对25bp的语义匹配片段。这些片段主要位于启动子和UTR区域,并显著富集已知的转录因子结合基序。对随机挑选的20对语义对应片段进行实验验证,发现这些在短片段在敲除后均能显著影响调控区表达强度,且强度变化方向几乎一致,支持PhytoBabel模型“语义配对”的预测。
图 7 PhytoBabel成功识别功能相关的短调控片段。
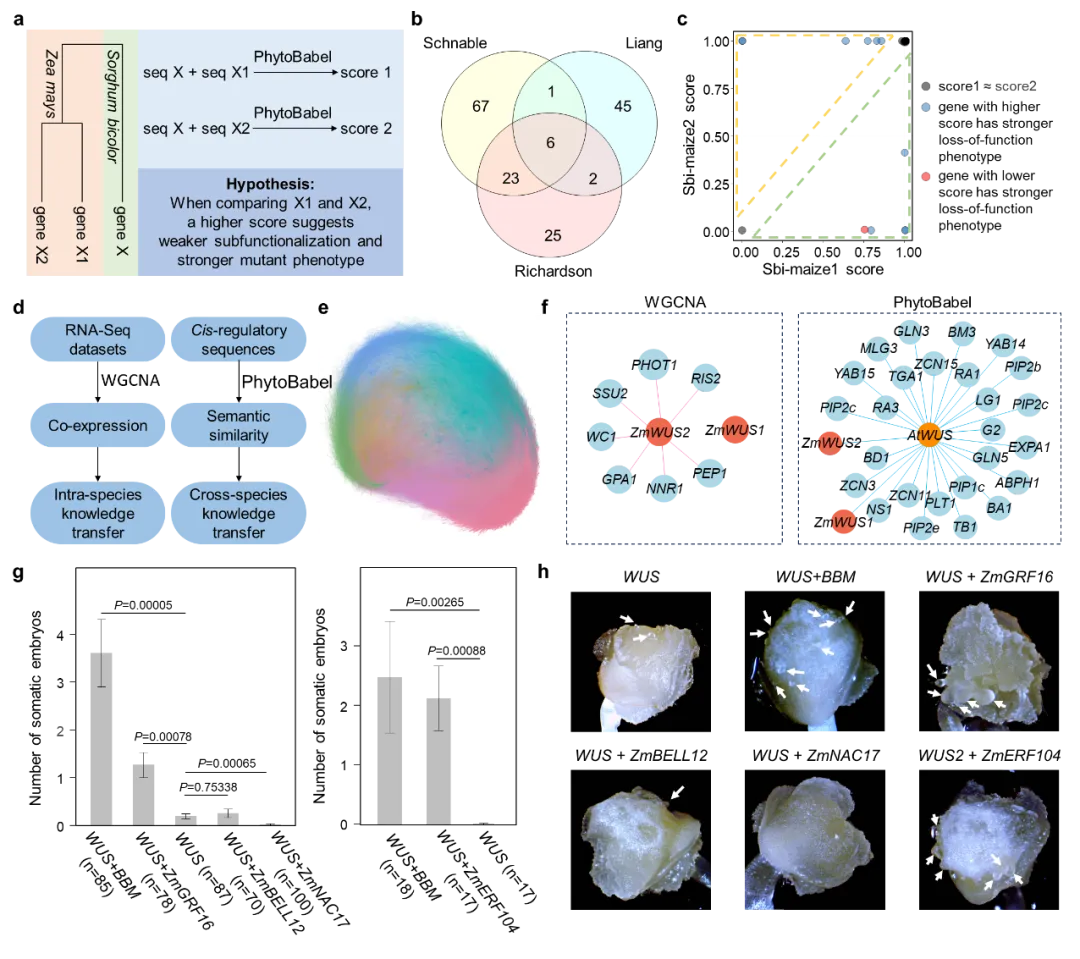
最后,回到本文开头提到的基因功能预测的话题。转录调控区的语义相似性是否预示着基因功能相关呢?研究人员猜测,PhytoBabel的“假阳性”预测(将“非同源”调控序列预测为“直系同源”)可能体现了两个非同源基因在功能上的相关性(如参与同一生物学过程)。基于该猜想,研究团队构建了拟南芥与玉米间的“语义配对”网络,发现该网络成功将许多参与相同生物学过程的非同源基因连接到了一起。以拟南芥形态发生因子基因(可以将体细胞转变为干细胞)为例,PhytoBabel不仅成功识别其玉米直系同源基因,还预测出玉米中多个属于其他转录因子家族的已知的细胞命运决定因子,以及一些功能未知的转录因子。对其中4个功能未知的转录因子进行实验验证,发现ZmGRF16和ZmERF104在与WUS共转化后均显著提高了体细胞胚产生效率,而ZmNAC17明显抑制体细胞胚形成。这三个转录因子均无法通过传统的蛋白同源性或共表达网络分析找到。实际上,在共表达网络分析中,两个基因是否共表达受到分析所选取的转录组样品的影响,缺乏客观性。上述实验结果验证了PhytoBabel在基因功能预测和跨物种知识迁移中的优异表现和独特优势。
图 8 PhytoBabel的“假阳性”预测(将“非同源”调控序列预测为“直系同源”)体现了两个来自不同物种的非同源基因在功能上的相关性。
中国农业大学博士研究生 李天祎、许辉、索明锐 和 徐铭池 为共同第一作者,汪海 教授为通讯作者。该研究得到了国家重点研发计划青年科学家项目(2022YFD1201100)、中央高校建设世界一流大学(学科)和特色发展引导专项资金(2025AC030)以及中国农业大学2115培育工程支持。
博士生李天祎承担了本研究的模型构建和算法开发工作,2017.9-2021.6就读于中国农业大学农学院农学专业,获农学及经济学学士学位;2021.9-2026.6于中国农业大学农学院作物遗传育种专业硕博连读(2022年硕转博),即将于2026年6月博士毕业;目前已提交发明专利申请2项、获软件著作权5项,以第一作者身份在国际顶尖期刊PNAS及Nature Plants上发表文章;2025年在长三角作物学博士生论坛获优秀报告一等奖,首都高校大学生学术年会获最佳报告奖,连续荣获2023-2024、2024-2025国家奖学金。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
