 2026 年的 AI 圈比任何时候都热闹。Hermes、OpenClaw 这些通用智能体每周都在刷新榜单,Harness、Context Engineering、A2A、MCP、ACP 、CLI......这些新词隔几天就换一批。但如果你把目光挪到农业场景里,会发现另一幅图景——AI+农业的落地现场,90% 的项目卡在同一个地方:「方案里很神,落地时不灵」。
2026 年的 AI 圈比任何时候都热闹。Hermes、OpenClaw 这些通用智能体每周都在刷新榜单,Harness、Context Engineering、A2A、MCP、ACP 、CLI......这些新词隔几天就换一批。但如果你把目光挪到农业场景里,会发现另一幅图景——AI+农业的落地现场,90% 的项目卡在同一个地方:「方案里很神,落地时不灵」。这篇文章不讲“AI如何改变农业”,我想说的是另一件更具体的事——当 Agent 工程化的技术栈在快速商品化,AI+农业真正该去抢的,不是做一个更聪明的 Agent,而是三件“买不到”的东西:场景的切分能力、场景中的复利数据、以及把Agent装进行业闭环的工程功底。
下面分四块聊。先看清热闹,再看清底牌,再看清政策,最后落到具体要做的事。
壹
T E C H S H I F T · 技术位移
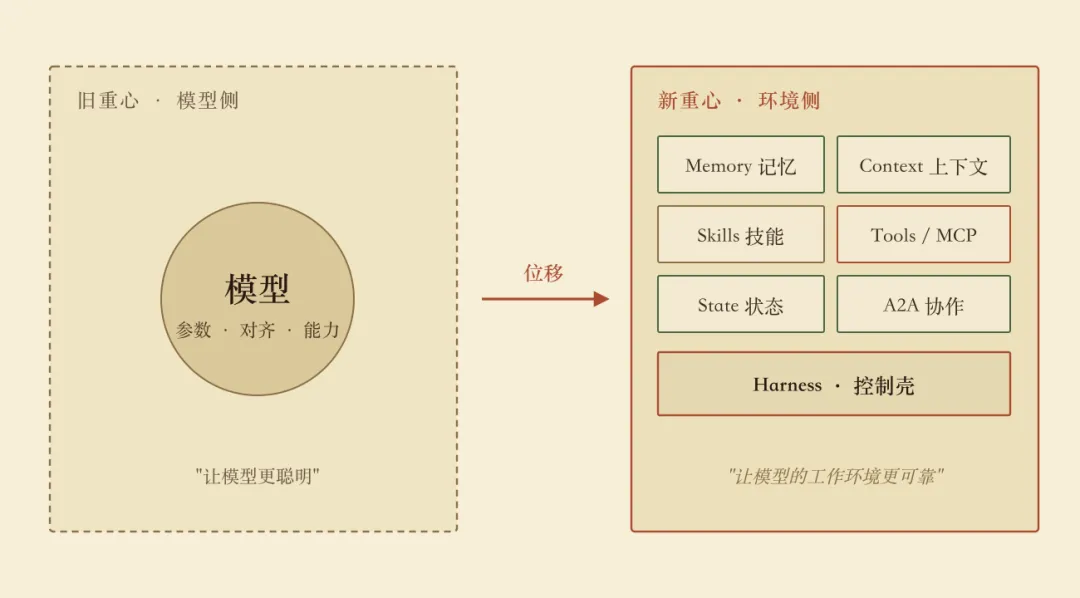
Agent 工程化的重心,正在从模型侧移到环境侧
2026 年最值得观察的变化,不是哪家模型又涨了多少分,而是 Agent 工程化的重心发生了一次明显的位移——从“让模型更聪明”,转向“让模型的工作环境更可靠”。
这个位移藏在几个今年爆火的项目里。不把它们的热度放在一起看,看不清趋势。
Hermes 被热捧不是因为模型能力,而是它给出了一套可落地的“技能闭环”——Agent 执行任务之后会自己反思、提取经验、写进本地记忆,下一次碰到类似任务就能自动复用。这套流程用 FTS5 + SQLite 在本地跑,热上下文刻意压到 1300 tokens 左右,Skill 和 Tool 严格分开:Tool是原子动作 | Skill是结构化经验。
更微妙的是它的nudge机制——在对话的恰当时机主动提示“这条经验要不要存下来”,把“会学习”从“偶尔灵光”变成了一个稳定可预期的工程行为。
Hermes 最值钱的不是 Skills 闭环本身,是它让所有人意识到:记忆管理才是 Agent 的瓶颈,不是推理。
OpenClaw 走的是另一条路。它不关心单个 Agent 有多强,它关心一堆 Agent 跑起来的时候,谁来调度、谁来限流、谁来接外部工具。它的架构拆成两层——Gateway 负责对外协议、通道、鉴权、限流;Engine 负责内部的大脑、记忆、工具调用、评估。队列驱动、lane-aware FIFO、向量 + BM25 混合检索、对 MCP 统一做桥接(MCP 进来变成 CLI,统一挂到工具链上)。
说白了,OpenClaw 在做的不是一个 Agent,是一个可以跑很多 Agent 的“操作系统”。它的流行说明一件事——市场已经开始觉得“单个 Agent 能做什么”是过时的问题,“一堆 Agent 协同能做什么”才是正在被打开的问题。
2026 年还有两个必须放在一起理解的新词。一个叫Agent Harness——简单说,就是把 Memory、Tools、State 从 Agent 主体里剥离出来,单独做成一个“控制壳”;OpenAI Codex 用这套思路跑过百万行代码的实验,LangChain 的 Deep Agents 已经改名 Harness。另一个叫Context Engineering——上下文不是靠 Prompt 模板硬拼的,而是靠一个“信息供给系统”动态组装的,包括系统提示、用户提示、短期记忆、长期记忆、RAG、结构化输出、token 优化六块。
这两个词听着很新,本质是同一件事——单靠模型聪明已经顶不住真实任务的复杂度,必须把模型周围的环境工程化、基础设施化。Context Engineering 圈内甚至有个共识叫 “Context Rot”——上下文在长任务里会腐烂,不主动管理就必出问题。
再往外一层看——Google 推的 A2A(Agent 发现和协作)、Anthropic 主导的 MCP(工具和资源标准化接入)、JetBrains 和 Zed 联合的 ACP(Agent 进程生命周期管理)——这三个协议在 2026 年第一次有了“协议栈”的样子。单 Agent 靠 MCP 接工具,多 Agent 靠 A2A 互相发现,运行时靠 ACP 被 IDE、客户端、编排器管理起来。
图 12026 Agent 工程化的重心位移:从模型侧到环境侧把这些放在一起看,今年 Agent 工程化的底层变化就清楚了——模型是器官,环境是身体。过去两年大家都在打磨器官,现在开始意识到器官再强,没有身体撑不住。Hermes 做的是“长期记忆”这块肌肉,OpenClaw 做的是“调度和协同”这块肌肉,Harness 做的是“让这些肌肉可以被替换”这件事,Context Engineering 回答的是“怎么给模型喂对信息”,A2A/MCP/ACP 则把这整套东西标准化成协议。
理解了这个位移,你再去看 “AI+农业”的很多讨论,会发现大部分人还在讨论“模型够不够聪明”——这其实已经不是主要矛盾了。主要矛盾是——农业这个“环境”,现在能不能被工程化。
✦ · ✦ · ✦
貳
C O M M O D I T I Z A T I O N · 底牌
热闹背后的底牌:框架和 Harness 都在快速商品化
讲完位移,必须讲另一面。这一面很多人不愿意讲,因为不好听。
2026 年 AI Agent 圈真正的“不方便的真相”是——Agent 框架在死,控制壳(Harness)也在快速商品化。你今天花三个月搭起来的那套工程底座,大概率在 12 到 18 个月内会变成一个 API 调用。
这个判断不是我发明的。CrewAI 的创始人 João Moura 2026 年写过一篇短文,里面有句话很狠——“框架已经死了,控制壳也在商品化”。他的论据很简单——两年前你要搭一个 Agent,得自己做 Planner、做 Memory、做工具路由;今年你用 OpenAI Agents SDK、LangChain Deep Agents、Anthropic 的官方 SDK,十几行就跑起来了。再往后看,Harness 这一层里该有的组件——记忆管理、工具路由、状态恢复、评估循环——正在被大厂一件件吸进 SDK。
MCP 从 Anthropic 的“自家协议”变成了 Linux Foundation 托管的行业标准。A2A 被 Google 推成了 Agent 间通讯的默认语言。ACP 把 Agent 进程的生命周期管理抽象成了类 LSP 的接口。这些协议只要跑顺了一个,剩下的工程量就是“接”而不是“造”。
这意味着什么?意味着“我们有一套自研 Agent 框架”这句话,在 2027 年基本不再是一个卖点。就像 2020 年之后没人会拿“我们自研了一套 Web 框架”当护城河。
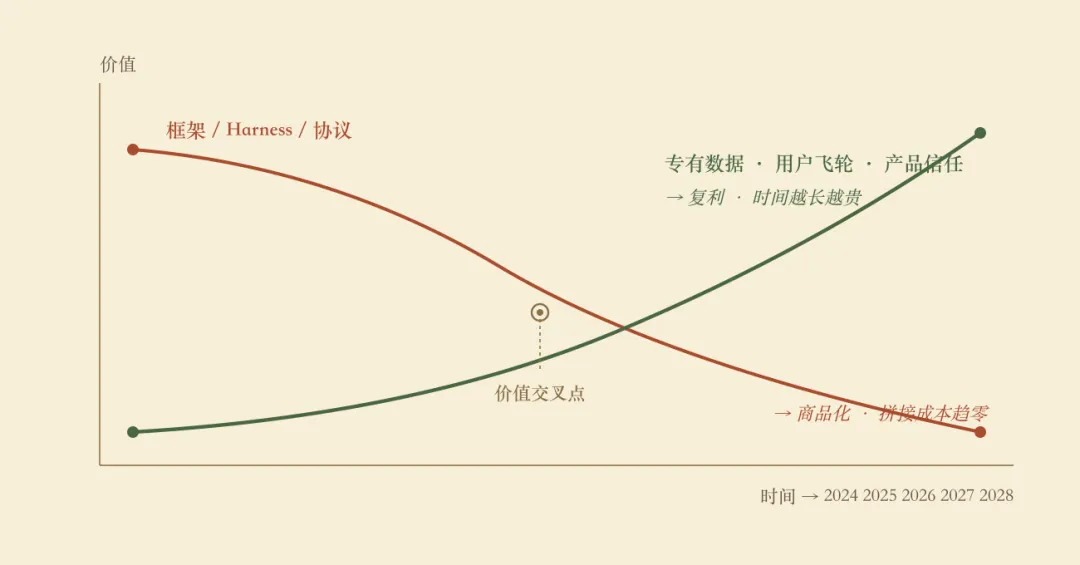
图 2商品化曲线 × 复利资产曲线João 把它归为一个词——Entangled Software(纠缠软件)。翻译成大白话就是三件东西:
◇专有数据——不是爬下来的公共数据,是你在业务场景里每天产生、别人拿不到的数据;
◇用户反馈飞轮——用户每一次使用都在让你的 Agent 变得更适合他,别人重新做一遍得从零开始;
◇产品信任——行业里对“出了事找谁”有默认答案,这种信任是多年攒的,不是一轮融资买得到的。
这三件东西的共同特征是时间越长越贵——复利。而框架、Harness、协议的共同特征是时间越长越便宜——商品化。2026 年开始,Agent 赛道的胜负手已经从“谁的框架更强”,换成了“谁在用框架攒复利资产”。
农业领域尤其要听懂这句话——别把三年的窗口期浪费在重复造 Agent 框架上。比如去HuggingFace 上每周都能刷出十几个新框架,但云南的某个烟草产区十年病虫害+物候+产量的配对数据,全世界只有一份。
我最近扫了一遍 GitHub 趋势——AI Agent 基础设施类项目已经是 stars 最密集的赛道,动辄几十万、上百万。但农业相关的开源项目,最高star 数才185。这不是因为农业不重要,是因为农业在开源世界里天然有信息差——懂技术的看不懂农业,懂农业的不写代码。
对想在“AI+农业”里找位置的人来说,这是个好消息——你不需要赢 AI 圈的卷王,你只需要把 AI 圈已经卷出来的东西,接到你懂的农业场景里去。前者是红海,后者是蓝海。
✦ · ✦ · ✦
叁
P O L I C Y · 政策窗口
政策给的不是补贴,是“场景进入权”
聊完技术面的两个判断(重心位移 + 商品化),必须把视野拉到政策面。因为农业和别的行业不一样——农业的每一次技术变革,几乎都由政策牵引。
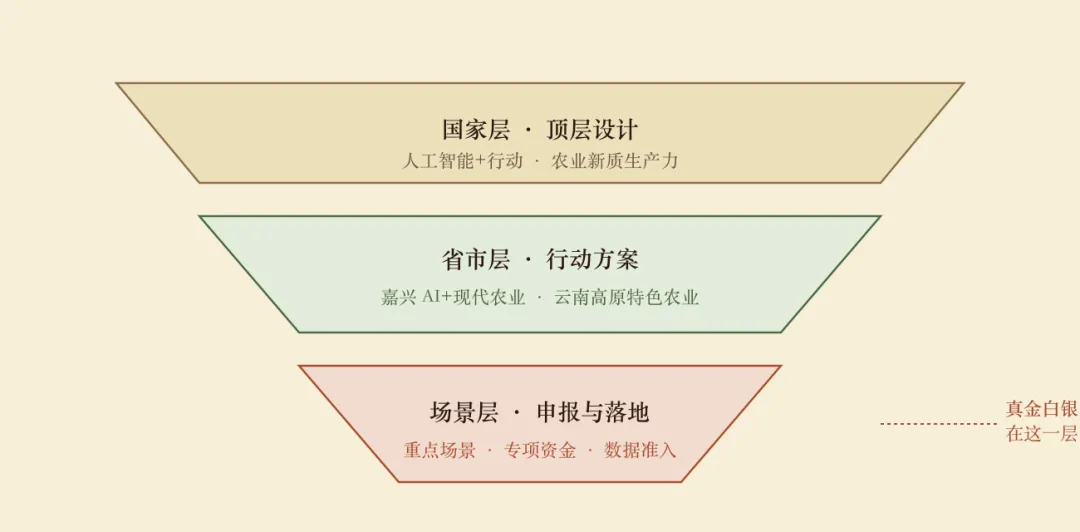
2025 到 2026 这一年半,三个层级的政策信号叠在一起,构成了 “AI+农业”最清晰的一次窗口期。
2025 年 8 月,国务院正式发布《“人工智能+”行动意见》,列了六大重点行动,其中单独把“人工智能+产业发展”拎出来,把农业、制造、能源、医疗并列放进去。
同一年的中央一号文件里,第一次出现“农业新质生产力”这个表述,紧跟着的配套文件要求“加快农业人工智能、大数据、遥感、物联网等新一代信息技术的融合应用”。这在过去十年的一号文件里是没有的——以前讲的是“信息化”、“数字化”,现在讲的是“智能化”。
国家层是方向,地方层才是真金白银。我看到的几个典型动作——
◇嘉兴 2025 年发布的《AI+现代农业发展行动方案(2025-2027)》,明确三年内要在育种、种植、养殖、加工、流通五个环节形成"可复用的 AI 应用库";
◇云南省把“人工智能+高原特色农业”写进了 2026 年的数字经济行动计划,咖啡、花卉、中药材、烟草这些优势品类被拎出来做专项;
◇多个农业大省在 2026 上半年开始做“重点建设场景”申报,地方财政 + 产业基金的组合,明显在往具体场景倾斜,而不是再撒给泛泛的“智慧农业平台”。
图 3政策的三层结构:窗口真正打开在最底层很多人把政策理解成“补贴”——这是误读。补贴是副产品。政策的真正价值,是给了你在一个行业里的“场景进入权”。
什么叫场景进入权?举三个具体的——
◇能不能拿到一片示范园、示范基地的数据采集授权;
◇能不能接上地方农业农村局的监测数据、补贴发放数据、主体名录数据;
◇能不能进入“重点场景建设”的白名单,成为后面三年一直被采购的那家。
这三件事都不是花钱买得来的,全是政策窗口期才打开的。窗口期过了,格局定了,新人就很难挤进去——这和互联网当年的“移动互联网红利”、“O2O 红利”等是一个逻辑。
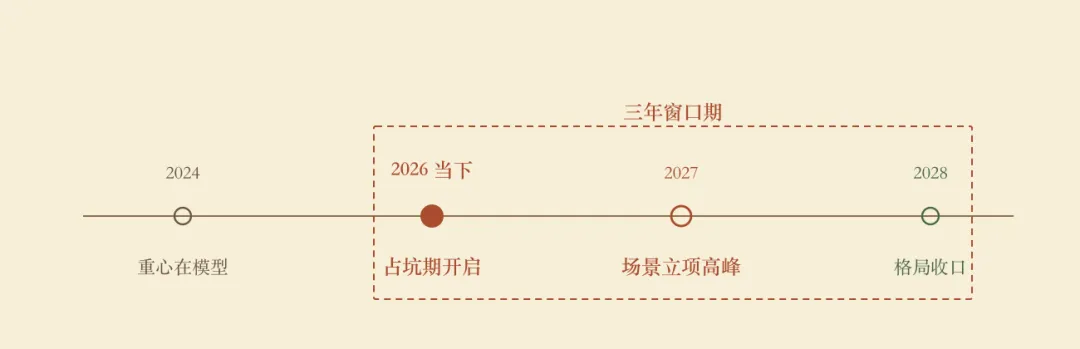
窗口大概多长?我的判断是 2026 到 2028,三年。到 2029 年,各省的“AI+农业”建设方案应该都进入运营期而不是立项期了,那时候新团队再想进去,就只能做分包或者 SaaS 采购对象,而不是场景定义方。
所以你会看到一个奇怪的现象——技术面的卷王(Hermes、OpenClaw)在 GitHub 上死磕 stars,但真正聪明的 “AI+农业”团队这两年都在扎进市县,跟地方农业部门、示范基地一起磨方案。因为技术面每 18 个月重置一次,场景进入权过了窗口就重置不了。
✦ · ✦ · ✦
肆
A C T I O N · 落地四件事
回到农业:真正要做的四件事
前面三块是判断,这一块是动作。
把技术的位移、商品化的底牌、政策的窗口叠在一起看,2026 年 “AI+农业”真正值得做的事其实不多——我理下来是四件,也就四件。每一件背后都有一个反共识的判断。
图 4农业落地四件事:每一件背后都是一个反共识过去十年,行业里说“智慧农业平台”这五个字的团队基本都不怎么好过。原因很简单——农业没有“一个场景”,农业是几十个差别极大的场景拼起来的。种水稻的逻辑和种春茶的逻辑不一样,烟草的技术员跟花卉的技术员用的关键变量也不一样。
对应到 Agent 上就是一句话——不要想着做一个“农业大脑”盖所有品类或所有场景,要做“单品类 + 单环节”的最小闭环。比如只做烟草种植期的病虫害诊断和农艺建议这一段,或者只做咖啡鲜果加工端的分级和溯源。这个粒度下,Agent 才能在有限时间内跑通一个完整的“感知→判断→建议→执行→反馈”的循环,而不是停在 PPT 里。
技术侧这两年其实在给这个思路递信号——Hermes 强调的 Skill 就是“小、封闭、可复用”,Harness 只在“一个 Agent 够深够专”的前提下才有意义。你的场景切得够细,技术侧所有的东西才做得上劲。
过去所有数字乡村项目都在犯同一个错——要求一线使用者学会操作系统。这件事在过去十年被证明大概率做不成,因为一线使用者(不止生产主体,还有合作社安排员、农服人员、农艺员、乡镇农技员)的系统学习意愿和他们每天产出的价值不成比例。
Agent 时代要换个思路——不是让人去学系统,是让 Agent 去用他们原本就在用的东西——微信群、小程序、电话、语音、手写记录。Browser-use 这类项目在 2025 起来,本质上是告诉所有行业一件事——Agent 可以像人一样操作现有界面,那么农业的开发思路就必须改——不再是让使用者导数据到 PC 端,而是 Agent 自己去抓天气、爬价格、看报告、填报表。
闭环的另一半是“人在环中”。农业跟代码不同,错一次可能一季绝收,所以 Agent 不能全自动。成熟的做法是设一个“自主性阶梯”:建议只读→标注后执行→条件自动→全自动。不同事物在阶梯上的位置不同——农艺建议可以很快上到第三档,灾害预警永远停在第二档。这是工程手艺——不是技术问题,是安全问题。
CrewAI 那个“纠缠软件”的观念放到农业里就是一句话——你的 Agent 要与一线的日常纠缠在一起,而不是要求使用者适应你的 Agent。
很多农业团队这两年在快速积累数据——传感器数据、摄像头数据、无人机影像、物候期数据、农事记录。但积累了不等于沉下来了。真正具有复利价值的不是原始数据,是“业务数据”——哪片地、哪个品种、哪个生长期、什么天气、执行了什么农艺、最终产量和品质是多少。这种数据才能投喂回 Agent 变成下一轮的判断依据。
Hermes 的 Skills 闭环在这件事上是有启发的——不要把经验散在系统、日志、文档里,要把经验写成结构化的 Skill,让下一次同类情境自动跳出来。落到农业就是——去年我们在某个品类上处理的某种异常,今年别的种植主体碰上类似情况,Agent 应该能自动把经验回取过来。
这里有个容易被忽略的大问题——数据的所有权和复利权是两回事。示范基地、合作社、农业龙头企业愿意把数据的所有权留在自己这边,但不介意把数据的“复利使用权”授权给你——前提是你能给他们无法自己做的使用价值。把这个分层设计好了,后面争议少;设计不好,刚做三年就讲不清数据归谁。
最后一件事是很多技术背景的团队最不愿做但不能不做的——与政策对齐。
“AI+农业”的项目与别的技术创业不同——你的关键客户主要不是 C 端用户,也不全是农企,是地方市县的三农干部、示范基地管理者、农业龙头企业的一把手。他们关心的不是模型的 F1 要不要再高两个点,而是“我今年的 KPI、下季度的验收、明年的预算”。
所以偏技术的团队要聚焦三件事——
语言对齐:把 Agent、Skill、Harness 这些词翻译成“可复用的农业应用”、“技术辅导能力”、“场景解决方案”;语言不对齐,没人知道你在说什么。
主体准入:农业项目有一套硬门槛——涉农主体资质、农业产业化龙头认定、高新或专精特新、数据安全资质。这些东西不是装饰,是能不能上桥的桥台。
数据链入局:地方都在建产业大脑、农业农村数据平台、可信数据空间....。这些系统反正都在建,你是想做一个外部系统在旁边跑,还是通过 API、接入标准、连接器接入这个生态里?答案几乎只有一个。
做到这三条,你在地方政府眼里就不是“一个技术公司”,而是“一个能承接重点场景建设的主体”。差别是前者只能接到外包单,后者可以定义场景。
✦ · ✦ · ✦
伍
O U T L O O K · 占坑期
写在最后:2026 到 2028 是农业 Agent 的“占坑期”
这篇文章想说的就三句话。
第一句——技术面的位移已经发生,重心从模型侧转到环境侧。对农业而言,这是好消息——农业的底牌一直就是环境,我们比任何人都熟。
第二句——框架和 Harness 在商品化,这意味着“自研技术”不再是护城河。真正的护城河是专有数据、用户飞轮、产品信任——这三样东西农业领域背景的团队反而更有托底。
第三句——政策窗口有时间限,我的判断是 2026 到 2028,三年。三年之后,那些只会抄热词、孤身卷框架、等政策明朗再进场的团队,大部分会错过最重要的一层位置——场景定义权。
图 5农业 Agent 的占坑期:2026–2028 三年窗口结尾不喊口号。只说一个容易被忽略的事实——中国在农业领域的数字化累积已经做了将近十五年,今天正好遇到 Agent 这一波技术。两条线是重合的——一边是累积了多年的场景和数据,一边是刚刚成熟到可用的环境侧工程化能力。
这种重合不常有,一旦错过,下一次大概得等下一轮技术周期。
写给所有在 AI 时代找农业机会的人——种植企业、农业主管部门、技术团队。不要被热词带跑,也不要因为自己不做框架就觉得没有位置。把场景切细,把闭环造起来,把复利数据沉下来,把政策接上——这四件事做完,你就在应在的位置。
✦ · ✦ · ✦
AI + 农业 · 产业观察
二〇二六年四月底 · 写给正在产业中找位置的人
— F I N I S H —

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
