零样本功能基因组学
零样本功能基因组学(Zero-Shot Functional Genomics)是零样本学习(Zero-Shot Learning, ZSL)与功能基因组学交叉形成的前沿领域,核心是在目标生物实体/场景完全无标注训练数据的前提下,通过知识迁移预测基因、基因组元件、遗传变异、细胞类型乃至物种的生物学功能,是解决功能基因组学领域“标注数据极度稀缺”痛点的核心技术路径。
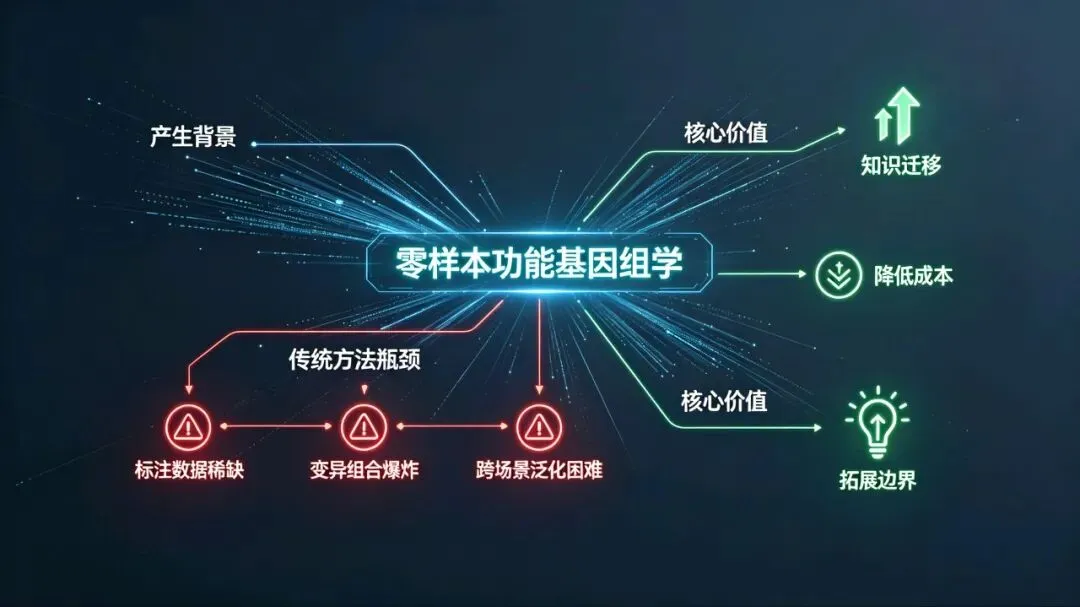
一、核心背景与产生动因功能基因组学的核心目标是解析基因组中所有元件的生物学功能,但传统基于监督学习的方法高度依赖大规模标注数据,面临多重难以突破的瓶颈:
1. 标注数据极度稀缺
人类基因组中98%为非编码区域,绝大多数元件的功能尚未被实验注释;罕见细胞类型、疾病特异状态、非模式生物的功能组学数据获取成本极高、样本量极少。
2. 变异的组合爆炸
遗传变异的可能组合数量远超实验验证的极限,无法通过湿实验逐一测定每一种突变的功能效应。
3. 跨场景泛化需求强烈
生物学研究常需要将模式生物、常见组织的功能知识迁移到非模式生物、罕见组织或疾病场景,传统模型无法实现跨类别泛化。
零样本功能基因组学正是为突破上述局限而生,其核心价值是用已有的功能知识推断完全未知的生物实体功能,大幅降低功能基因组研究的实验成本,拓展研究边界。
二、核心原理与技术范式
零样本学习的核心逻辑是构建共享语义空间作为“知识桥梁”,将训练集中已标注类别的知识,迁移到训练中从未出现的“未见类别”。在功能基因组学中,根据语义空间的类型不同,主流技术范式分为四类:
1. 序列自监督预训练范式
这是基因组大模型时代最核心的零样本技术路线,其底层假设是:DNA/RNA/蛋白质的序列本身就是生命的通用语言,功能信息全部编码在序列中。
- 技术路径:在海量无标注基因组序列上进行自监督预训练(如掩码核苷酸预测),让模型学习基因组的“序列语法”——包括进化保守模式、调控元件特征、序列-功能映射规律。
- 泛化逻辑:模型掌握了通用的序列功能规则后,即使面对完全未见过的序列、细胞类型或物种,也能通过序列模式直接推断功能,无需额外标注数据微调。
- 代表方向:DNA基础模型(如Evo、Genomics-FM)、蛋白质大模型的零样本功能预测。
2. 生物属性引导范式
该范式以标准化的生物功能属性作为中间语义空间,实现知识迁移。
- 技术路径:将基因本体(GO)、KEGG通路、表型术语、分子功能描述等作为共享属性标签,训练模型学习“基因组特征→功能属性→功能类别”的两层映射。
- 泛化逻辑:对于未见的基因/基因组元件,只要能提取出对应的属性特征,就能通过属性空间匹配到对应的功能类别。
- 典型应用:新基因功能注释、非编码RNA功能预测。
3. 跨域特征解耦范式
针对跨组织、跨物种、跨生理条件的功能预测场景,核心是剥离领域特异特征,提取通用功能特征。
- 技术路径:通过特征解耦、域适应算法,将基因组特征拆解为“与功能相关的通用特征”和“与物种/组织/条件相关的域特异特征”,仅基于通用特征进行功能预测。
- 泛化逻辑:通用功能特征在不同生物场景下具有保守性,因此可以迁移到未见的域中。
- 代表方向:跨细胞类型的顺式调控预测、跨组织的表观修饰预测。
4. 知识增强推理范式
结合生物医学知识图谱、科学文献大模型,通过知识推理实现零样本功能预测。
- 技术路径:将已有的生物学知识(基因互作、通路关系、文献结论)构建为知识图谱或检索库,通过检索增强生成(RAG)、图推理等方式,基于已知实体的关联关系推断未见实体的功能。
- 典型应用:罕见变异致病性推断、基因调控因果网络零样本构建。
三、代表性技术与研究进展
1. Evo(Science 2024封面):70亿参数基因组基础模型,在270万种原核生物和噬菌体全基因组上预训练,支持131kb长序列单核苷酸分辨率建模。首次实现DNA、RNA、蛋白质三个层级的零样本功能预测,在突变适应度预测、非编码RNA功能预测等任务上,性能媲美甚至超越领域专用模型。
2. GET模型(Nature 2025):通用表达转换器,基于213种人类细胞类型的染色质与表达数据训练,零样本预测未见细胞类型的基因表达,可精准解析转录因子互作机制,应用于白血病等疾病的易感基因调控研究。
3. Genomics-FM(2024):基因组通用基础模型,通过“基因组词汇”预训练框架,实现跨物种、跨组织的零样本功能泛化,覆盖基因组注释、表观组预测、变异效应评估等十余类功能基因组任务。
4. CREaTor(Genome Biology 2023):注意力驱动的顺式调控建模模型,无需先验的调控互作知识,即可零样本推广到新细胞类型,解析最长2Mb范围内的顺式调控元件-基因对应关系。
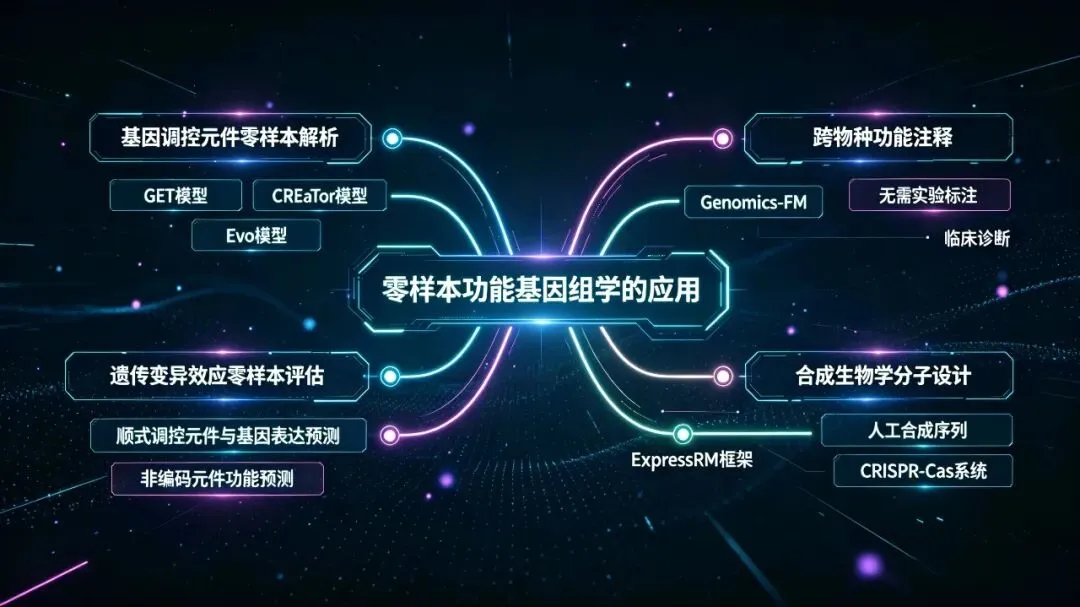
四、核心应用场景
1. 基因调控元件零样本解析
- 顺式调控元件与基因表达预测:无需新细胞类型的调控组学标注,即可预测未见细胞类型中的增强子-基因互作关系、基因表达水平。例如GET模型可零样本预测213种之外的人类细胞类型的基因表达,并解析转录因子调控网络;CREaTor模型无需额外训练,即可建模新细胞类型的顺式调控模式。
- 非编码元件功能预测:零样本预测非编码RNA、启动子、增强子的功能活性,无需该类元件的专用标注数据集。例如Evo模型可同时实现非编码RNA、调控DNA的零样本功能预测,覆盖中心法则全层级。
2. 遗传变异效应零样本评估
无需特定变异的实验标注,即可预测罕见变异、新发突变、组合突变的功能影响(包括致病性、表达调控效应、蛋白适应度等),是临床基因组诊断、罕见病研究的核心工具。其原理是通过序列保守性、结构约束等通用特征,推断变异对分子功能的扰动程度。
3. 跨物种功能注释
对于新测序的非模式生物,无需其自身的功能组学数据,即可直接迁移模式生物的功能知识,完成全基因组的功能元件注释、基因功能预测。例如Genomics-FM可跨多个物种实现零样本基因组注释,性能优于专用模型。
4. 表观组与表观转录组零样本预测
针对难以检测的表观修饰场景,无需目标组织/条件的表观组数据,仅通过基因组序列或转录组数据即可预测表观修饰谱。例如ExpressRM框架仅利用RNA-seq数据,就能零样本预测从未观测过的组织/生理条件下的RNA修饰位点,性能与依赖同条件标注的监督模型相当 。
5. 合成生物学分子设计
零样本预测人工合成序列的功能活性,无需高通量实验筛选。例如Evo可零样本预测原核启动子-核糖体结合位点组合的表达强度,设计全新的CRISPR-Cas系统与转座元件,直接指导合成生物学实验设计。
五、农业应用场景
1. 跨物种零样本基因组功能注释
核心逻辑:通过多物种基因组预训练模型学习植物通用的序列-功能规则,直接对未参与训练的物种进行功能注释,无需目标物种的任何标注数据。
- PlantCaduceus(康奈尔大学,PNAS 2025):基于16种被子植物基因组预训练,仅用拟南芥的少量标注数据微调后,即可迁移到分化1.6亿年的玉米(未参与预训练);其中翻译起始位点预测性能提升7.23倍,剪接供体位点预测提升1.45倍,显著优于此前的领域专用模型 。
- GeneCAD:基因组注释基础模型,在训练集外的核桃、咖啡、普通烟草、野生烟草、栽培烟草5个物种中,零样本完成基因结构注释,可适配异源四倍体基因组 。
- 非编码调控元件注释
- AgroNT(48种可食用植物预训练,2025):零样本预测木薯等作物的基因间增强子区域,精度达到主流监督模型水平,无需目标物种的表观组学标注 。
2. 零样本遗传变异功能效应评估
这是当前农业领域落地性最强的方向。核心逻辑:基于预训练模型学习的序列进化约束规律,通过参考等位基因与替代等位基因的对数似然比(LLR),零样本判断变异的功能影响,无需变异的实验表型标注。
- 因果变异精细定位
PlantCaduceus可在无玉米变异标注的前提下,精准识别甜玉米Su1位点的已知因果变异;整合GWAS结果时,零样本评分可显著缩小候选变异范围,辅助快速克隆性状基因 。
- 有害/优异变异批量筛选
- AgroNT的零样本评分可显著富集拟南芥、水稻群体中的低频有害变异,以及GWAS性状关联变异,性能优于传统基于多序列比对的保守性评分(phyloP、phastCons) 。
- PlantCaduceus预测的有害变异,其群体次等位基因频率仅为传统方法的1/3,对功能丧失型变异的识别精度更高 。
- 通用基因组模型Evo 2(200亿参数)无需植物专项微调,即可零样本区分拟南芥育性基因SPRI1/SPRI2的功能获得、功能缺失与中性变异,可直接用于野生种质资源的变异初筛。
- 农业价值
可将GWAS候选区间的变异筛选效率提升数倍,大幅缩短作物优异等位基因挖掘与基因克隆的周期,尤其适用于野生种质资源的快速评价。
3. 跨品种/跨组织的调控与表达零样本预测
核心逻辑:剥离品种、组织的特异序列特征,基于通用调控序列规则,预测未见品种、未见组织的基因表达与表观修饰状态。
- 针对六倍体小麦基因组复杂、跨品种调控预测难的问题,DeepWheat模型整合序列与表观组特征,可跨小麦品种零样本预测基因表达水平与调控元件活性;验证发现插入缺失(indel)对基因表达的影响显著强于单核苷酸变异(SNP)。
- AgroNT可零样本预测启动子、终止子的表达强度,以及不同组织的基因表达特异性,无需对应组织的转录组标注数据。
4. 合成生物学场景的零样本功能预判
核心逻辑:预训练模型掌握了植物基因的序列功能语法,可零样本评估人工合成序列的功能活性,大幅减少实验筛选工作量。
- PlantGFM(华中农业大学+崖州湾国家实验室,2026):基于12种植物的108.4亿核苷酸预训练,支持64kb长序列建模,可零样本评估人工设计基因、合成启动子的功能合理性;该模型从头设计的全新基因已通过实验验证,可在植物细胞中正常表达,为作物合成生物学育种提供了设计工具。
六、核心挑战与局限
1. 分布外泛化瓶颈:当未见样本与训练数据的进化距离、序列特征差异过大时(如远缘物种、极端结构变异),模型预测性能会显著下降,是当前零样本基因组学最核心的技术难题。
2. 语义空间偏差:作为知识桥梁的功能注释(如GO、通路)本身存在研究偏差——研究充分的基因/功能注释更完善,会导致零样本预测向已知功能倾斜,对全新功能的发现能力有限。
3. 可解释性不足:大模型驱动的零样本预测多为黑箱输出,难以定位决定功能的关键序列位点、调控机制,限制了其在临床诊断和实验指导中的落地。
4. 评估体系不统一:不同研究对“零样本”的定义、测试集构建标准差异较大,缺乏统一的基准测试与实验金标准,难以横向对比方法性能。
七、发展趋势
1. 多模态融合:整合序列、三维基因组结构、多组学谱、科学文献等多模态信息,构建更鲁棒的共享语义空间,提升跨场景零样本泛化能力。
2. 因果零样本学习:从统计关联预测走向因果机制推断,零样本识别功能的因果调控元件,而非单纯的序列-功能关联。
3. 干湿闭环迭代:构建“零样本预测→小规模实验验证→模型快速校准”的研究闭环,用极低的实验成本持续优化零样本预测精度,加速功能基因组发现。
4. 可解释性增强:开发可解释零样本框架,精准定位功能相关的关键序列基序、位点,直接指导下游实验设计。
(文图 :智农拾光、平豆包)