🌐 文献导览
题目:A machine learning scheme for estimating fine-resolution grassland aboveground biomass over China with Sentinel-1/2 satellite images
作者:Huaqiang Li, Fei Li, Jingfeng Xiao, Jiquan Chen, Kejian Lin, Gang Bao, Aijun Liu, Guo Wei
期刊:Remote Sensing of Environment
中科院分区:1区
发布日期:2024年7月16日
DOI:10.1016/j.rse.2024.114317
论文封面
摘要:从样地水平升尺度到广域范围的草地地上生物量(AGB)估算缺乏跨草地生物群落的外推鲁棒性。这是因为多样化驱动变量与模型形式之间的耦合关系尚未被充分理解或稳健定义。本研究利用17421个地面实测AGB样本和由Sentinel-1/2卫星影像及气候-地形-土壤数据生成的31个驱动变量,探讨了中国18种草地类型中这些多维度驱动变量与6种机器学习算法在AGB升尺度估算中的耦合关系。蒙特卡洛模拟表明,这31个多维度驱动变量并未增强ML算法在AGB建模中的性能;10 km分辨率的气候因子(尤其是年均降水量MAP)和10 m分辨率的卫星增强植被指数(EVI)具有尺度效应——前者主导18种草地类型间AGB的变化,后者反映局部异质性。ML算法普遍存在饱和收敛现象,训练样本代表性不足会导致在特定草地类型约束下ML建模的不稳定性。在6种ML算法中,随机森林(RF)在迭代训练中的平均绝对误差(MAE)方面优于其他方法,但其最佳性能强烈依赖于饱和训练,全中国所有草地的R²为0.68。最后,基于RF的最优草地AGB估算(0.25 Pg C)、由18种草地类型的根冠比(R/S)推断的地下生物量(1.52 Pg C)以及牲畜的大致采食量(0.02 Pg C),中国草地的植物碳储量估计为1.79 Pg C。
📡 研究背景
草地生物量,定义为植物地上生物量(AGB)和地下根系,是草地生态系统碳储量的重要组成部分,也是牲畜的饲料来源。然而,物种结构和组成的巨大差异为表征大范围内生物量的固有变化带来了挑战。通过利用植物叶绿素和含水量等生物学特征的电磁响应,卫星指标的数学建模已被提出作为解决采样代表性不足问题的关键方法,可产生连续的生物量空间估算。然而,卫星指标不仅与植物生物学特征相互作用,还受到大气效应、太阳-目标-传感器几何条件以及物种结构和组成变化的严重影响,导致建模能力受限。
研究显示,降水量可以解释AGB变化的很大比例——全球为56%,北美大草原为39-45%,欧亚草原为71-88%。卫星指标的光学特性仅能部分捕捉AGB与环境因子之间的耦合关系,并且因其无法检测垂直分层结构而受到批评。合成孔径雷达(SAR)卫星数据因其波长和对垂直结构及植物密集冠层的敏感性,被认为能够克服这些局限性。然而,针对草地生物群落开展的SAR研究仍然有限。
一些研究者整合了卫星指标和气候-地形-土壤变量来建立高维驱动变量,已显示出对AGB变化的强大预测能力(约70%),而单因子AGB模型仅能解释15-49%。然而,由于多样化驱动变量的相互作用以及物种结构和组成的异质性,模型形式和参数变化很大,这阻碍了生物过程的底层联系,妨碍了我们在更大尺度上准确估算草地生物量。机器学习(ML)方法在处理高维和共线性变量方面展现出高通量建模能力,但ML算法也因代理变量代表性不足而容易受到不饱和训练的影响,并倾向于陷入局部解,导致模型不鲁棒或过拟合。
本研究利用Sentinel-1/2卫星影像和气候-地形-土壤数据,汇编了31个驱动变量和17421个地面实测AGB样本,使用ML算法验证草地AGB与多维度驱动变量之间的耦合关系。研究关注三个核心问题:(1)分辨率从10 m到10 km的多样化和共线驱动变量如何影响ML算法在AGB建模中的性能?(2)ML算法的不饱和训练如何影响18种草地类型间AGB建模的鲁棒性?(3)如何利用上述ML升尺度方案研究中国草地的植物碳储量状况?
🌍 主要方法
1. 研究区域
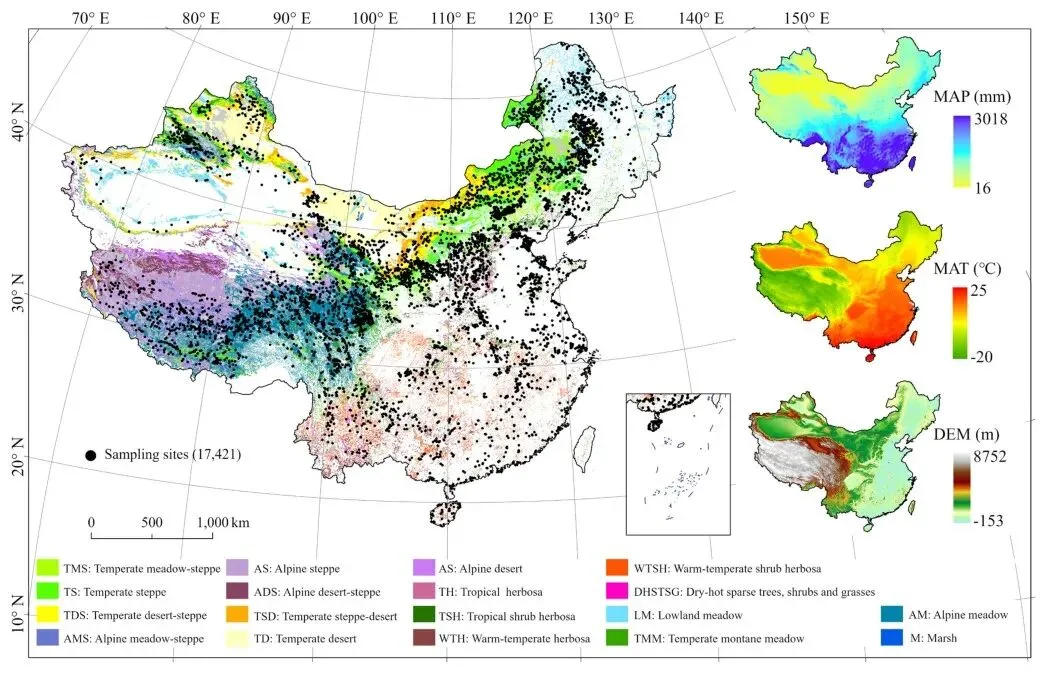
本研究覆盖中国草地,面积约为420万平方公里,占中国陆地面积的41.4%。基于气候带的水热特性和植物特征,中国草地生物群落被划分为18个类别,从北方干旱半干旱地区的温带草地到青藏高原的高山草地,平均海拔分别为1.6 km和4.7 km。年均降水量(MAP)变化范围为20-2500 mm,年均温度(MAT)分别为5°C和-2°C。
2. 机器学习建模方案
草地AGB最初使用6种ML算法进行建模,驱动变量包括4个气候因子、4个气候因子距平值(CFA)、3个地形因子、3个土壤属性、2个雷达后向散射系数(RBC)和15个光学指标,统一到10 m分辨率以匹配Sentinel光学影像。基于随机森林的MDI方法用于检验31个驱动变量的重要性。使用Scikit-learn 1.3在Python 3.9中构建ML模型。6种ML算法包括:多元线性回归(MLR)、支持向量机(SVM)、多层感知机(MLP)、弹性网络回归(EN)、直方图梯度提升回归器(HGBR)和随机森林(RF)。采用留出法进行模型评估:70%的样本划分为5个等量子集用于模型训练,剩余30%作为独立测试数据。
3. 蒙特卡洛模拟
采用由31个变量的多样化组合驱动的蒙特卡洛模拟来评估ML算法的性能。变量组合实验首先在每个类别内执行,共产生10047个组合,包括气候因子和CFA的30个组合、地形因子和土壤属性的14个组合、2个RBC的3个组合以及15个卫星光学指标的10000个随机选择组合。基于最小MAE损失,选择每个类别的最优驱动变量组合,在类别间层面生成最终的63个组合。
4. 全国草地生物量估算
通过考虑地上生物量、地下根系和牲畜采食量来估算中国草地总生物量。地上生物量由上述ML方案估算,地下生物量由网格化AGB结合18种草地类型的根冠比(R/S)推断。牲畜采食量基于每羊单位日干草需求量(1.8 kg/羊单位)、放牧天数(6-9月)和总牲畜数量(羊单位)近似计算。为与以往研究进行比较,总草地生物量以碳(C)单位计量,将干重乘以0.45。
🌍 数据来源
1. Sentinel-1/2卫星数据
●光学影像(Sentinel 2A/2B):2020年生长季高峰期共8274幅正射校正Level-2A反射率影像,用于生成15个光学指标;包括4个10 m波段(蓝、绿、红、近红外)和6个20 m波段(红边1-4、短波红外1-2);云覆盖率阈值小于20%;使用2019年(838幅)和2021年(964幅)影像填补2020年因云污染导致的数据空缺
●雷达数据(Sentinel 1A/1B):C波段双极化合成孔径雷达数据,使用VV和VH后向散射2个极化通道,空间分辨率10 m,时间范围2020年
2. 气候数据
●ERA5-Land月均数据:2001-2020年,空间分辨率0.1°(约10 km),数据来源为Copernicus气候变化服务(C3S)/欧洲中期天气预报中心(ECMWF);包含月均降水量、温度、露点温度和地表净太阳辐射
● 由此计算2001-2020年的MAP、MAT、平均VPD和平均SSR,以及2020年相对于20年均值的距平值
3. 地形和土壤数据
●地形数据:空间分辨率30 m,数据来源为NASA,通过Google Earth Engine(GEE)平台计算海拔(Ele)、坡度和坡向
●土壤数据(SoilGrids250m 2.0):空间分辨率250 m,数据来源为国际土壤参考和信息中心(ISRIC),2021年发布;包含0-30 cm深度的土壤有机碳(SOC)、粘粒含量(CC)和全氮(N)
4. 地面实测数据
●AGB地面实测样本:来源于2020年全国草地资源调查(国家林业和草原局),共17421个野外样地,采样时间为生长季高峰期(7-8月);通过收获植物地上部分并烘干测定干重;样地面积误差控制小于1%,AGB测量误差小于10%
5. 其他辅助数据
●牲畜统计数据:来源于2020年中国统计年鉴,包含牛、羊、马、骆驼和驴的数量,按农业行业标准NY/T 635-2015转换为羊单位
●草地类型矢量数据:18种草地类型1:100万比例尺shapefile数据(Su, 1996);各草地类型的根冠比(R/S)数据(Piao et al., 2004)
🔍 研究结果
1. 驱动变量的重要性分析
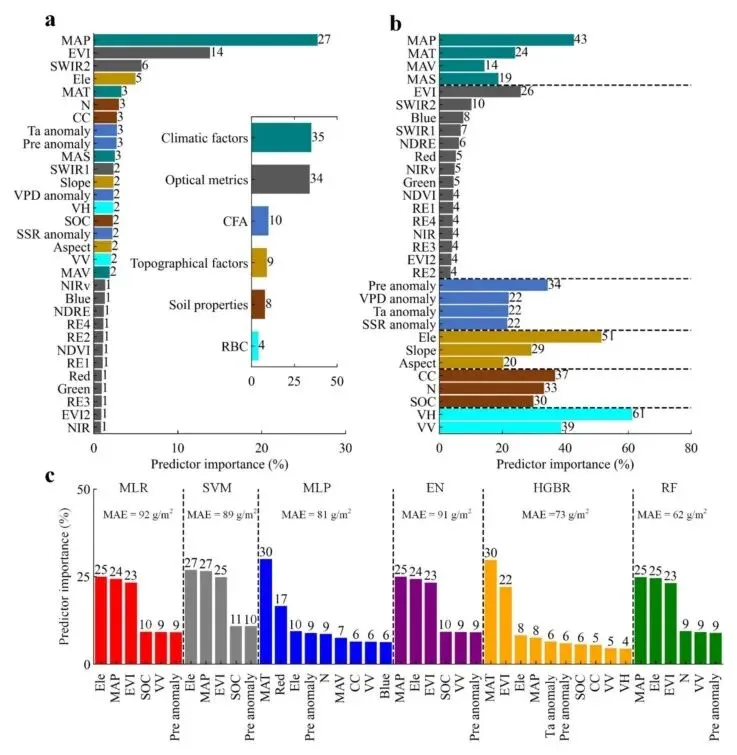
基于随机森林的MDI重要性评级,在31个驱动变量中,气候因子和光学指标在AGB估算中表现出最大的重要性,共同贡献了69%,而气候因子距平值(CFA)、地形因子、土壤属性和雷达后向散射系数(RBC)的贡献均不超过10%。值得注意的是,在31个驱动变量中,年均降水量(MAP,27%)和增强植被指数(EVI,14%)表现出突出的重要性,共同贡献了约41%的空间AGB变化。对于其余驱动变量,海拔(Ele)具有相对较高的重要性评级(5%)。
基于每个特定类别内预测因子的重要性评级,MAP、EVI、Ele和VH保持了稳健的贡献,重要性值分别为43%、26%、51%和61%,而温度距平值和全氮的重要性评级有所下降。在蒙特卡洛模拟中,气候因子和光学指标对6种ML模型的AGB估算贡献均超过24%和22%,而CFA、土壤属性和RBC的贡献较小(小于15%)。总体而言,MAP(25%)、EVI(23%)和Ele(25%)的联合贡献超过了70%,但在MLP和HGBR模型中,MAT具有最高评级。上述结果表明MAP、EVI和Ele对AGB建模具有稳健的贡献。
图1 中国18种草地类型及地面实测样本分布(左图),右图展示年均降水量、年均温度和数字高程模型描述的环境条件(原文Fig. 1)
图2 草地AGB空间变化建模的预测因子重要性。(a)6个类别31个驱动变量的重要性,(b)各类别内部的重要性,以及(c)蒙特卡洛模拟中6种ML算法的最小MAE损失和预测因子重要性(原文Fig. 2)
2. 机器学习模型的性能对比
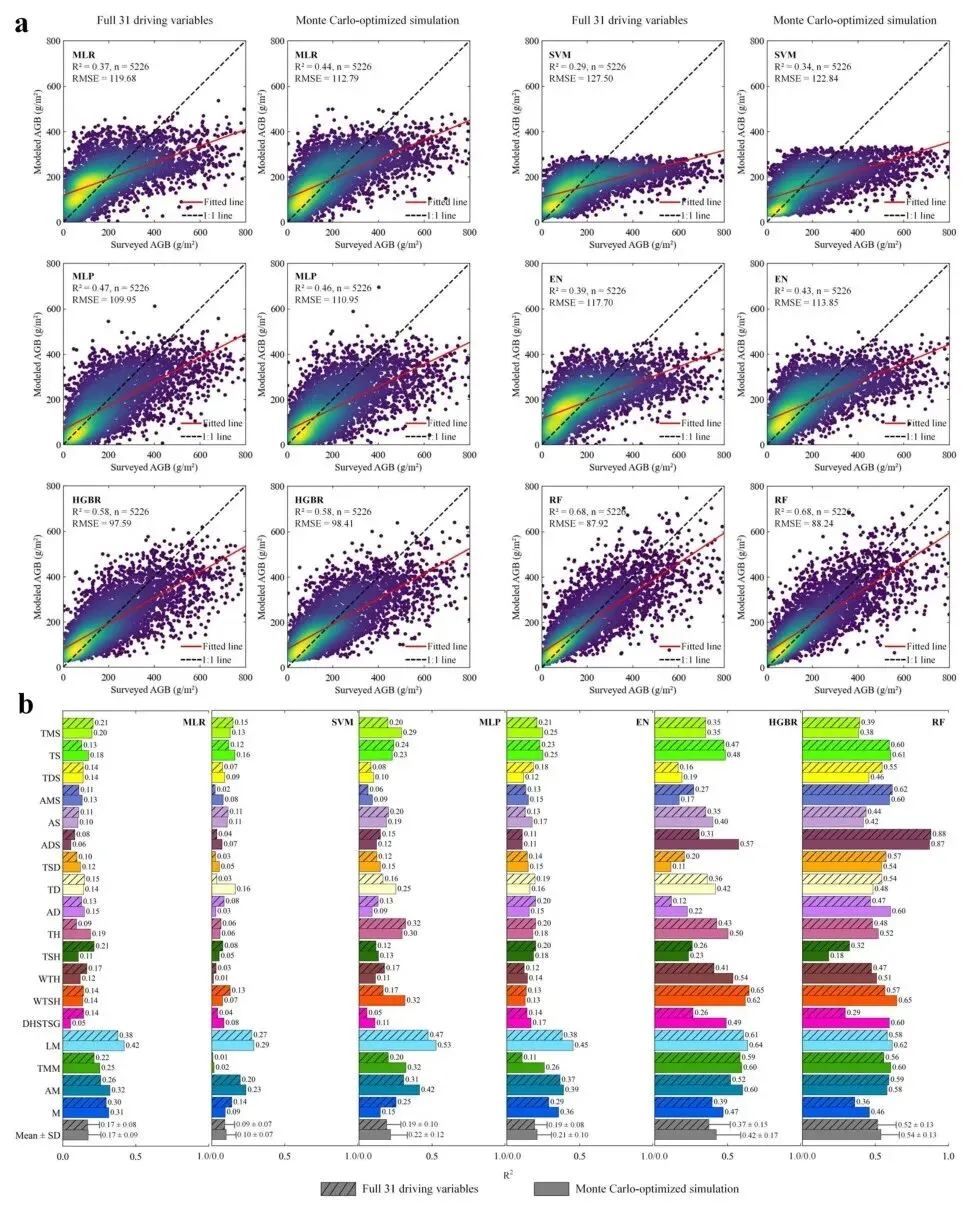
总体而言,6种ML模型的预测精度表现出较大差异,R²范围为0.29(SVM)到0.68(RF)。与31变量驱动的结果(平均R²=0.46)相比,蒙特卡洛模拟表现出几乎相同的性能,平均R²为0.49。具体而言,MLP、HGBR和RF具有稳健的预测精度,其中RF达到最高的R²值0.68。然而,研究发现MLR、SVM和EN建模的AGB始终被低估,而蒙特卡洛模拟部分减少了系统性偏差并提高了预测精度。
根据对18种草地类型的独立验证,蒙特卡洛模拟取得了比31个驱动变量更高的预测精度,平均R²从0.25提高到0.28。总体而言,MLR、SVM、MLP和EN在18种草地类型中表现出较低且不稳定的预测精度,平均R²≤0.22,标准偏差≥0.07,而HGBR和RF模型表现更好,平均R²分别为0.42和0.54。蒙特卡洛模拟表明,31个驱动变量并未改善ML算法的AGB建模性能。
图3 使用31个驱动变量和蒙特卡洛优化模拟,6种ML模型与地面实测AGB的对比。(a)全中国的留出验证,(b)18种草地类型间的R²变化(原文Fig. 3)
3. 中国草地AGB的空间分布格局
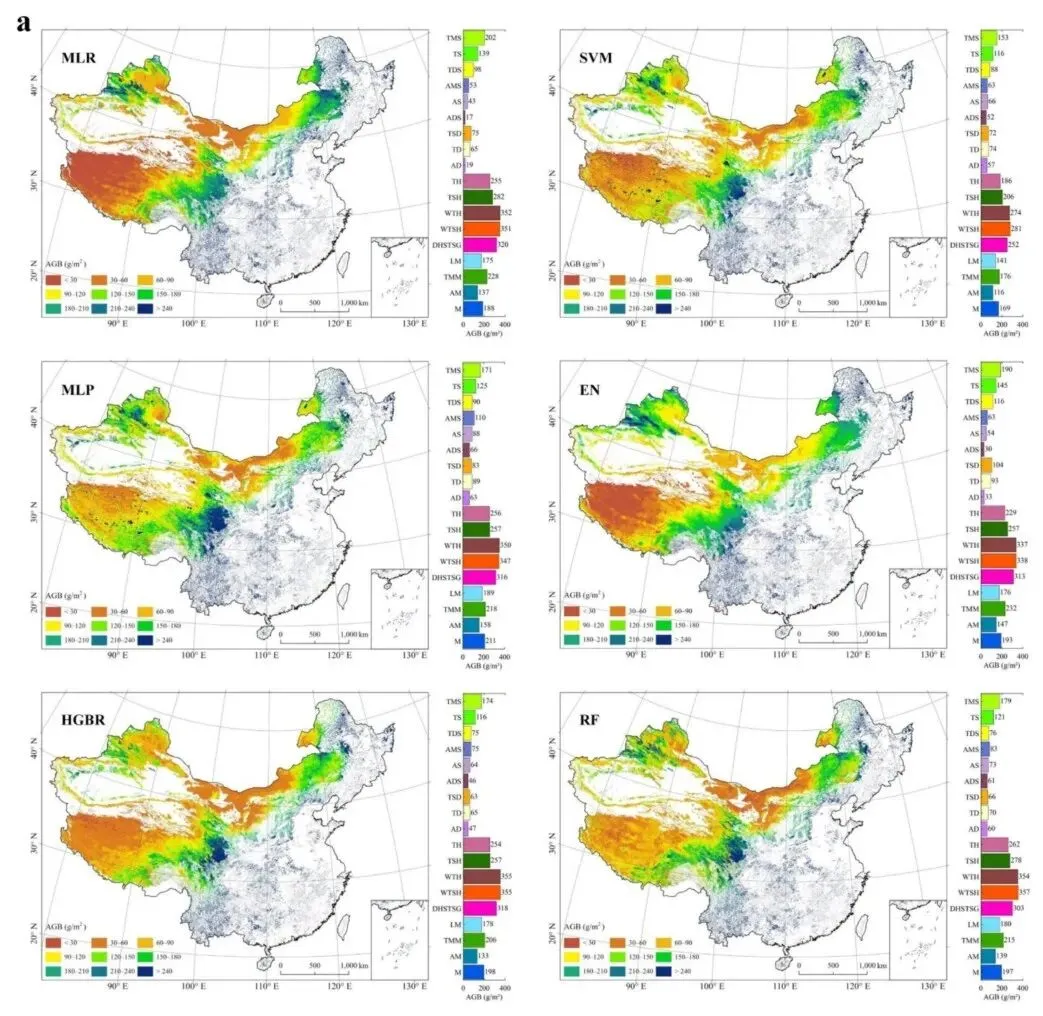
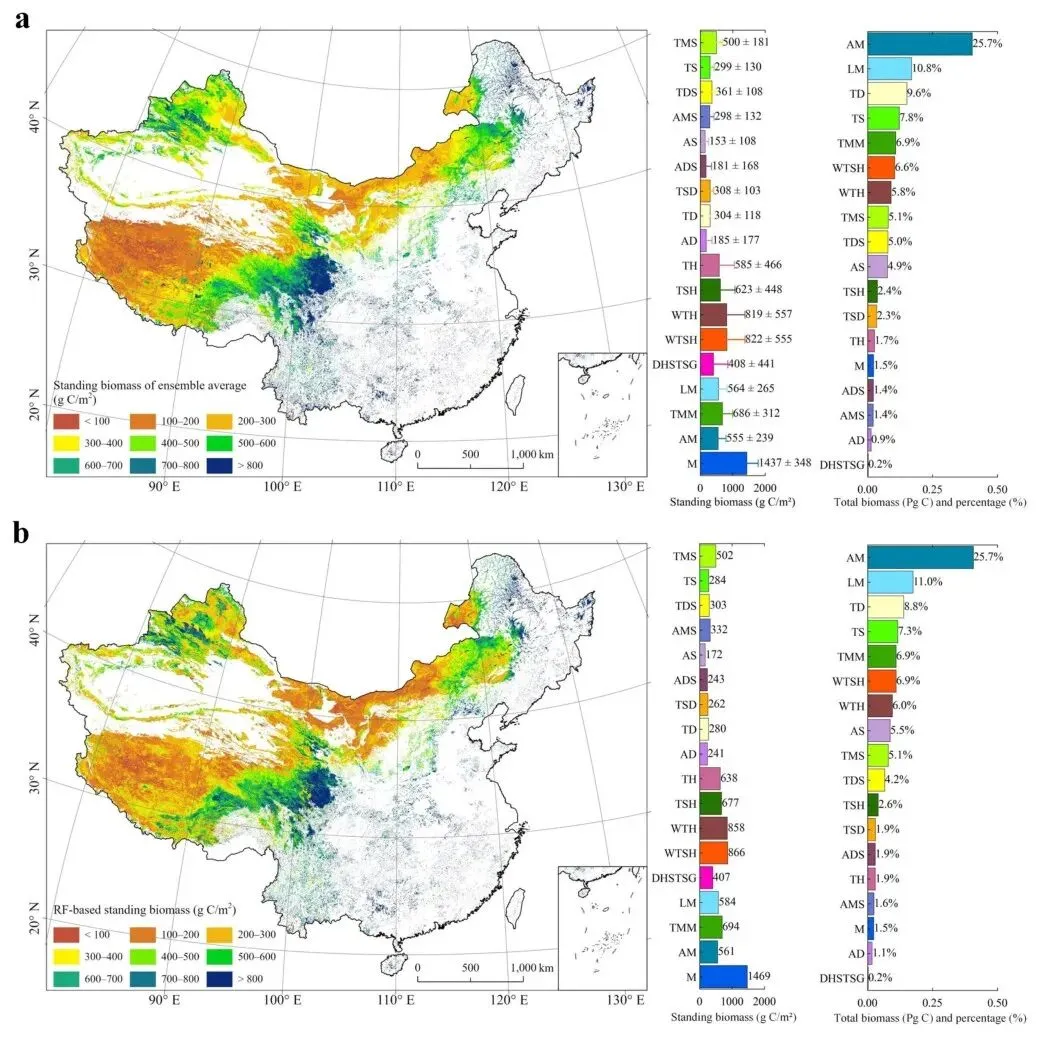
基于蒙特卡洛模拟,绘制了中国草地AGB的空间分布图,6种ML模型的集合平均值为0.55±0.04 Pg,RF的最优估算为0.56 Pg。6种ML模型的AGB空间分布表现出高度一致性,从中国南方的丛生草地和热带稀树草原(约295 g/m²)向青藏高原的高山草地(约46 g/m²)递减。所有ML模型均显示,中国南方干热稀树灌草(DHSTSG)、暖温性草丛(WTH)、暖温性灌草丛(WTSH)、热带草丛(TH)和热带灌草丛(TSH)具有最高的AGB值(186-357 g/m²),而高山和荒漠草原的AGB值最低,范围为17-110 g/m²。
基于按草地类型分布的面积聚合,高山草甸(AM)的AGB最高,范围为0.08-0.11 Pg,约占中国总量的20%,而高山荒漠(AD)仅贡献约0.4%(小于0.002 Pg)。与6种ML模型的集合平均值相比,SVM结果在18种草地类型中始终偏低,而MLR、EN和MLP的低估主要出现在中国南方的高AGB区域。基于6种ML模型估算的集合标准偏差(SD),发现显著差异集中在丛生草地和高山草甸(如TMM和AM),平均SD分别为38和33 g/m²。此外,中国东北的低地草甸(LM)和沼泽(M)也具有较高的SD(33-34 g/m²)。
图4 2020年中国10 m分辨率草地AGB空间分布图,右图展示18种草地类型的柱状图统计。(a)由MLR、SVM、MLP、EN、HGBR和RF模型生成的AGB图,(b)使用6种ML模型的AGB估算集合标准偏差(原文Fig. 4)
4. 中国草地总生物量估算
利用网格化AGB估算和根冠比,估算了中国草地总地上生物量,6种ML模型的集合平均值为1.74 Pg C,RF的最优估算为1.77 Pg C。放牧季(6-9月)的总采食量根据2020年2.35亿羊单位和每羊单位日干草需求量1.8 kg估算为0.02 Pg C。将总地上生物量与总采食量相加,2020年中国草地的植物碳储量估计为1.76 Pg C(6种ML模型集合平均)和1.79 Pg C(RF)。由于草地类型面积聚合的放大效应,总地上生物量存在较大差异,范围从SVM的1.54 Pg C到MLP的1.93 Pg C。总体而言,18种草地类型各自的总地上生物量在6种ML模型的集合平均值与RF最优估算之间差异很小。
图5 中国草地总地上生物量空间分布图(由AGB和植物根系组成),中图展示18种草地类型每平方米平均地上生物量统计(单位:g C/m²),右图展示按草地类型分布面积聚合的总生物量。(a)使用6种ML模型的地上生物量估算集合平均,(b)RF估算(原文Fig. 5)
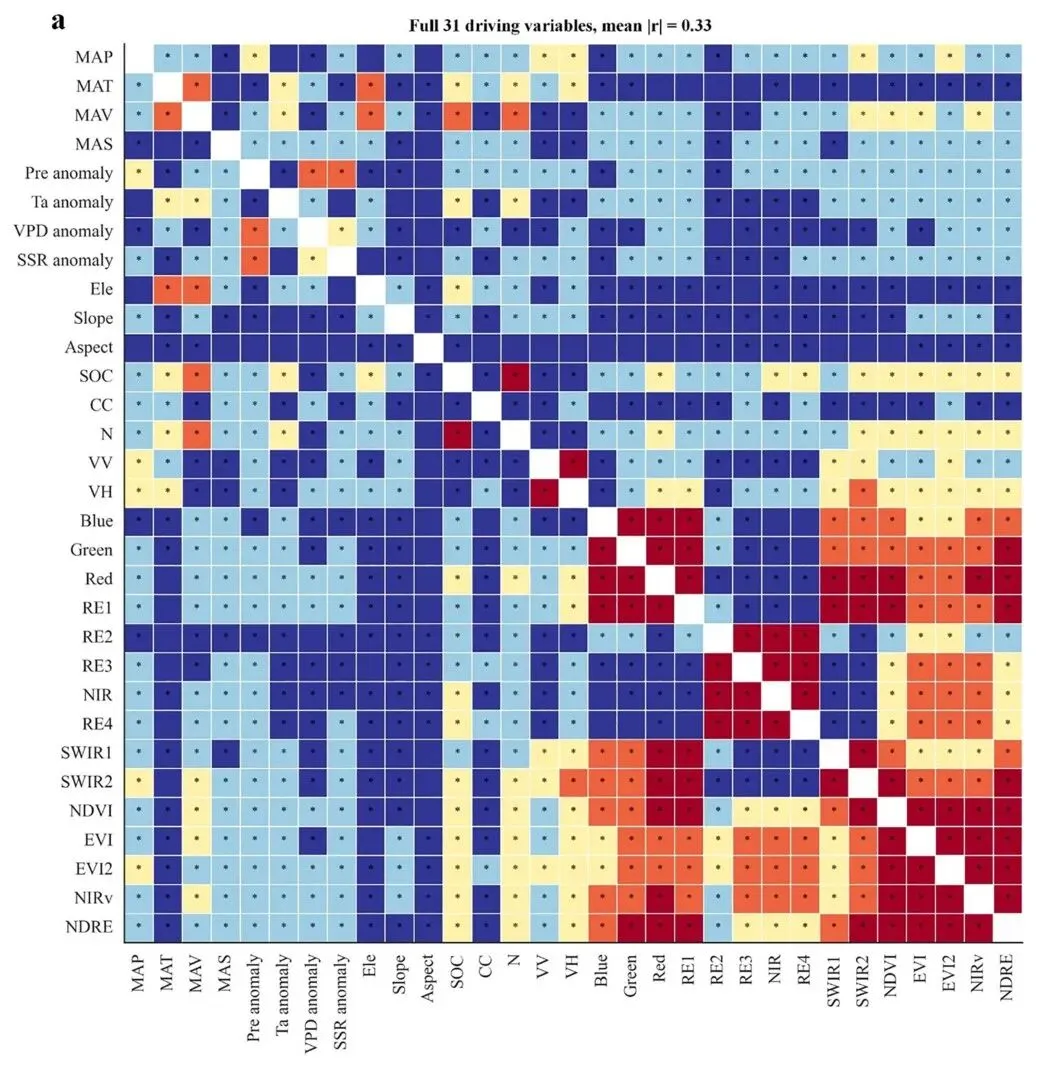
5. 驱动变量共线性对ML模型的影响
共线性在高维变量建模中普遍存在,被认为会偏离统计理论并使AGB建模过程复杂化。研究发现,31个驱动变量中约92%的组合具有显著共线性(|r|=0.33,p<0.001),尤其是卫星光学指标之间的平均|r|为0.61。在蒙特卡洛模拟中,EVI被测试为15个光学指标中AGB建模的竞争性代理变量,结果表明包含多样化卫星指标的组合并未显著增加建模能力。相比之下,MAP基于RF-MDI重要性评级分析和蒙特卡洛模拟被发现具有更稳健和更重要的作用,尽管与EVI存在共线性(|r|=0.39,p<0.001),这表明降水格局在决定AGB变化方面发挥着关键作用。
通过蒙特卡洛优化模拟,驱动变量的数量和变量间的共线性显著减少,6种ML模型的有效驱动变量总数少于10个,最佳RF模型为6个变量,|r|降至≤0.30,这不仅提高了ML算法的预测能力,还阐明了驱动变量与AGB之间的耦合关系。
图6 驱动变量的相关性矩阵,标注p<0.001的显著性水平(*)。(a)31个驱动变量,(b)MLR、EN、RF、HGBR、MLP和SVM模型的蒙特卡洛优化驱动变量(原文Fig. 6)
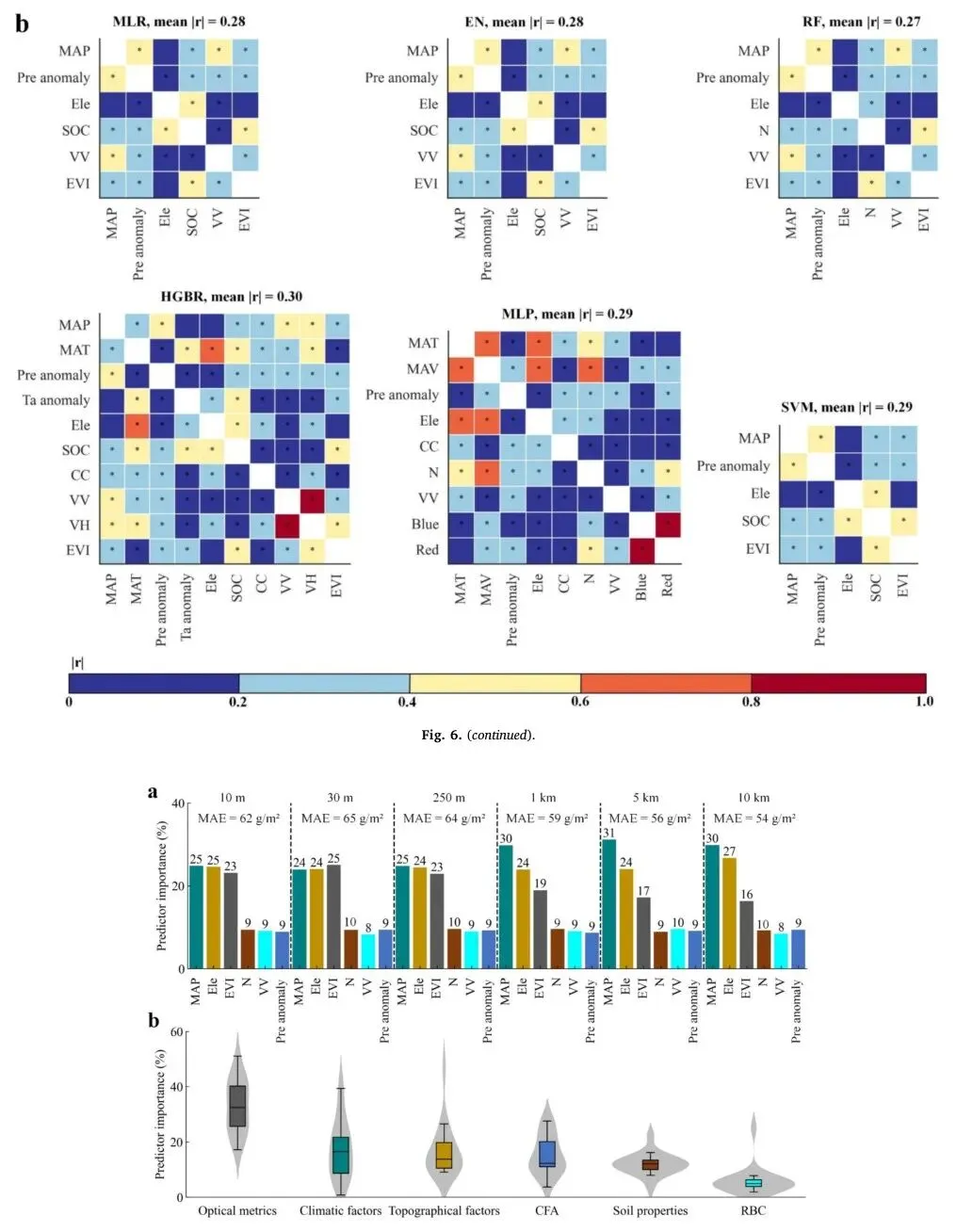
6. 驱动变量的尺度效应
值得注意的是,31个驱动变量具有从10 m到10 km的多种分辨率,这可能影响了AGB的精细尺度估算。使用蒙特卡洛优化的驱动变量(即MAP、Ele、EVI、N、VV和降水距平值),通过RF-MDI方法计算了10 m、30 m、250 m、1 km、5 km和10 km空间分辨率下驱动变量的重要性。研究发现,随着分辨率从10 m降低到10 km,MAE下降,这是因为气候因子的影响增加(MAP增加5%),但卫星EVI的影响减少(7%)。相反,当限制在草地类型区域内时,气候因子和卫星光学指标的优先级发生了反转,前者贡献17%,后者贡献33%,表明气候因子和卫星指标之间存在尺度效应。
这一发现与主流生物气候学理论一致,即优先考虑气候因子来区分草地生物群落,同时卫星光学指标有助于解释草本植物(禾草和杂类草)AGB的空间异质性,作为第二贡献因素。这一发现进一步表明,研究者广泛采用的分类建模可以最小化生物气候学异质性,并增强经验模型在AGB升尺度中的性能。据此,研究者建议依靠气候因子(如MAP)和卫星指标(如EVI)之间的互补尺度效应可以提高大范围AGB估算的升尺度鲁棒性。
图7 AGB升尺度估算中的预测因子重要性。(a)使用RF模型蒙特卡洛优化模拟得到的驱动变量在18种草地类型中随空间分辨率变化的重要性变化,(b)通过约束草地类型得到的多样化驱动类别的重要性变化(原文Fig. 7)
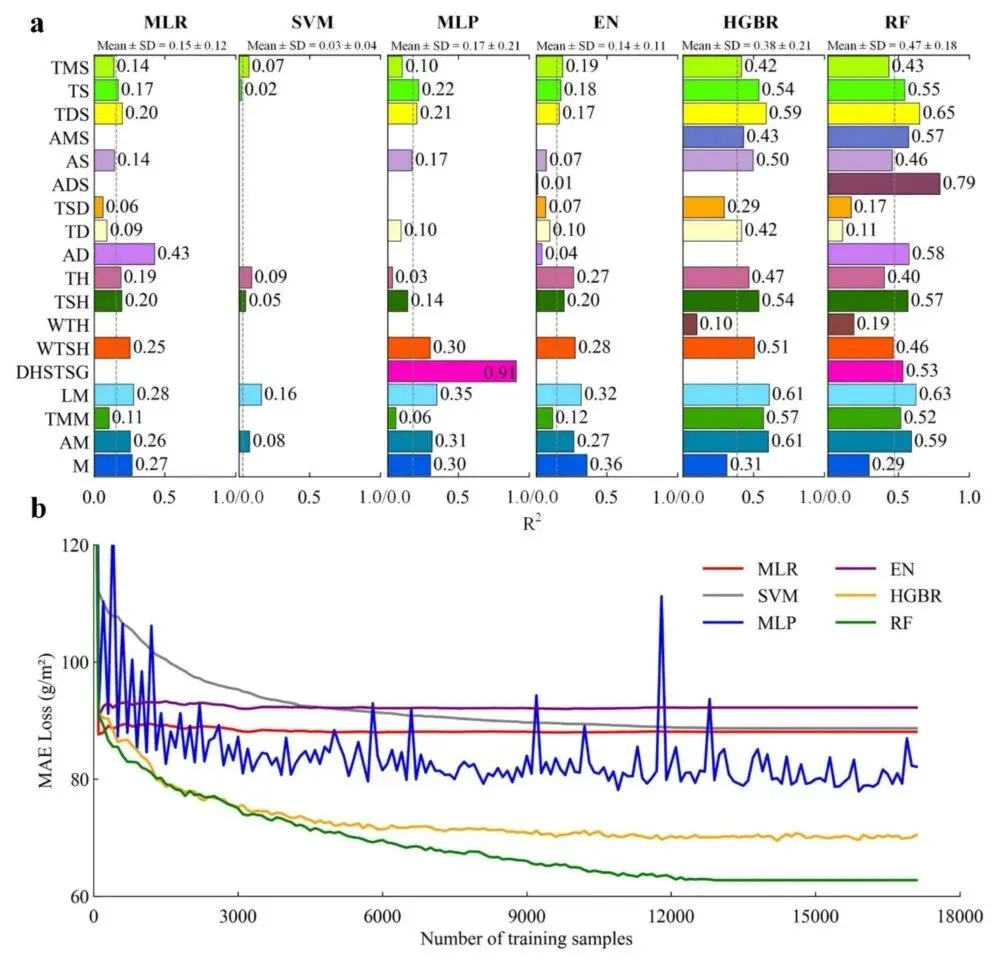
7. 不饱和训练对ML鲁棒性的影响
为检验6种ML算法的鲁棒性,对单个草地类型和分箱训练样本进行了AGB建模。与使用17421个地面实测AGB样本进行6种ML训练所达到的R²=0.28±0.11相比,对18种草地类型分别估算AGB的平均R²下降了0.06,R²变化的标准偏差增加到0.15,表明建模方案能力不足。值得注意的是,4种模型(MLR、SVM、MLP和EN)的预测精度急剧下降,R²≤0.17。
基于迭代训练,所有ML算法均表现出饱和和收敛趋势,但变化轨迹不同。系统性的线性建模倾向于聚合驱动变量的整体特征,但同步消除了决定中国AGB的生物气候学差异。因此,MLR和EN算法的MAE有效下降,但当训练样本数增加到约3000时趋于稳定。相比之下,SVM的MAE损失呈平缓下降趋势,但由于超平面参数的解不一致,其最大MAE损失未超过MLR。MLP在迭代训练中MAE损失呈中等下降趋势但出现波动,表明全局拟合的权重解不稳定。在6种ML算法中,HGBR和RF的MAE损失曲线表现出相似模式,但RF在训练样本数超过3000后MAE下降更快。总体而言,充足数量的训练样本可以保证收敛鲁棒性,而代表性不足的训练极易导致ML模型建立的不稳定性。
图8 6种ML算法在18种草地类型及迭代训练中的鲁棒性。(a)通过约束草地类型得到6种ML模型的R²变化,(b)通过每100个样本增加训练样本数的迭代训练中MAE损失的下降趋势(原文Fig. 8)
8. 草地总生物量估算的不确定性
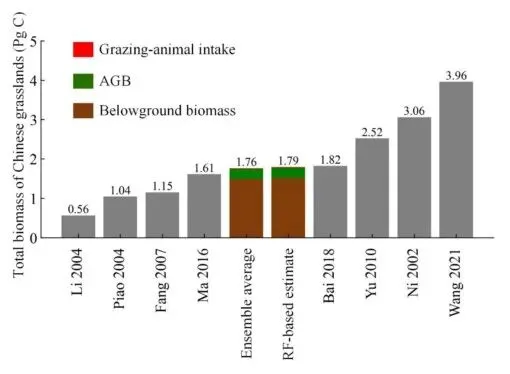
研究者曾提出中国草地总生物量范围为0.56-3.96 Pg C,在草地碳储量评估方面存在巨大差异。本研究中多个ML模型的集合平均显示中国总地上植物生物量为1.74±0.13 Pg C,基于RF的最优估算为1.77 Pg C。以往的草地生物量估算主要依赖碳密度调查数据,这些数据最初源自北美大草原和欧亚草原,导致对中国草地碳储量的评估产生偏差。基于4207个野外调查和100 cm深土壤数据,Bai和Chen估计中国草地生物量为1.82 Pg C,这与本研究使用AGB升尺度和根冠比方法得到的结果接近。遗憾的是,研究者通常忽略了被牲畜采食的部分(0.02 Pg C)。本研究建议,包括放牧采食在内的总草地生物量为1.79 Pg C,以往研究中对中国草地的植物碳储量普遍被低估。
图9 使用6种ML模型集合平均、RF最优估算和以往研究的中国草地总生物量对比直方图(原文Fig. 9)
⚛️ 结论
主要发现:
1.多维度驱动变量的冗余性:31个驱动变量并未增强ML算法在AGB建模中的性能,蒙特卡洛优化后有效驱动变量数量可减少至6-10个,显著降低了变量间的共线性并提高了预测能力。
2.气候因子与卫星指标的尺度效应:年均降水量(MAP)主导18种草地类型间AGB的空间变化,而卫星EVI是第二大贡献因子,两者之间的互补尺度效应可以提高大范围AGB估算的升尺度鲁棒性。
3.ML算法的饱和收敛特性:现有ML算法普遍存在饱和收敛趋势,训练样本代表性不足会导致模型不稳定。在6种算法中,随机森林(RF)表现最优,R²达到0.68,但需要充足的训练样本(至少3000个)才能保证收敛鲁棒性。
4.中国草地植物碳储量估算:基于RF最优估算,2020年中国草地植物碳储量为1.79 Pg C,包括地上生物量0.25 Pg C、地下生物量1.52 Pg C和牲畜采食量0.02 Pg C,以往研究普遍低估了这一数值。
管理启示:
●ML建模需警惕“黑箱”陷阱:在使用ML方法进行生物量升尺度估算时,应充分考虑模型训练的鲁棒性以及气候因子与卫星指标之间的互补效应,避免盲目使用高维变量。
●训练样本的充分性至关重要:至少需要3000个以上的训练样本才能保证ML模型的收敛鲁棒性,训练样本不足时应谨慎使用ML模型。
●10 m分辨率Sentinel数据的应用前景:本研究提出的10 m分辨率Sentinel-1/2卫星数据与先进ML技术相结合的建模方案,可以从家庭牧场单元到更广泛尺度推进草地放牧管理和碳储量评估。
🔖 引用格式
Li Huaqiang, Li Fei, Xiao Jingfeng, Chen Jiquan, Lin Kejian, Bao Gang, Liu Aijun, Wei Guo. A machine learning scheme for estimating fine-resolution grassland aboveground biomass over China with Sentinel-1/2 satellite images[J]. Remote Sensing of Environment, 2024, 311: 114317.
📋免责声明
公益传播和学习目的,内容源于官网期刊论文。使用AI进行解读,如有错误请联系我们修改或删除。
💡温馨提示
由于微信公众号调整了推送规则,为确保您能第一时间收到我们的更新,请将"全球变化与风险防范"设为星标(操作方法:公众号主页→右上角菜单→设为星标),或每次阅读后点击页面下方的"点赞👍"和"推荐❤️"。感谢您的支持!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
