香港理工&南京林业大学提出CoEvo:通过测试时双模态代理协同进化,视觉-语言模型的零样本分布外检测性能显著提升
- 2026-07-03 07:09:44


标题:基于视觉 - 语言模型的跨模态代理协同进化分布外检测
导读
在开放世界场景中,视觉-语言模型的零样本分布外(OOD)检测至关重要,却受限于固定文本负样本带来的语义覆盖不足和跨模态错位问题。香港理工大学、南京林业大学等提出 CoEvo 框架,通过测试时双模态代理协同进化破解难题。该框架构建文本与视觉代理缓存,在视觉线索引导下动态挖掘上下文负样本,同时迭代精炼视觉代理,实现跨模态语义对齐与 OOD 区分边际放大。创新的分数进化策略动态平衡双模态权重,生成鲁棒 OOD 分数。实验表明,CoEvo 在 ImageNet-1K 上使 AUROC 提升 1.33%,FPR95 降低 45.98%,在 Near-OOD、Far-OOD 及数据不平衡场景中均表现优异,为无需训练和标注的零样本 OOD 检测提供了高效解决方案,推动开放世界识别技术的实用化。
预备知识
核心概念
分布外检测(OOD Detection):识别模型训练过程中未见过的类别样本,避免模型对未知样本产生过度自信的错误预测,保障高风险场景(如医疗、自动驾驶)的安全性。
零样本场景:无需额外训练样本或提示调优,仅依赖预训练模型和 ID 类别信息完成 OOD 检测。
视觉 - 语言模型(VLM):如 CLIP,通过成对图像 - 文本数据预训练,将视觉和文本信息映射到共享特征空间,支持跨模态语义对齐。
关键指标
FPR95:ID 样本真阳性率(TPR)为 95% 时,OOD 样本的假阳性率(越低越好)。
AUROC:受试者工作特征曲线下面积,衡量 ID 与 OOD 样本的整体可分离性(越高越好)。
ID ACC:ID 样本的分类准确率(越高越好)。
研究动机
现有基于负标签的零样本 OOD 检测方法存在两大核心缺陷(对应文中分析):
负语义空间覆盖不足:依赖全局固定的文本负样本集,难以充分覆盖 ID 类别之外的广阔语义空间,遗漏样本特异性的有效负样本。
跨模态错位:测试时视觉特征会因分布偏移而变化,但文本负样本保持固定,导致跨模态相似度计算失真,决策阈值不稳定。
尽管AdaNeg 等方法尝试动态调整视觉代理,但仍沿用固定文本负样本,仅实现单向适配,无法彻底解决跨模态错位问题。因此,论文提出需通过双向、样本条件的跨模态适配,让文本负样本和视觉代理协同进化,实现鲁棒的零样本 OOD 检测。
创新点
提出CoEvo 框架:首个在测试时构建语义对齐的 ID/OOD 双模态代理缓存,无需训练和标注,仅依赖测试样本动态适配。
设计代理对齐协同进化机制:实现文本和视觉代理的样本条件双向适配,缓解分布偏移下的跨模态错位(对应图 1)。
提出多模态分数进化策略:根据代理进化过程动态调整文本和视觉分数的权重,生成校准后的 OOD 决策分数,提升检测稳定性。
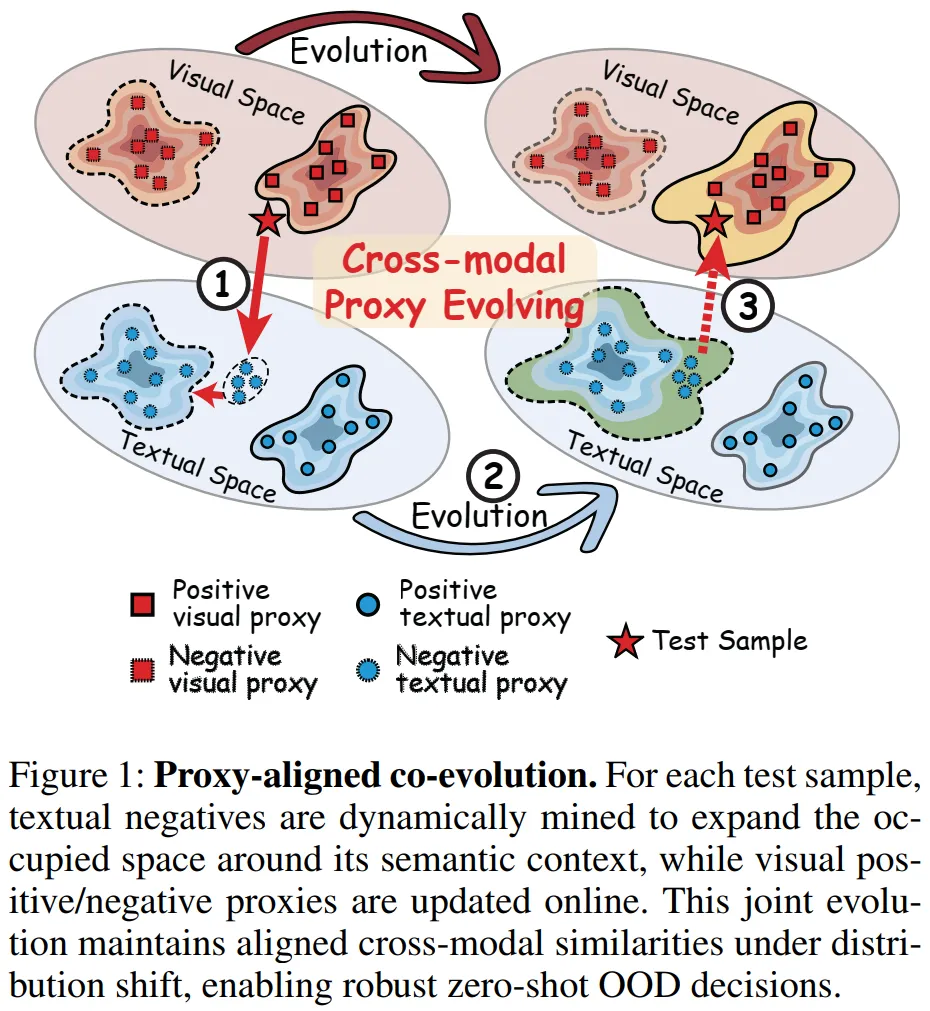
图 1 展示了 CoEvo 框架的核心 ——代理对齐协同进化机制,直观呈现文本与视觉代理的双向适配逻辑。左侧为测试样本,作为进化的触发依据;中间是四类核心代理:正 / 负文本代理(编码 ID/OOD 的语义信息)和正 / 负视觉代理(编码 ID/OOD 的视觉特征)。
对于每个测试样本,文本负代理会在视觉线索引导下动态挖掘:针对 OOD 样本补充语义相近的负样本,针对 ID 样本补充语义疏远的负样本,以此拓展并优化负语义空间;同时,视觉正 / 负代理会在线更新,吸收高置信度样本的视觉特征,精炼 ID/OOD 的视觉决策边界。
这种 “文本适配视觉、视觉反哺文本” 的闭环协同,能在分布偏移时维持跨模态语义对齐,放大局部 OOD 区分边际,为后续精准的 OOD 决策提供可靠支撑。
方法
CoEvo是一种测试时零样本 OOD 检测框架,核心包含双模态代理缓存、代理对齐协同进化机制和多模态分数融合三部分,整体流程如图 2 所示。
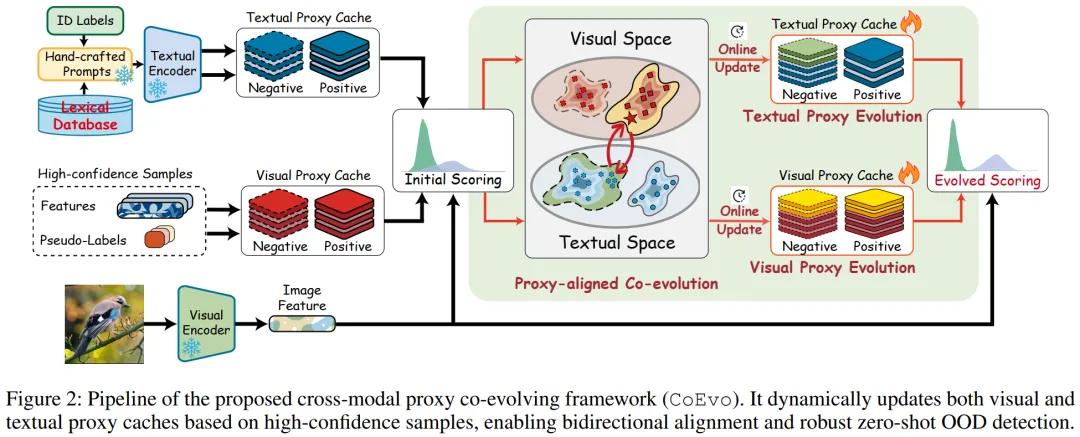
图2展示了CoEvo框架的完整工作流程,核心是通过双模态代理缓存的动态更新与协同进化,实现零样本OOD检测。整个流程以测试样本为驱动,串联文本与视觉模态的编码、代理进化、分数融合三大核心环节,形成闭环适配逻辑。流程起点为ID标签与外部词汇库:ID标签通过手工设计的提示模板(如“The nice cls”)输入文本编码器,生成固定的正文本代理队列(),作为稳定的ID语义锚点;词汇库则提供初始负文本代理(),为OOD语义建模奠定基础。同时,视觉编码器提取测试样本的视觉特征,与文本代理共同参与初始评分。中间核心是代理对齐协同进化:基于初始多模态分数(公式4)与自适应阈值,筛选高置信度ID/OOD样本。文本代理缓存通过视觉特征引导,动态挖掘上下文负样本(OOD样本补充近语义负样本,ID样本补充远语义负样本),在线更新;视觉代理缓存则吸收高置信样本特征,更新正/负视觉代理队列(、),且通过优先级策略保证代理代表性。最后是分数融合环节:进化后重新计算文本与视觉分数,通过动态权重翻转(公式11)融合为最终OOD分数——初始阶段侧重文本稳定性,进化后侧重视觉局部判别力,最终输出ID/OOD决策。整个流程无需训练与标注,仅在测试时完成自适应更新,实现跨模态对齐与鲁棒检测。
4.1. 问题定义
给定输入图像,通过视觉-语言模型提取特征,设计ID置信函数 ,当 (为阈值)时判定为ID,否则为OOD,目标是让ID样本的置信分数显著高于OOD样本。
4.2. 双模态代理缓存
缓存分为文本代理缓存和视觉代理缓存,均包含正负两个队列,分别编码ID 和 OOD 的语义 / 视觉特征。
4.2.1 文本代理缓存
正文本代理队列():固定队列,将每个ID类别标签通过提示模板(如“The nice cls”)输入CLIP文本编码器,生成文本嵌入:(D为嵌入维度),队列形式为 ,提供稳定的ID语义锚点。
4.2.2 视觉代理缓存
4.2.3 初始多模态分数融合(公式 4)
融合文本和视觉的初始分数,平衡模态可靠性:
其中 (实验中),初始阶段给予文本分数更高权重,利用其稳定的语义先验(视觉缓存初始稀疏)。
4.3. 代理对齐协同进化机制
核心是通过双向交互动态更新文本和视觉代理缓存,保持跨模态对齐,对应图 1 的协同进化逻辑,分为三个步骤:
4.3.1 自适应阈值与置信过滤
为避免低置信样本污染代理缓存,采用数据驱动的自适应阈值 (附录A),通过最小化ID/OOD分数的类内方差确定最优阈值:
其中 、 分别为阈值下ID样本的数量和平均分数,、 对应OOD样本。
引入置信边际 过滤模糊样本:
4.3.2 文本代理进化(公式 5-6、更新规则)
根据样本的初步分类结果,从词汇库中动态挖掘文本负样本,更新 :
4.3.3 视觉代理进化(公式 9)
基于更新后的文本代理,同步扩展和精炼视觉代理缓存:
4.4. 最终多模态分数融合(公式 11)
进化后视觉代理积累了丰富实例特征,调整权重分配为对称融合,突出视觉代理的局部判别力:
其中 ,最终通过 与阈值比较,输出ID/OOD决策(算法1完整流程)。

算法1是CoEvo框架的核心执行流程,以“初始化-迭代适配-决策输出”的闭环逻辑,实现零样本OOD检测,全程无需训练和标注,仅依赖测试样本动态优化。流程始于初始化:先从ID标签集生成固定的正文本代理队列,从外部词汇库采样与ID无交集的负标签,构建初始负文本代理队列;再基于和初始化正/负视觉代理队列、,为后续进化奠定基础。核心迭代环节针对每个测试样本展开:首先通过公式(1)和(3)分别计算初始文本分数和视觉分数,按公式(4)融合为初步多模态分数;接着计算自适应阈值,结合置信边际筛选高置信样本——分数高于判定为ID,低于判定为OOD,边际内样本跳过更新;随后ID样本挖掘远语义负文本(公式6)更新,并将视觉特征插入对应队列,OOD样本挖掘近语义负文本(公式5)更新,插入队列。最后,重新计算进化后的文本和视觉分数,按公式(11)融合为最终分数,输出ID/OOD决策。整个流程通过“分数计算-样本筛选-代理更新-分数重算”的循环,实现双模态代理的动态协同进化,保障检测鲁棒性。
实验
5.1. 实验设置
5.1.1 数据集
ID 数据集:ImageNet-1K(1000 个类别)。
OOD 数据集:
标准基准:iNaturalist、SUN、Places、Textures;
OpenOOD 基准:Near-OOD(SSB-hard、NINCO)、Far-OOD(iNaturalist、Textures、OpenImage-O);
不平衡场景:ID 与 OOD 样本比例为 1:100、1:10、1:1、10:1、100:1。
5.1.2 实现细节
骨干网络:CLIP ViT-B/16(视觉编码器);
超参数:视觉队列长度 L=10,温度系数 τ=0.01,融合权重 λ=0.8,新增负样本数 N=5,注意力锐度 β=5.5;
硬件:单 NVIDIA RTX 3090 GPU,批次大小 128。
5.2. 主要结果
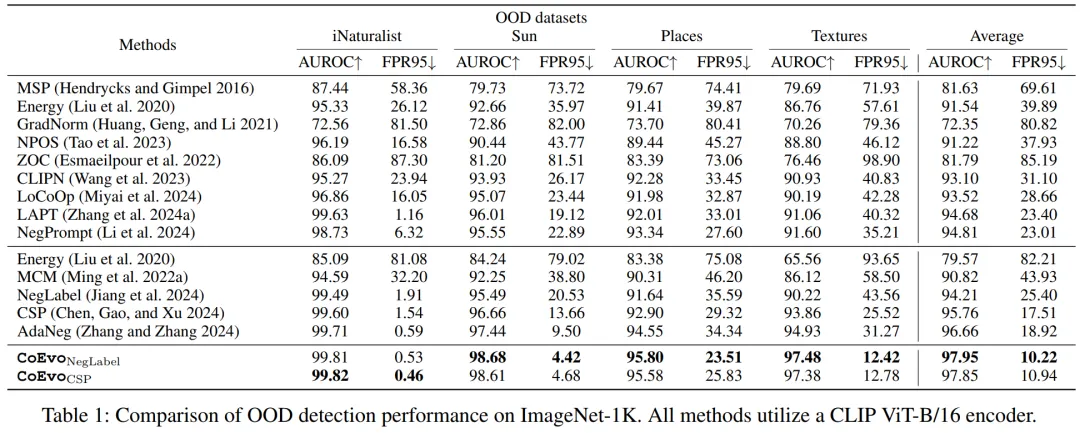
5.2.1 ImageNet-1K 基准(表 1)
CoEvoNegLabel 平均 FPR95=10.22%,AUROC=97.95%,较最优基线 FPR95 降低 45.98%,AUROC 提升 1.33%;
在 4 个 OOD 数据集上均实现最优性能,如 iNaturalist 的 AUROC 达 99.81%,FPR95 仅 0.53%。
5.2.2 OpenOOD 基准(表 2)
Near-OOD 场景:CoEvoCSP 的 FPR95=66.88%,AUROC=74.65%,略低于 AdaNeg 但保持竞争力;
Far-OOD 场景:FPR95=14.47%,AUROC=96.70%,显著优于所有基线;
ID ACC=67.36%,超越所有无训练基线。

5.3. 消融实验与分析
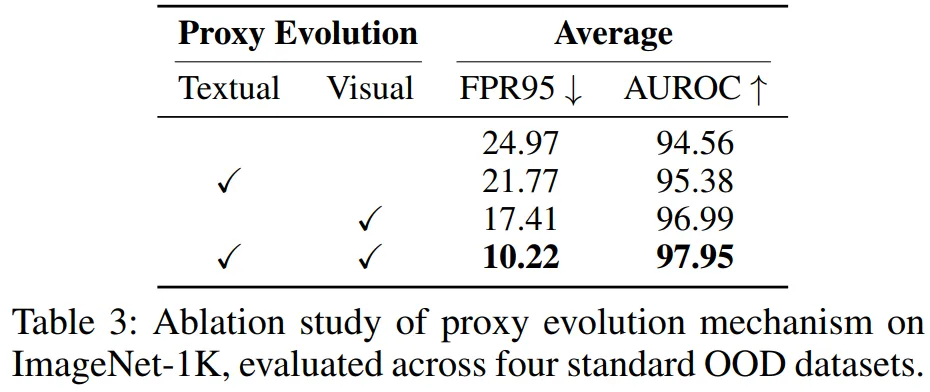
5.3.1 代理进化的贡献(表 3)
仅文本进化:FPR95=21.77%,AUROC=95.38%;
仅视觉进化:FPR95=17.41%,AUROC=96.99%;
双模态协同进化:FPR95=10.22%,AUROC=97.95%,验证双向适配的必要性。
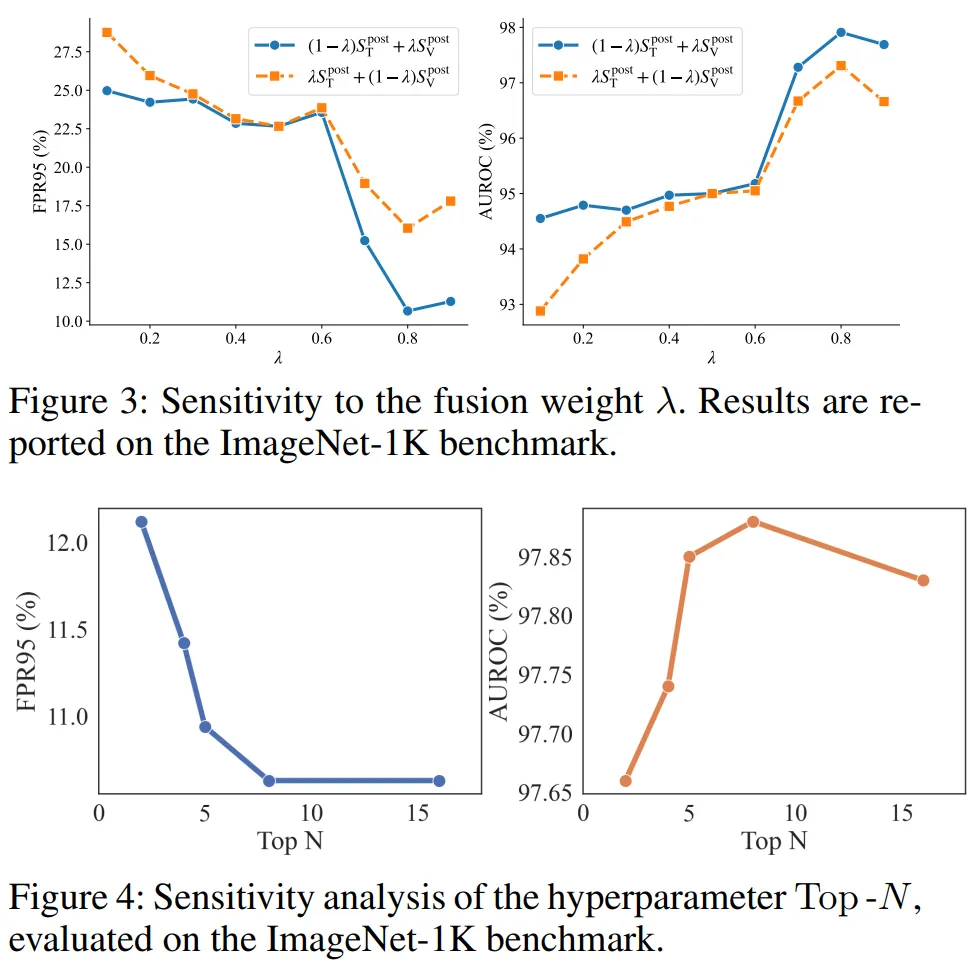
5.3.2 超参数敏感性(图 3-4、表 5)
融合权重λ:在 0.8 时性能最优,平衡视觉适应性与文本稳定性;
新增负样本数 N:N=5 时性能饱和,过大易引入冗余噪声;
队列长度 L:L=10 时最优,过长导致样本过时,过短缺乏多样性。

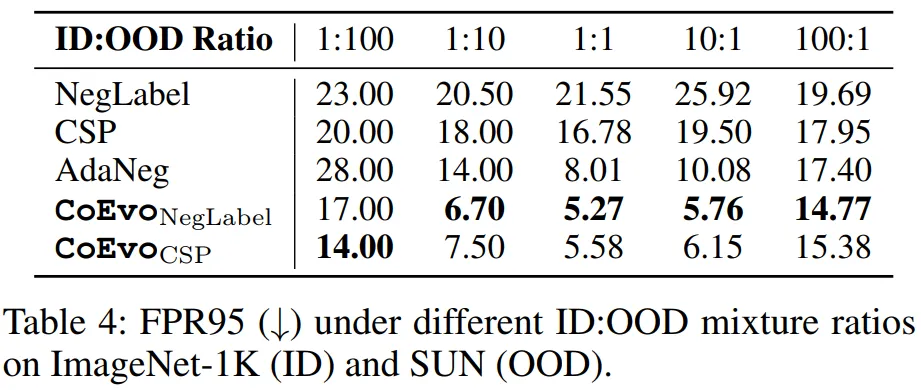
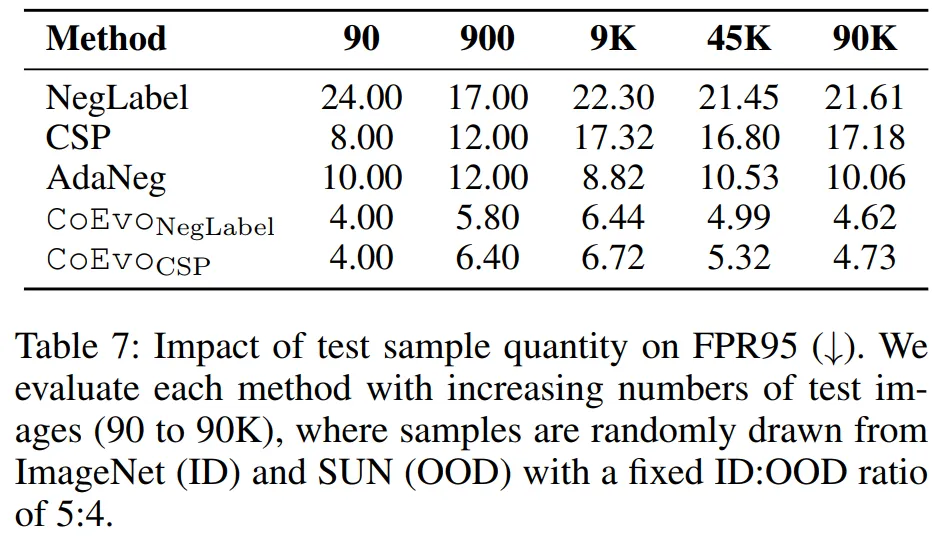
5.3.3 鲁棒性验证(表 4、7)
数据不平衡:所有比例下 FPR95 均低于基线,极端比例(100:1)时仍保持 14.77%(CoEvoNegLabel);
测试集大小:仅 90 个样本时 FPR95=4.00%,随样本量增加性能持续提升,验证动态适配的 scalability。
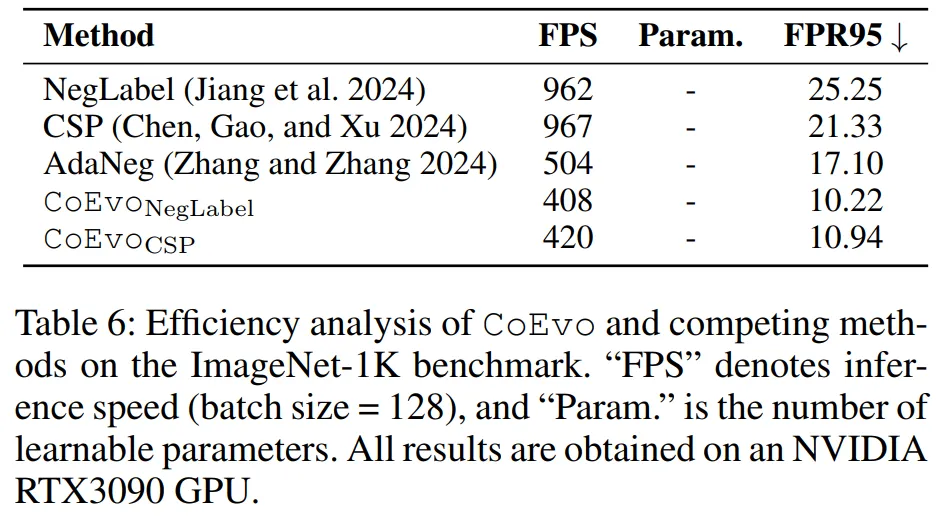
5.3.4 效率分析(表 6)
CoEvoNegLabel 的 FPS=408,虽低于 NegLabel(962)和 CSP(967),但显著优于 AdaNeg(504),且性能提升远超效率损失;
无额外可学习参数,部署友好。
总结
论文针对视觉-语言模型零样本OOD检测中固定文本负样本的缺陷,提出跨模态代理协同进化框架CoEvo。核心创新在于测试时动态构建语义对齐的双模态代理缓存,通过代理对齐协同进化机制,实现文本与视觉代理的双向适配:文本负样本依据测试图像视觉特征动态挖掘,视觉代理则吸收高置信样本迭代精炼。同时,设计分数进化策略,初始侧重文本语义稳定性,进化后侧重视觉局部判别力,动态融合双模态分数。实验以 ImageNet-1K 为 ID 数据集,在 iNaturalist、SUN 等 OOD 数据集及 OpenOOD 基准中验证,CoEvo 显著超越现有负标签方法,AUROC 提升 1.33%,FPR95 大幅降低,且在数据不平衡、不同测试集规模下表现稳健。该方法无需额外训练和标注,兼顾性能与部署效率,为开放世界 OOD 检测提供了新的有效思路。
--- END ---
编辑|阿超
*本文为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。*本文信息旨在传播和学术交流,若您认为文章内容或图片涉及侵权,请公众号私信或菜单栏点击【联系小编】与我们联系,我们会第一时间进行处理。
点击上方“AI启智汇”,关注我们
持续获取分享
AAAI2026|通用多模态图像融合框架!厦大灯提出SMC-Mamba:结合Mamba与混合专家机制,多类融合任务表现优秀
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【数字经济】数字农业、智慧农业、农业AI,有何区别?
- 福建省海洋与渔业执法总队闽中执法支队开展“商渔共治”海上联合巡航执法专项行动
- 产业项目推荐:智慧渔业项目合作说明
- 福建省现有规模以上林业企业超过3000家,境内外上市林业企业24家
- 省人大代表,茂名市茂南三高渔业发展有限公司总经理李瑞伟:借助媒体+的力量,为每一个中国人送上一条茂名罗非鱼!
- 南京林业大学招收博士生
- 漳州市海洋与渔业执法支队招聘14人!
- 无人机赋能广东海洋养殖,开启智慧渔业新篇章
- 阳江现代渔业产业园项目备案通过,总投资97915.81万元
- 项目上新丨畜牧业/医生注意啦:参与调研,最高可得60000积分!
