【蛋白酶改造与设计】沈阳农业大学联合蒙牛乳业团队发表综述:食品行业中基于人工智能的精准蛋白酶改造技术
- 2026-06-20 16:35:35

AI驱动食品工业蛋白酶精准工程综述
1. 一段话关键概括
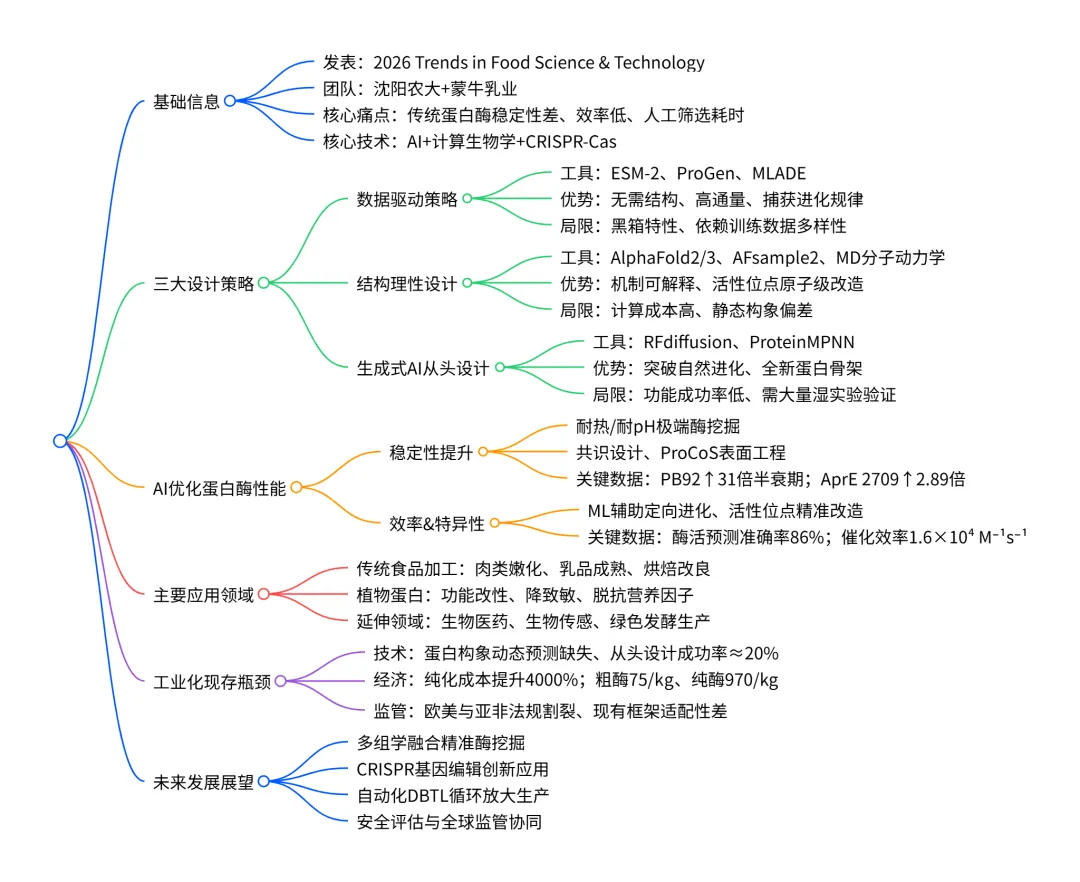
本文是沈阳农业大学联合蒙牛乳业团队于 2026 年发表在《Trends in Food Science & Technology》的综述论文,围绕AI 驱动食品工业蛋白酶精准工程展开系统综述,融合人工智能、计算生物学、CRISPR-Cas 基因编辑三大核心技术,划分数据驱动、结构理性设计、生成式 AI 从头设计三大蛋白酶研发范式并对比优劣;量化证实 AI 可显著提升蛋白酶热稳定性、pH 耐受性、催化效率与底物特异性(如 PB92 蛋白酶高温半衰期提升31 倍、碱性蛋白酶 AprE 2709 半衰期提升2.89 倍);覆盖食品加工、植物蛋白改性、生物医药、绿色制造等多元应用场景;同时剖析结构预测静态偏差、从头设计仅约 20% 功能成功率、下游纯化成本激增 4000%、全球监管体系碎片化等核心瓶颈,并提出多组学融合、CRISPR 创新、自动化 DBTL 循环、监管标准化四大未来发展方向。
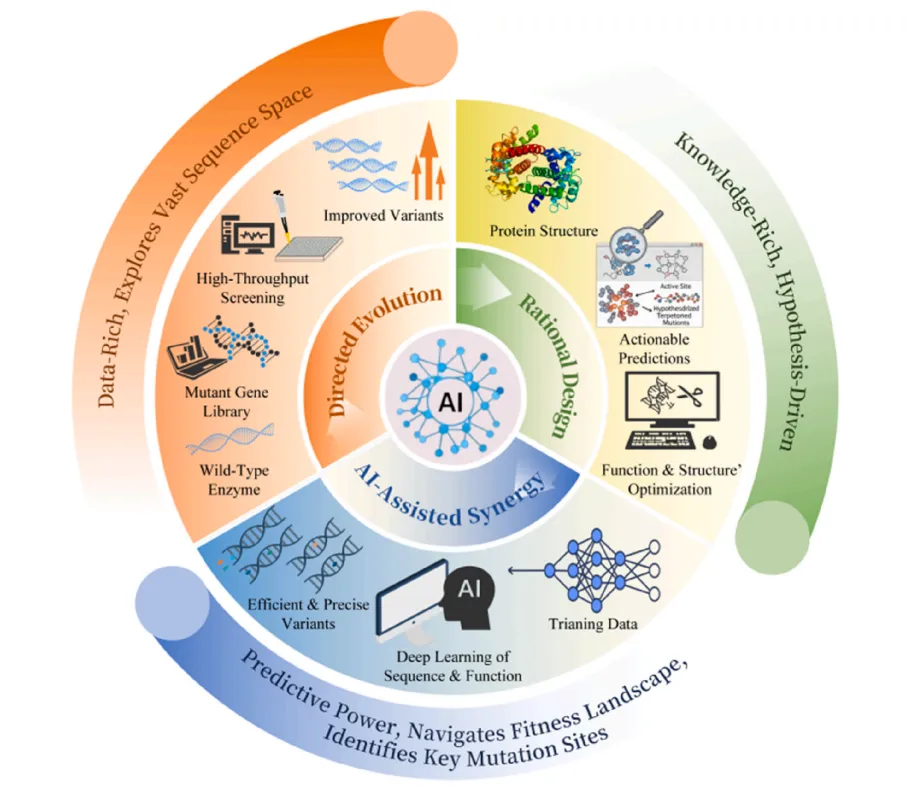
图1 现代蛋白酶工程的全新范式:数据、知识与智能的协同融合。注:该协同范式融合三大核心板块,相比传统单一策略方法,大幅提升设计效率与可拓展性。左侧橙色板块:依托海量数据的定向进化技术,通过高通量突变文库筛选与经验性适应性评估,探索庞大的序列空间;右侧绿色板块:基于理论知识的理性设计,借助三维结构与作用机制解析,以假设为导向开展功能优化;下方蓝色板块:人工智能驱动的预测协同体系,利用深度学习绘制序列-功能图谱、定位关键突变位点,减少实验工作量。整体工作流程:人工智能作为核心整合载体,持续将实验数据与结构知识相结合,指导蛋白质迭代优化与功能提升。
2. 思维导图
3. 详细总结(分点 + 表格 + 关键数字加粗)
一、研究背景与核心意义
1.行业痛点:传统蛋白酶存在热稳定性差、极端 pH 下易失活、催化效率低问题;传统定向进化依赖随机突变与人工筛选,周期长、成本高、无效突变占比高,难以适配食品工业严苛加工条件。
2.技术变革:AI、计算生物学、CRISPR-Cas的融合,颠覆蛋白酶研发模式,实现从天然酶修饰到全新蛋白酶从头创制的跨越。
3.研究价值:构建多组学 + 生成建模 + 基因编辑的AI 精准设计框架,兼顾理论创新与工业落地,同时明确食品酶安全设计原则与国际监管规范。
二、AI 驱动蛋白酶三大设计策略及对比
1. 策略核心介绍
•数据驱动(序列导向):依托定向进化、蛋白语言模型,无需蛋白三维结构,利用海量序列库智能筛选突变体,代表工具ESM-2、ProGen、MLADE。
•结构理性设计:基于 AlphaFold2/3 等结构预测工具,解析蛋白 3D 构象与催化机制,精准改造活性位点,新增AFsample2可模拟蛋白动态构象。
•生成式 AI 从头设计:借助 RFdiffusion 生成全新蛋白骨架、ProteinMPNN 匹配氨基酸序列,突破自然进化限制,可创制自然界不存在的功能蛋白酶。
2. 三大策略优劣对比表
设计策略 | 核心工具 | 核心优势 | 主要局限 |
数据驱动 | ESM-2、ProGen、MLADE | 高通量筛选、无需三维结构、捕获进化语义 | 模型黑箱、预测效果依赖训练数据多样性 |
结构理性设计 | AlphaFold2/3、AFsample2、MD 模拟 | 催化机制可解释、活性位点原子级改造精度 | 计算成本高、易存在静态构象预测偏差 |
生成式 AI 从头设计 | RFdiffusion、ProteinMPNN | 突破自然进化、可创制全新蛋白骨架与功能 | 功能成功率低、需大量湿实验验证 |
三、AI 对蛋白酶性能的精准提升
1. 稳定性强化(耐热 / 耐 pH)
•技术路径:极端微生物蛋白酶挖掘 +\\分子动力学 (MD)\\模拟、共识设计、ProCoS 表面工程、半理性定点突变。
•关键量化成果:
a.丝氨酸蛋白酶 PB92 高温半衰期提升 31 倍;
b.碱性蛋白酶 AprE 2709 经突变后,60℃半衰期提升 2.89 倍;
c.可实现低温催化效率18.3 倍提升、酶熔解温度提升 7℃。
2. 催化效率与底物特异性优化
•融合机器学习与分子动力学,酶活预测AUC=0.91、分类准确率 86%;
•改造后蛋白酶催化效率可达1.6×10⁴ M⁻¹s⁻¹;
•半理性设计可使蛋白酶催化活性最高提升 4.30 倍;
•可精准调控酶切位点,实现底物靶向识别,减少食品加工副反应。
四、多领域应用场景
1.传统食品加工
○肉类:选择性分解胶原蛋白,实现可控嫩化,减少苦味肽生成;
○乳品:定向释放 ACE 抑制肽、抗氧化肽,加速奶酪成熟、降低乳过敏原;
○烘焙:可控热失活特性,精准调控面筋网络,改善面团质地与成品比容。
2.植物蛋白改性:提升溶解性、乳化性与起泡性,去除抗营养因子,降解豆腥味相关蛋白,提升营养与感官品质。
3.延伸应用:生物医药(抗癌肽筛选、神经退行性疾病靶向治疗)、生物传感(MMP-2 检测限低至0.55 pg/mL)、绿色生物制造(发酵废物减排 30%、菌株筛选效率提升 10 倍)。
五、工业化落地核心瓶颈
1.技术瓶颈:AlphaFold 难以捕捉 94% 蛋白构象切换;生成式 AI 从头设计功能成功率仅约 20%;数据稀缺易引发模型过拟合。
2.经济瓶颈:下游纯化是主要成本短板,复杂纯化工艺可使成本提升 4000%;粗酶售价75 美元 /kg,纯化酶高达970 美元 /kg。
3.监管瓶颈:欧盟采用过程式监管归类为 GMO,亚非为产品式监管,全球标准碎片化;现有法规难以适配 AI 设计新型蛋白酶。
六、未来四大发展方向
1.研发从单一酶优化转向系统级代谢工程,构建微生物细胞工厂;
2.融合多组学与动态建模,提升食品基质中蛋白构象预测精度;
3.搭建自动化 DBTL 循环,结合 CRISPR 编辑实现实验室到产业化快速放大;
4.技术创新与全球监管标准协同,嵌入致敏性、毒性筛选,保障合规与公众认可。
4. 三个关键价值问题(不同侧重)
问题 1(技术侧重):AI 驱动蛋白酶工程包含哪三大设计范式,各自核心特点是什么?
答案:包含数据驱动、结构理性设计、生成式 AI 从头设计三大范式。①数据驱动:无需蛋白三维结构,依托蛋白语言模型与机器学习高通量筛选,短板是模型黑箱、依赖训练数据;②结构理性设计:基于 AlphaFold2/3 等解析蛋白静态 / 动态构象,可实现活性位点原子级精准改造,缺点是计算成本高、存在静态预测偏差;③生成式 AI:利用 RFdiffusion+ProteinMPNN 创制天然不存在的蛋白骨架,突破自然进化限制,但功能验证成功率低。
问题 2(应用侧重):AI 改造蛋白酶在食品工业有哪些核心应用及实际效益?
答案:①肉类加工:实现精准嫩化,避免肌纤维过度分解,减少苦味肽;②乳制品:定向生成生物活性肽、降低过敏原,替代传统高价凝乳酶;③烘焙:可控酶活改善面团弹性与成品质地;④植物蛋白:改良功能特性、去除抗营养因子、消除豆腥味,大幅提升植物基食品营养价值与适口性。
问题 3(产业侧重):AI 蛋白酶从实验室走向工业化的最大阻碍是什么?
答案:主要有三大阻碍:①技术层面:蛋白动态构象预测能力不足,生成式从头设计仅约 20%功能成功率,数字设计与实际性能差距大;②经济层面:下游纯化成本激增4000%,纯化酶售价远高于粗酶,限制规模化应用;③监管层面:全球法规不统一,欧盟与亚非监管框架割裂,且现有安全评估体系难以适配 AI 设计新型蛋白酶。
论文表格和图片信息
一、表格完整翻译
Table 1 AI 驱动蛋白酶设计策略的优势与局限
设计策略 | 核心工具及参考文献 | 主要优势 | 主要局限 |
数据驱动(序列导向) | ESM-2(Cui 等,2025);ProGen(Madani 等,2020);MLADE(Landwehr 等,2025) | 高通量;无需蛋白结构;可捕获进化语义特征 | 模型具有“黑箱” 属性;预测效果高度依赖训练数据的多样性 |
结构导向(理性设计) | AlphaFold2(Jumper 等,2021);AFsample2(Kalakoti & Wallner,2025);分子动力学模拟 | 可解释催化机制;活性位点改造具备原子级精度 | 计算成本高;易存在静态构象预测偏差 |
生成式 AI(从头设计) | RFdiffusion(Watson 等,2023);ProteinMPNN(Dauparas 等,2022) | 可突破自然进化限制,获得全新蛋白骨架与功能 | 功能成功率低;需大量湿实验验证 |
表 1 注释翻译:本表按技术逻辑对 AI 驱动设计策略进行分类,明确了核心计算工具,并总结了工业蛋白酶工程的验证要求。
•策略分类:本表按数据源和逻辑将设计策略分为三类。数据驱动方法使用序列数据,结构导向方法聚焦三维结构,生成式 AI 则创建全新蛋白骨架。
•ESM-2(进化尺度建模):该蛋白语言模型仅通过氨基酸序列即可预测结构和功能,从数百万条天然序列中提取生物学模式以指导设计。
•ProGen(生成式蛋白语言模型):该工具利用大语言模型生成功能性蛋白序列,证明了 AI 能够设计符合生物学规律但自然界中不存在的蛋白。
•MLADE(机器学习辅助定向进化):该框架使用预测模型指导定向进化,帮助研究人员比随机筛选更高效地搜索序列库。
•AlphaFold2 与 AFsample2:AlphaFold2 高精度预测静态蛋白结构。AFsample2 生成多种柔性状态,展示蛋白酶在反应过程中的运动和构象变化。
•RFdiffusion(从头骨架生成):该金标准工具通过固定特定位点(如催化三联体)构建全新蛋白支架,利用扩散过程生成超越自然进化的结构。
•ProteinMPNN(序列设计 / 逆折叠):该架构为特定蛋白结构匹配最优氨基酸序列,常与 RFdiffusion 配合使用,确保设计的蛋白能够正确折叠。
Table 2 近十年 AI 驱动蛋白酶工程的关键进展
研究时间(年) | 采用的 AI 技术 | 对蛋白酶开发的贡献 | 参考文献 |
2018 | 生成对抗网络(GANs) | 应用 GAN 生成二维蛋白距离图谱,用于从头三维结构设计 | (Anand & Huang,2018) |
2019 | 结构化 Transformer | 开发基于图的生成模型,从三维结构设计蛋白序列,确保高保真的结构 - 序列对应关系 | (Ingraham 等,2020) |
2020 | DeepCleave(卷积神经网络 + 迁移学习) | 提出首个仅通过序列即可预测蛋白酶底物和酶切位点的深度学习模型,无需手动特征工程 | (Li 等,2020;Li 等,2020) |
2021 | 机器学习辅助定向进化(MLADE) | 通过机器学习构建信息丰富的训练集,加速定向进化并提高蛋白工程效率 | (Wittmann 等,2021) |
2022 | AI 驱动系统发育分析、蛋白质组学指导的理性设计 | 通过 AI 驱动的系统发育分析和蛋白质组学指导的理性设计,从深海热液喷口发现并优化了一种新型碱性蛋白酶,该酶具有高热稳定性和宽 pH 耐受性 | (Chiu 等,2022) |
2023 | 蛋白图卷积网络(PGCN) | 开发基于结构和能量的图神经网络,用于蛋白酶底物特异性的预测和理性设计,实现定制化蛋白切割 | (Lu 等,2023) |
2023 | 数据驱动策略(机器学习 / 深度学习综述) | 基于对当前机器学习方法和数据集的系统调研,提出了用于酶热稳定性工程的综合数据驱动架构 | (Dou 等,2023) |
2025 | 机器学习指导的无细胞表达 | 整合机器学习建立快速酶工程工作流 | (Landwehr 等,2025) |
表 2 注释翻译:本表总结了从结构稳定性优化到功能创新的转变、计算与实验平台的协同效应,以及可持续蛋白酶生产的优化进展。
•研究目标演变:研究重点已从天然稳定性提升转向功能创新。早期研究主要改善蛋白酶的耐热和耐 pH 性能,而现代模型能够设计用于非天然反应的酶。
•技术协同:工程学现在将计算模型与 CRISPR 等实验工具相结合。这种反馈循环有助于更有效地筛选工业蛋白酶变体。
•生产影响:混合模型利用组学数据优化生产。这些方法在减少浪费的同时,确保酶产品符合工业安全标准。
•动态建模:新工具模拟蛋白质的运动和相互作用。AlphaFold3 等系统有助于预测酶在复杂食品环境中的表现。
Table 3 计算与 AI 驱动策略为食品和生物制造中蛋白酶应用提供的创新解决方案
研究时间(年) | 采用的 AI 技术 | 对食品与生物工业中蛋白酶应用的贡献 | 关键量化提升 | 参考文献 |
2016 | 共识设计 | 引入 ProCoS 方法(蛋白共识表面工程) | 保留 40% 的比活性 | (Shivange 等,2016) |
2017 | FireProt 热稳定性设计服务器 | 设计热稳定的卤代烷脱卤酶 Lin A | 熔解温度(Tm)分别提升 24℃和 21℃ | (Musil 等,2017) |
2018 | 共识引导的热稳定性设计 | 获得耐热烷烃生产酶,鉴定促进热稳定性的关键残基 | 42℃下十五烷产量提升 3.8 倍,酶的熔解温度提升 7℃ | (Shakeel 等,2018) |
2019 | 高压辅助酶解 | 高压辅助蛋白酶水解蚕豆分离蛋白,显著改善其功能特性和抗氧化活性,拓展食品应用 | 水解度(DH):~23.9%;起泡能力提升至~90.27% | (Noor,2019) |
2023 | 结构引导的理性设计 | 改造蛋白酶以提高其低温条件下的活性 | 10℃下催化效率(kcat/KM)提升 18.3 倍 | (Wang 等,2023) |
2023 | 中性蛋白酶筛选与应用 | 应用筛选得到的特异性中性蛋白酶,改善烘焙面团延展性,并在中性 pH 下嫩化鲜肉 | 无(定性筛选研究) | (Song 等,2023) |
2023 | 蛋白图卷积网络(PGCN) | 开发几何机器学习框架用于蛋白酶变体设计 | 测试准确率 > 90%,峰值 AUC 达 0.97 | (Lu 等,2023) |
2024 | 机器学习结合领域知识 | 建立数据驱动框架优化乳制品加工 | 马修斯相关系数中位数为 0.82(综述文章) | (Jox 等,2024) |
2025 | ProteinMPNN;AlphaFold;分子动力学(MD) | 深度学习框架显著改善人造肉和生物技术加工中所用蛋白的表达、稳定性和活性 | 催化效率提升 26 倍,可溶性产量提升 4.1 倍 | (Fu 等,2025) |
2025 | 机器学习辅助酶解 | 建立内标校准曲线法,鉴定并定量蚕豆水解物中的新型非胰蛋白酶肽 | 实现复杂蚕豆水解物中 3 种新型非胰蛋白酶肽的绝对定量 | (Manguy 等,2025) |
2025 | 人工智能用于抗癌肽发现 | 建立综合 AI 驱动框架,从特定蛋白酶水解的食品蛋白水解物中高效筛选抗癌肽,助力功能性乳制品和天然治疗剂开发 | 总结了 68 个抗癌肽模型,预测准确率 75%-99%;基于图的模型预处理时间减少 7 倍(综述文章) | (Wu 等,2025) |
表 3 注释翻译:
•N/A:表示综述文章或定性筛选研究,不适用特定动力学参数。
•对于组学和检测研究(如 Kussmann 等,2022),量化值指的是鉴定的靶标数量或精度指标,而非催化速率。
•缩写:ADO(醛脱甲酰加氧酶);DH(水解度);Tm(熔解温度);ACP(抗癌肽)。
•模型原理:纳入非蛋白酶模型的研究,以证明这些工程框架对蛋白酶设计的方法学可迁移性。
•指标解读:提升值表示生物催化任务的动力学或稳定性增强;对于组学和发现研究,指标代表靶标鉴定数量或模型准确率。
•行业范围:“生物工业” 特指生物医药和可持续化学品制造领域。
二、图片完整翻译
Fig. 1 现代蛋白酶工程新范式:数据、知识与智能的协同
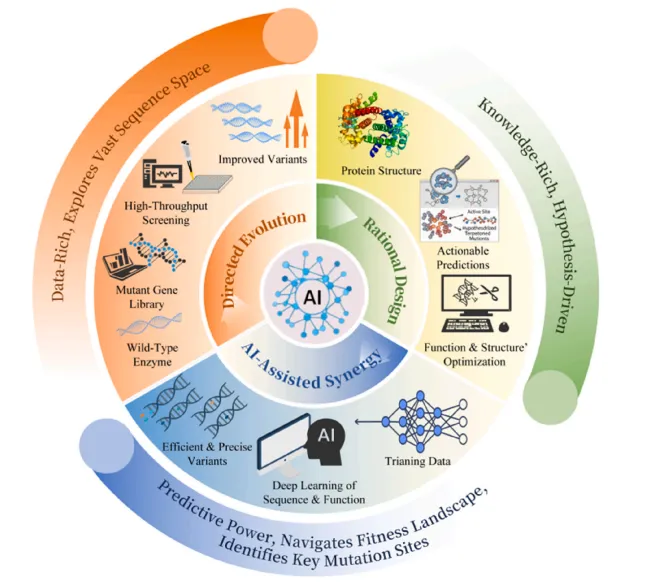
图注翻译:这种协同范式整合了三个核心领域,以超越传统单一策略方法,提升设计效率和可扩展性:
•橙色区域(左侧):数据丰富的定向进化,通过高通量突变文库筛选和经验适应性评估探索广阔的序列空间;
•绿色区域(右侧):基于知识的理性设计,利用三维结构和机制见解进行假设驱动的功能优化;
•蓝色区域(底部):AI 驱动的预测协同,利用深度学习绘制序列 - 功能图谱并精确定位关键突变位点,最大限度减少实验工作量;
•整体工作流:AI 作为核心整合者,持续将实验数据与结构知识相结合,指导迭代式蛋白优化和功能增强。
Fig. 2 基于扩散生成模型的蛋白酶从头设计高级计算框架
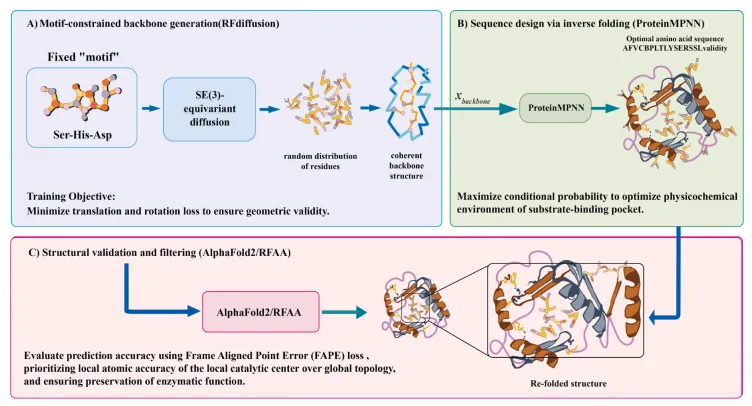
图注翻译:该分层工作流整合了三种深度学习算法,生成具有精确催化几何结构的功能性蛋白酶:
•(A)基序约束的骨架生成(RFdiffusion):RFdiffusion 算法利用 SE (3) 等变(SE (3) 等变指模型或算法对三维空间变换具有不变性,确保无论对象在空间中的方向或位置如何,预测结果都保持一致)扩散过程,从残基的随机分布中逐步去除噪声,创建具有基序约束的一致骨架拓扑结构,精确匹配活性位点的几何要求。训练目标是减少平移和旋转损失,保证骨架的几何正确性。流程从指定催化三联体(如 Ser-His-Asp)作为固定功能 “基序” 开始。
•(B)通过逆折叠进行序列设计(ProteinMPNN):利用生成的骨架(Xbackbone)作为模板,通过 ProteinMPNN 确定最优氨基酸序列。该步骤最大化条件概率,以优化底物结合口袋的物理化学环境,确保蛋白稳定并形成合适的结合口袋。
•(C)结构验证与筛选(AlphaFold2/RFAA):设计的序列在计算机中折叠以检查结构完整性。使用帧对齐点误差(FAPE)损失评估预测精度,重点关注底物结合口袋催化环境的局部原子精度,确保热力学稳定性。
Fig. 3 AI 驱动蛋白酶精准设计技术工作流
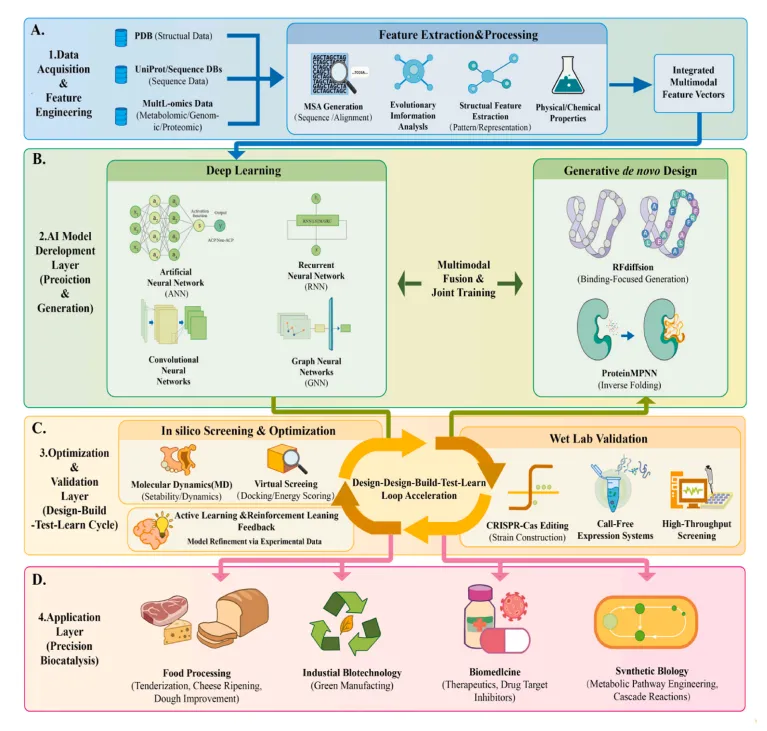
图注翻译:箭头表示信息、模型反馈和实验验证的定向流动,突出了集成的“设计 - 构建 - 测试 - 学习”(DBTL)循环:
•(A)数据采集与特征工程:收集蛋白质结构数据(PDB)、序列数据(UniProt 及相关数据库)和多组学数据集并进行处理。特征提取包括多序列比对、进化分析、结构表示和物理化学性质计算。这些组件被整合为统一的多模态特征向量,作为模型输入。
•(B)用于预测和生成的 AI 模型开发:利用人工神经网络(ANN)、卷积神经网络(CNN)、循环神经网络(RNN)和图神经网络(GNN)等深度学习架构学习多模态特征,构建 “序列 - 结构 - 功能” 关系。通过多模态融合和联合训练,将预测模型与生成式设计模块耦合。包括 RFdiffusion 和 ProteinMPNN 在内的从头设计工具,在功能或结构约束下生成候选蛋白酶序列和结构。
•(C)优化与验证(DBTL 循环):设计的变体通过分子动力学模拟和虚拟筛选进行计算机评估。选定的候选者使用基于 CRISPR-Cas 的菌株构建、无细胞表达系统和高通量筛选进行实验验证。实验结果通过主动学习和强化学习反馈以优化模型,加速迭代优化。
•(D)应用层:优化后的蛋白酶应用于食品加工、工业生物技术、生物医药和合成生物学领域。该层代表了将计算设计并经实验验证的蛋白酶转化为实际生物催化应用的过程。
Fig. 4 蛋白酶应用瓶颈与 AI 赋能改进分析
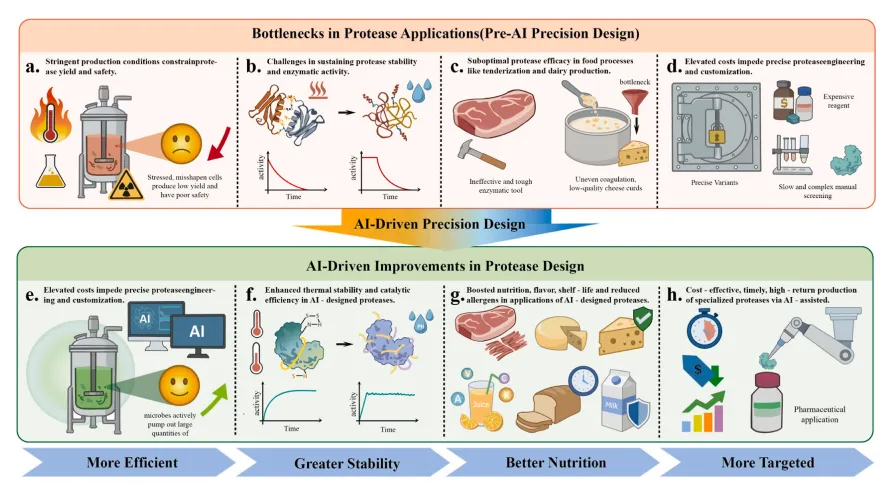
图注翻译:本图对比了传统蛋白酶的局限性与精准设计带来的性能提升。中间的过渡环节展示了计算设计如何将瓶颈转化为功能改进:
•(a-d)AI 精准设计前的蛋白酶应用瓶颈:
○(a)严苛的生产条件(包括高温、极端 pH 和化学胁迫)损害宿主细胞适应性,导致蛋白错误折叠、蛋白酶产量低和安全隐患;
○(b)热稳定性差和活性快速衰减,降低了工业条件下蛋白酶的稳定性和使用寿命;
○(c)在食品加工中,催化活性不足和特异性差导致肉类嫩化效果不佳、乳制品凝乳不均匀,影响产品质量;
○(d)开发成本高且缓慢、劳动密集型的筛选工作流,限制了精准蛋白酶工程和定制化。
•(e-h)精准设计带来的性能提升:
○(e)优化的酶变体支持更高的微生物生产效率,并在受控发酵条件下提高蛋白酶产量;
○(f)靶向结构优化增强了热稳定性和催化效率,使酶活性在更长的操作时间内保持稳定;
○(g)蛋白酶特异性的改善有助于提升食品质量,包括增强营养、改善风味、延长保质期和降低致敏性;
○(h)开发成本和时间的降低,使专用蛋白酶的高效生产成为可能,支持靶向工业和制药应用。
•底部的方向箭头总结了精准设计的渐进式成果,突出了蛋白酶应用在更高效率、更强稳定性、更好营养性能和更精准功能方面的进步。
论文相关核心开源项目与资源
1. 论文提及的核心 AI 蛋白设计工具(按出现顺序)
工具名称 | 开源地址 / 官方地址 | 核心功能 | 本文应用场景 |
ESM-2 | https://github.com/facebookresearch/esm | 蛋白语言模型,支持序列 - 结构 - 功能预测、突变效应评估 | 数据驱动的序列分析、进化特征提取 |
ProGen | https://github.com/salesforce/progen | 生成式蛋白语言模型,从头生成功能性蛋白序列 | 无结构数据时的蛋白酶序列设计 |
MLADE | 参考实现:https://github.com/ArnoldLab/ML-assisted-directed-evolution | 机器学习辅助定向进化框架,预筛选高潜力突变体 | 加速定向进化流程,降低实验成本 |
AlphaFold2 | https://github.com/deepmind/alphafold | 高精度静态蛋白结构预测 | 蛋白酶三维结构解析、活性位点定位 |
AFsample2 | https://github.com/bjornwallner/AFsample2 | 基于 AlphaFold2 的蛋白构象集合生成工具 | 解析蛋白酶动态构象、底物结合机制 |
AlphaFold3 | https://github.com/google-deepmind/alphafold3 | 高精度生物分子互作预测(蛋白 - 配体、蛋白 - 核酸) | 模拟蛋白酶 - 底物、蛋白酶 - 抑制剂复合物 |
RFdiffusion | https://github.com/RosettaCommons/RFdiffusion | 扩散模型生成全新蛋白骨架,支持功能基序约束 | 从头设计具有特定催化位点的蛋白酶骨架 |
ProteinMPNN | https://github.com/dauparas/ProteinMPNN | 逆折叠工具,为给定骨架匹配最优氨基酸序列 | 蛋白酶序列优化、稳定性提升 |
CleaveNet | https://github.com/martinalonso/CleaveNet | 蛋白酶底物肽从头设计与酶切谱调控工具 | 定制化蛋白酶底物特异性 |
DeepCleave | https://github.com/Superzchen/DeepCleave | 仅基于序列预测蛋白酶底物和酶切位点 | 快速筛选蛋白酶潜在底物 |
PGCN | https://github.com/khare-lab/protease-specificity | 结构感知图卷积网络,预测和设计蛋白酶底物特异性 | 精准调控蛋白酶底物识别能力 |
FireProt | 在线服务器:https://loschmidt.chemi.muni.cz/fireprot/ | 自动化酶热稳定性设计工具 | 蛋白酶耐热、耐 pH 改造 |
EZSpecificity | https://github.com/HongyangCui/EZSpecificity | 基于交叉注意力和 SE (3) 图神经网络的酶特异性预测工具 | 工业蛋白酶严格选择性设计 |
AllerCatPro 2.0 | 在线服务器:https://allercatpro.bii.a-star.edu.sg/ | 蛋白致敏性预测工具 | AI 设计蛋白酶的安全评估 |
2. 通用生物信息学数据库
数据库名称 | 官方地址 | 本文用途 |
RCSB PDB | https://www.rcsb.org/ | 蛋白三维结构数据获取 |
UniProt | https://www.uniprot.org/ | 蛋白序列与功能注释数据获取 |
NCBI GenBank | https://www.ncbi.nlm.nih.gov/genbank/ | 微生物基因组与蛋白酶基因序列获取 |

生物智能:在生物先进产业场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能(Biology_and_AI);实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

生物产业+物理AI=生物智能
产业智能官:Science_and_AI
加入知识星球“生物智能研究院”:生物产业OT技术(自动化+机器人+工艺+精益)和新一代IT技术(云计算+物联网+区块链+大数据+人工智能)深度融合,在场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能;实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:Science_and_AI)发表的文章,除非确实无法确认,我们都会注明作者和来源,涉权请联系协商解决,联系、投稿邮箱:wolongzy@qq.com

