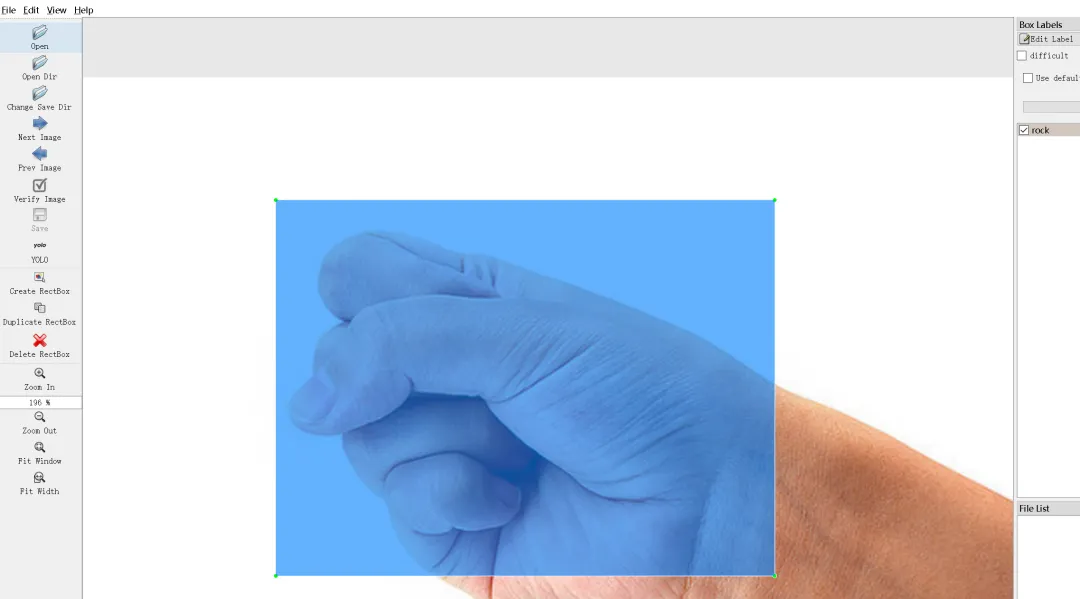
非常牛逼的YOLO模型(农业领域应用挺广泛)从标注到训练再到验证自动标注全流程
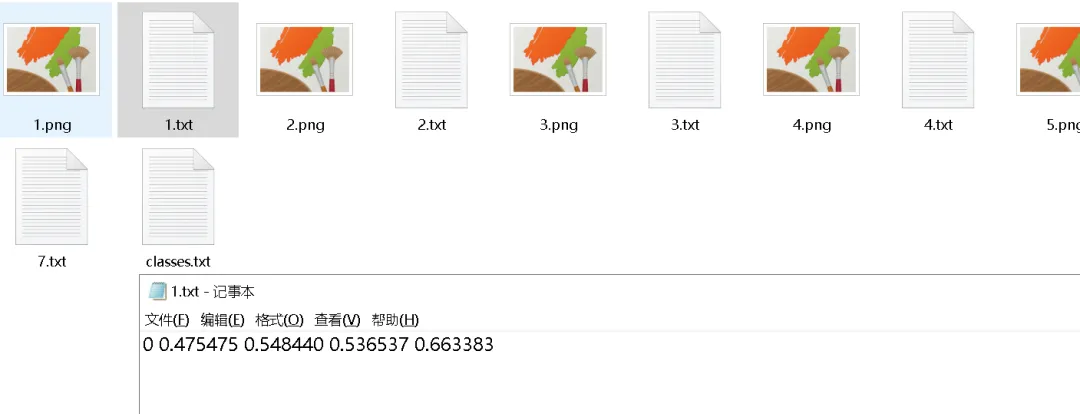
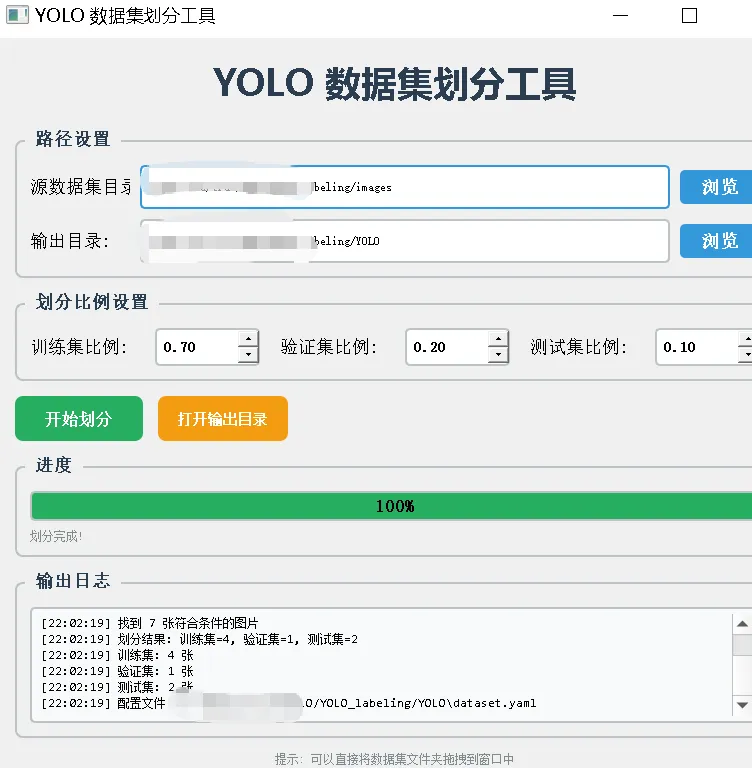
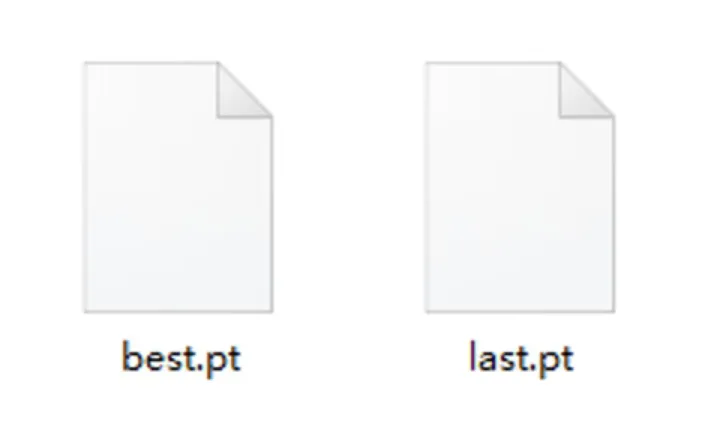
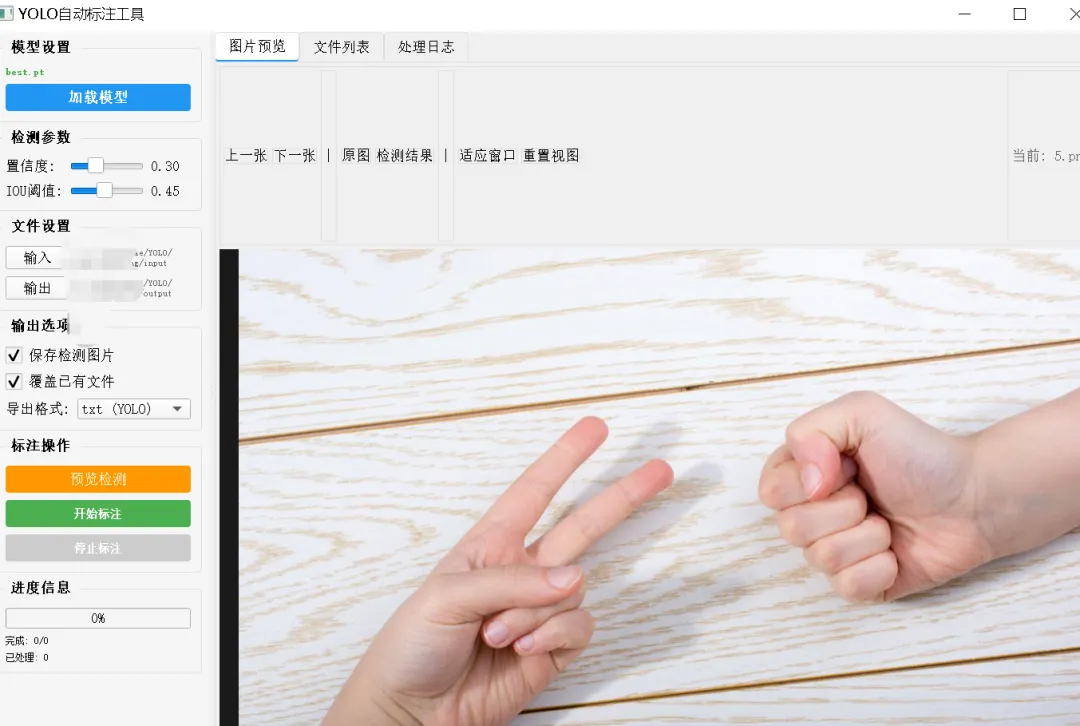
首先,我们简单介绍一下YOLO模型的创始人,背后的故事也十分值得了解。YOLO(You Only Look Once)算法的创始人是Joseph Redmon。Joseph Redmon 在华盛顿大学攻读硕博期间,于2015年首次提出YOLO算法,并在2016年以第一作者发表论文《You Only Look Once: Unified, Real-Time Object Detection》,正式推出YOLOv1。该算法开创性地打造了单阶段目标检测框架,将传统的目标检测任务转化为回归问题,真正实现了端到端、实时高效的目标检测,具备推理速度快、泛化能力强、实用性极高的优势。后续 Joseph Redmon 持续迭代优化算法,主导推出了YOLOv2(YOLO9000)、YOLOv3两个经典版本,针对性提升了模型检测精度、小目标识别能力与场景适配性,让YOLO系列成为计算机视觉领域最具影响力、落地性最强的目标检测算法之一。不过很多人不知道的是,YOLO原版作者早已停止更新维护。2020年2月,Joseph Redmon 在个人社交平台官宣退出计算机视觉研究领域,彻底停止YOLO模型的维护迭代,核心原因源于AI技术伦理考量。Redmon 表示,目标检测技术存在极大的滥用风险,既可能被应用于军事武器识别系统,也会被用于大规模人脸监控、隐私抓取等场景,极易侵犯个人隐私、产生负面社会价值。作为算法研究者,他认为技术研发不能只追求性能突破,更需要兼顾社会影响与伦理底线。在当时人工智能行业缺乏完善的技术规范与伦理约束的背景下,他选择主动退出行业,以此呼吁学术界和产业界重视AI伦理与技术边界问题。虽然原版作者停止了开发,但YOLO开源、轻量化、高精度的优势无可替代。后续业内各大技术团队基于其原生框架持续迭代优化,诞生了YOLOv4、YOLOv5、YOLOv8等一系列主流版本,让YOLO算法持续更新迭代,广泛落地于各行各业。提到YOLO目标检测模型,大家日常可能很少主动接触,但生活中随处可见它的应用,比如实时目标追踪、智能识别、视觉检测等场景。今天我们就完整走通一套YOLO实战流程:从数据集样本标注、数据集划分、模型训练推理,到最终利用训练完成的权重文件,实现批量自动标注数据,完整落地目标检测项目。首先我们可以看一下YOLO算法的行业落地案例,例如柑橘缺陷检测(图片来源于网络公开论文数据集),这类工业质检、视觉识别场景,都是依靠YOLO模型实现精准、高效的目标检测。柑橘缺陷检测(图片来源于网络)了解完商用落地场景后,为了降低上手难度,让大家更清晰易懂地掌握完整训练流程,我们本次不使用复杂的工业数据集,选择剪刀、石头、布的样本图片作为训练数据集,从零开始完成模型训练。我们首先使用标注工具,手动对样本图片进行分类与目标框标注。完成图片标注后,工具会自动生成与图片同名的TXT标签文件,文件内精准记录了目标类别、检测矩形框的坐标信息,为后续模型训练提供核心数据支撑。标注完成的原始样本无法直接用于模型训练,YOLO模型对训练数据有严格的目录规范,需要将数据划分为训练集、验证集。这里我们借助专用工具,一键自动完成数据集分类划分,规整文件目录,满足模型训练标准。数据集准备完成后,我们即可启动YOLO模型的训练与推理任务。模型训练过程中会自动生成大量配置文件与日志文件,所有训练相关的权重、参数、日志都会统一保存。其中目录内的weights权重文件夹,储存了模型训练生成的所有权重文件。文件夹中的best.pt文件,是模型全程训练过程中精度最高、效果最优的权重文件,也是我们本次项目的核心文件。我们可以借助这个自主训练完成的最优权重,对大量未标注的剪刀石头布样本图片,进行全自动识别与批量标注。简单来说,整套流程的核心价值就是:通过少量人工手动标注样本,训练出专属模型,从而实现大批量、自动化的数据标注,极大降低人工标注成本,提升视觉数据处理效率。