SMART AGRICULTURE · DATA ALIGNMENT智慧农业中的不同图层,如何对齐?
当遥感、土壤、气象、温室气体与计算机视觉在同一块田里相遇——这是一场关于坐标、尺度、时间与「支撑」的精密谈判。本文拆解智慧农业数据融合背后那层最容易被忽视、却决定一切的基础设施。
5 LAYERS5 DIMENSIONS≈18 MIN READ想象一块种着玉米的农田,正中央有一个 30 × 30 米 的方格。五种数据「同时」凝视着它——
卫星说它的反射率属于上周二那一景影像;土壤数据库说这里的有机碳来自三年前在田角采的一支土钻;气象再分析说这格属于一个 9 公里见方的网格单元,温度是整片流域的平均;田边的通量塔说,此刻随风飘来的二氧化碳,源区是一片随风向不断变形的「足迹」;而昨天无人机拍下的影像,则以亚厘米的精度数清了每一株苗。五种数据都自称在描述「这一块」,但它们对「哪里」「何时」「多大」「测的是什么」各执一词。在把它们叠成一张可供模型学习的「数据立方体」之前,必须先让它们——对齐(alignment)。
对齐,是智慧农业里最沉默、也最关键的一道工序。它失败时不会报错,只会让后续每一个「智能决策」悄悄偏移。
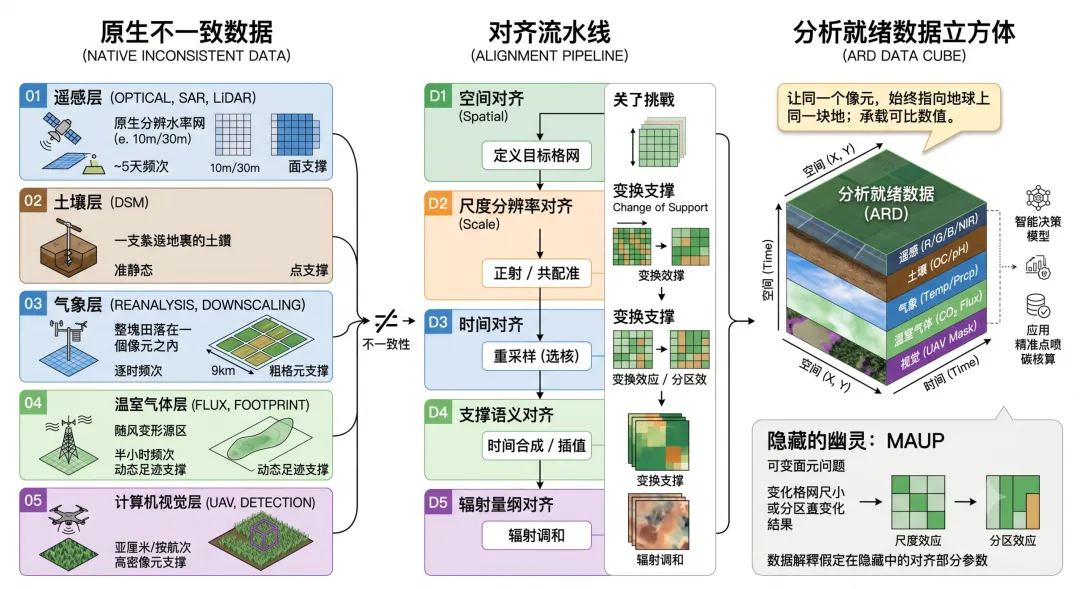
什么是「图层对齐」?
在 GIS 里,最朴素的对齐是地理配准(georeferencing):给一张没有坐标的栅格赋予真实世界的经纬度,让它能与其他图层正确叠加。但在智慧农业的语境下,「对齐」远不止于把图片摆正。它的真正目标是:
「让同一个像元,在不同图层、不同时间里,始终指向地球上同一块地;并且它所承载的数值,来自可比的时刻、可比的面积、可比的物理量。」
这正是 NASA「调和的 Landsat 与 Sentinel-2(HLS)」等分析就绪数据计划的核心追求——只有当同一像元跨时间始终对应同一地块、不因错位而漂移,时间序列才能被可靠地读取,多源影像才能堆叠进一个时空数据立方体。
要达到这个状态,需要在五个维度上分别完成谈判。它们彼此独立,又必须同时成立。
D1空间对齐Spatial / Geometric统一坐标参考系(CRS),通过地面控制点、正射校正与影像共配准,把每一层放到正确的经纬度上。衡量好坏的,是控制点残差均方根(RMSE)。
D2尺度与分辨率对齐Scale / Resolution把 10 米、30 米、9 公里的不同像元,重采样到同一个目标格网。选最近邻、双线性还是立方卷积,会改变结果——这背后藏着「可变面元问题」。
不同传感器的重访周期不同(Sentinel-2 约 5 天、Landsat 16 天、再分析逐时)。需要时间合成、插值或调和,让各层落在可比的时间窗内。云遮挡造成的空缺也要在此填补。
D4支撑与语义对齐Support / Semantic「支撑」(support)指每个观测实际代表的那块面积:一支土钻是点,一个像元是方块,一座通量塔是随风变形的源区。把它们叠在一起,必须意识到它们度量的根本不是同一种东西。
D5辐射与量纲对齐Radiometric / Unit不同传感器的定标差异,会让同一片作物算出不一致的 NDVI。需要辐射归一化、跨传感器交叉定标,并把各层物理量换算到统一量纲,数值才真正可比。
逐层剖析:每一层的「对齐之痛」
五种图层各有难处。下面按它们进入智慧农业管线的典型顺序,逐一拆解。
遥感是智慧农业的「眼睛」,但它从来不是一只眼睛。光学影像看光谱、SAR 穿云看结构、LiDAR 量高度,三者互补,却也各说各话。把它们融合,要先解决几何与辐射的双重对齐。
几何上,需要正射校正消除地形与视角畸变,再用控制点做共配准。一项覆盖 950 余篇文献的综述指出,多源遥感的无缝融合需要同时满足:相同的获取时间、空间共配准、真正射、一致的分辨率或信息量、辐射一致性,以及光谱波段覆盖的对应。值得一提的是,把 Sentinel-2 全球参考影像作为基准来重新处理 Landsat,正是为了提升其绝对定位精度,让整个全球档案在空间与时间上互操作——同一像元长期指向同一地块。
融合本身又分层级:像元级(如全色锐化,兼顾空间细节与光谱保真)、特征级(最常用)与决策级。近年的深度学习则更进一步——用注意力机制在隐空间里动态对齐多分辨率、多模态输入,而非死板地逐像元配准。
土壤的对齐之痛,源于它「天生离散」。它的真值往往来自一支支扎进地里的土钻——是点;而要画成连续的图层,必须借助遥感、地形、气候等连续的协变量,用机器学习去推断点与点之间。这正是数字土壤制图(DSM)的核心。
这里至少有两重错配。其一是支撑错配:土钻代表的是「土体(pedon)」尺度,协变量却是像元尺度,模型要在两者间架桥。实践中,研究者会把几百个不同来源的协变量统一重采样到同一分辨率与同一坐标系(例如 3 米、WGS84 UTM)——这正是「对齐」的字面操作。
其二是时间错配:曾有研究的土样采于 2012 年,可用影像却只能取 2013 年,研究者不得不专门验证两年地表状况是否可比。此外,土壤属性的空间自相关程通常只有 ≤100–300 米,这暗示土壤图层的像元尺寸最好与之匹配,过粗则抹平真实变异。
换句话说,土壤层的对齐,不只是「摆正」,更是一次跨尺度、跨时间的统计推断。
03气象层
REANALYSIS · DOWNSCALING气象层的尴尬在于「太粗」。全球再分析数据 ERA5 的分辨率约 0.25°,ERA5-Land 约 0.1°(近 9 公里)。对一座流域尚可,对一块几公顷的田,整块田常常落在一个像元之内——它得到的温度、降水,是周边好几平方公里的平均值。
同时还有支撑错配:地面气象站测的是点,再分析给的是格元,二者本就代表不同的空间尺度,这种差异本身就是误差来源之一。
解法是降尺度(downscaling):简单的可用双线性插值把粗格网重采样到精细网格;进阶的则借地表温度、NDVI、高程、坡度等高分辨率协变量,用集成学习甚至生成式 AI,把 0.1° 的气温降到 1 公里、把降水从 24 公里 / 逐时降到 2 公里 / 10 分钟。降尺度让气象层终于能和遥感、土壤站在同一张网格上。
这一层最反直觉。涡度相关通量塔能连续测量农田与大气间的 CO₂、CH₄ 交换,是碳核算的金标准。但一座塔测到的气体,并非来自一个规整的方格,而是来自一片「足迹(footprint)」——随风向、风速、大气稳定度实时变形的源区。
⌖ 这意味着:要把一座塔的读数与卫星像元或模型格元对齐,不能直接「点对格」,而要做足迹加权——把足迹覆盖范围内各地块的贡献按权重叠加,再与遥感指数比较。
研究因此反复强调「足迹感知(footprint-aware)」:在异质景观中,足迹的时空动态会带来可观的代表性偏差。例如对一片混作的农林系统,仅由足迹变化引入的长期通量不确定性就可达 15–20%。一片均一的玉米地代表性较高,而破碎景观则低得多。
把这种「会呼吸、会移动」的观测,上推到 FLUXNET、AmeriFlux 这类被广泛用来训练遥感—机器学习模型的格网数据时,对齐是否诚实,直接决定了碳通量产品的可信度。
无人机让农业视觉进入「单株级」精度,也带来一种新的对齐:把深度学习检测框里的「这一株苗 / 这一株草」,从图像的像素坐标,精确投影到地球的世界坐标。
起点是正射镶嵌(orthomosaic):通过自动匹配、几何校正与正射投影,把数百张航片拼成一张带坐标的大图,其精细度由地面采样距离(GSD)决定,可达亚厘米。要让不同航次、不同相机的成果彼此严丝合缝,关键是地面控制点(GCP):仅靠它,多期影像就能在相对空间里达到厘米级对齐;若要绝对精度,则用 RTK / PPK 把定位推到 1 厘米量级。
一旦影像被正确地理配准,每一株作物、每一棵杂草都能拥有自己的 GPS 坐标——红点标出的杂草可直接导出成处方图,驱动机器精准点喷。在 AgroVisionNet 这类系统里,CNN-Transformer 主干还会接入一个融合层,把时间对齐后的环境传感器读数与视觉证据一并决策。
视觉层提醒我们:像素空间与地理空间之间,始终隔着一道必须被显式跨越的鸿沟。
| 图层 | 典型原生分辨率 | 时间频次 | 测量「支撑」 |
|---|
| 遥感·光学 | | | |
| 遥感·Landsat | | | |
| 土壤·DSM | | | |
| 气象·ERA5-Land | | | |
| 温室气体·通量塔 | | | |
| 视觉·无人机 | | | |
六行数据想描述同一块田,分辨率却跨越六个数量级、时间从半小时到「准静态」、支撑从一个点到一片会移动的足迹。对齐,就是把这张表「压平」成一个统一坐标系。
走向统一:公共网格与数据立方体
把五层对齐,工程上有一条主流路径:先选定一个公共目标——统一的坐标参考系、统一的像元分辨率、统一的时间步长,再让所有图层向它收敛,最终堆叠成一个分析就绪数据立方体(ARD datacube)。
定义目标格网→正射 / 共配准→重采样(选核)→时间合成 / 插值→辐射调和→数据立方体这样的立方体已不是概念。瑞士数据立方体(Swiss Data Cube)把光学与雷达影像处理成分析就绪数据,覆盖全境、每日更新;面向欧洲的 EcoDataCube 则把 Landsat、Sentinel-2 与 30 米地形整合进一个时空一致的多维特征空间,专门服务大尺度时空机器学习。它们的共同前提,都是先完成系统性的时空调和。
顺序很重要:辐射定标、几何配准、重采样、时间合成必须各就其位。而深度学习提供了另一条思路——特征级对齐:不强求逐像元几何重合,而是用域对抗、对比学习、注意力等手段,在隐空间里让不同模态的特征分布彼此靠拢。某些方法甚至用「互学习」策略,对齐各子网络的概率熵与特征相似度,从而提升多模态遥感分类。
对齐之后,仍有幽灵
即使所有图层都完美地堆进了同一个立方体,一个幽灵仍未散去,它的名字叫——可变面元问题(Modifiable Areal Unit Problem, MAUP)。
早在 1934 年,Gehlke 与 Biehl 就发现:把数据聚合到更大的面元,变量间的相关系数会随之变大。1984 年,Openshaw 一针见血地指出,地理研究里所用的面元「本就是任意的、可改的,全凭聚合者的一念之间」。MAUP 有两副面孔——尺度效应(改变格元大小,结论随之改变)与分区效应(同样大小、换一种划法,结论也会变)。
这意味着:你把气象、土壤、遥感重采样到 30 米还是 250 米,算出来的「土壤碳与植被指数的相关性」可能截然不同。重采样选最近邻、双线性还是立方卷积,也会给坡度这类衍生量带来明显差异。对齐的每一个参数选择,都在悄悄塑造结论。
更根本的,是「支撑」的哲学。一支土钻、一座通量塔的足迹、一个卫星像元、一个气象格元,在本体论上是四种不同的面积。把它们对齐到同一张网格,是一次「变换支撑(change of support)」——这不是纯粹的工程操作,而是一种诠释,里面装满了被默认、却很少被言明的假设。
所以,成熟的做法不是假装幽灵不存在,而是坦诚地报告:每一层的支撑是什么、用了哪种重采样核、目标分辨率为何如此选择。必要时做多尺度敏感性分析,让 MAUP 从陷阱变成理解空间异质性的工具。
对齐,是每一个「智能决策」脚下那层看不见的地基。
它把分辨率跨越六个数量级、支撑形态各异、获取于不同时刻的图层,谈判成一张可以共同推理的网格。地图只在我们忘记「它当初是如何被对齐」时,才会开始说谎。智慧农业真正的智慧,或许不在模型有多深,而在它是否还记得——每一个像元背后,那场关于坐标、尺度、时间与支撑的、诚实的谈判。
NASA HLS《Harmonized Landsat Sentinel-2》| Tandfonline (2024)《多传感器多平台遥感数据融合综述》| McBratney 等《scorpan 数字土壤制图》框架| Nature Sci. Data《Swiss Data Cube》& PeerJ《EcoDataCube.eu》| AmeriFlux / FLUXNET 通量足迹代表性研究(Chu 等, 2021)| Kljun 等《Flux Footprint Prediction (FFP)》| Openshaw (1984)、Gehlke & Biehl (1934)《可变面元问题》| MDPI Sustainability《ERA5 气温降尺度》| GigaScience《无人机作物编目与 GCP 配准》。本文为科普性综述,技术细节请以原始文献为准。图层配色仅为阅读引导。若你正在搭建农业数据立方体,欢迎把你的「对齐之痛」留言告诉我们。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
