最近学术圈热闹,主角是耿同学。一个退学博士,几条视频,连着把好几个院长、杰青掀下来,逼得高校一个接一个成立调查组。同济那个已经定性了,院长免职、一作解聘。
他自己有句话我印象很深——他说能被他查出来的,基本都是「造假界的耻辱」,改数据改得一眼假,连AI都能扫出来那种。
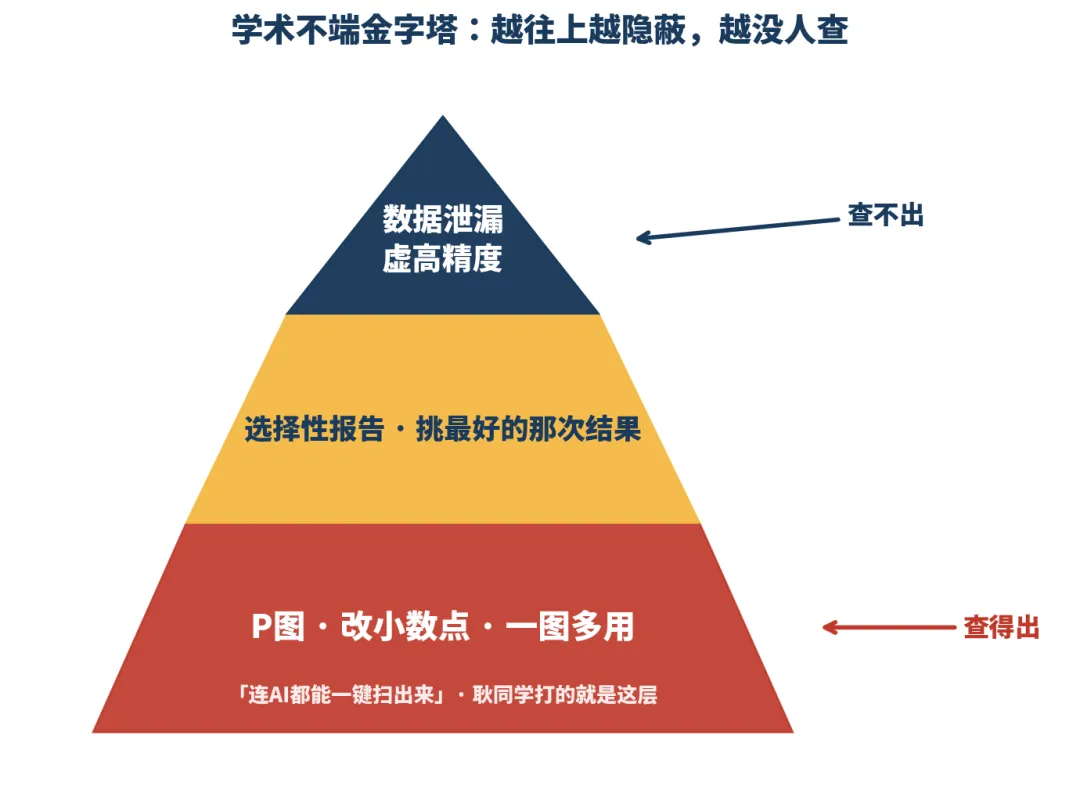
也就是说,他打掉的是金字塔最底下那层看得见的脏:P图、改小数点、一图多用。这些有痕迹,能抓。
那上面几层呢?大家天天从卫星到无人机到地面传感器结合各种统计学习和深度学习模型混:机器学习+数据分析这行的脏,耿同学的方法根本碰不着。因为人家一行假数据都没有。
▲ 越往上越隐蔽,查的人也越少
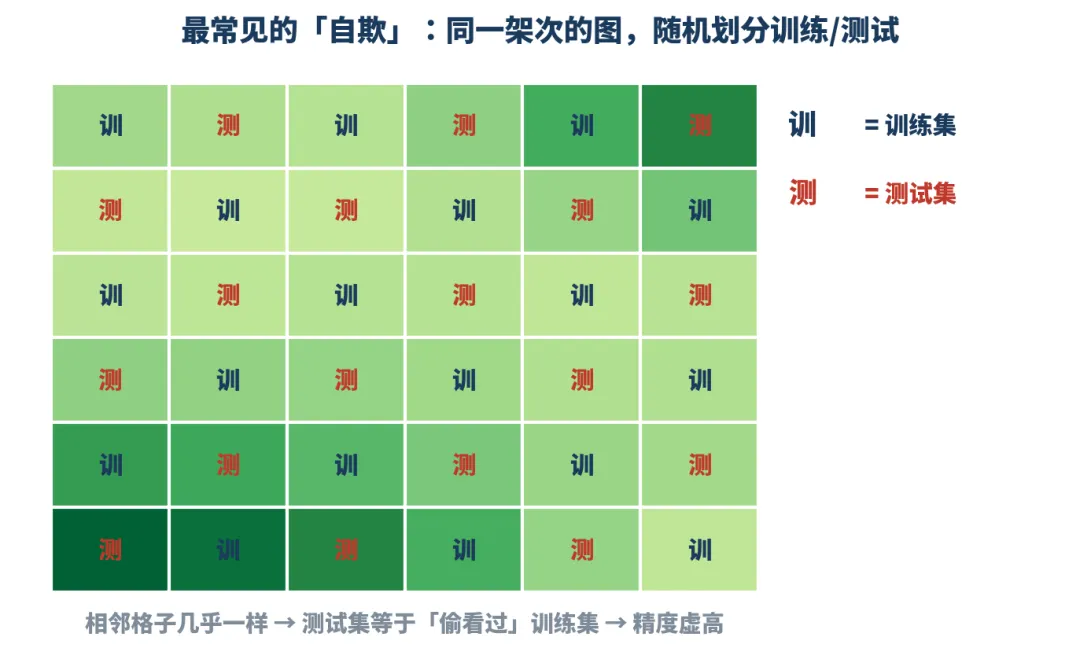
无人机飞一块地,拍几百张图,切成几千个小块,拿去估产量、估氮、数苗。随机抽八成训练、两成测试,跑出来 R²=0.94,0.95,甚至更高改改模型,对比下,漂亮,写论文,投,中。
问题来了:你那两成测试,跟训练的图是同一架次飞的,挨着的小块长得几乎一样。模型不是学会了,是提前把答案瞄了一遍。这事有个正经叫法,数据泄漏(data leakage)。
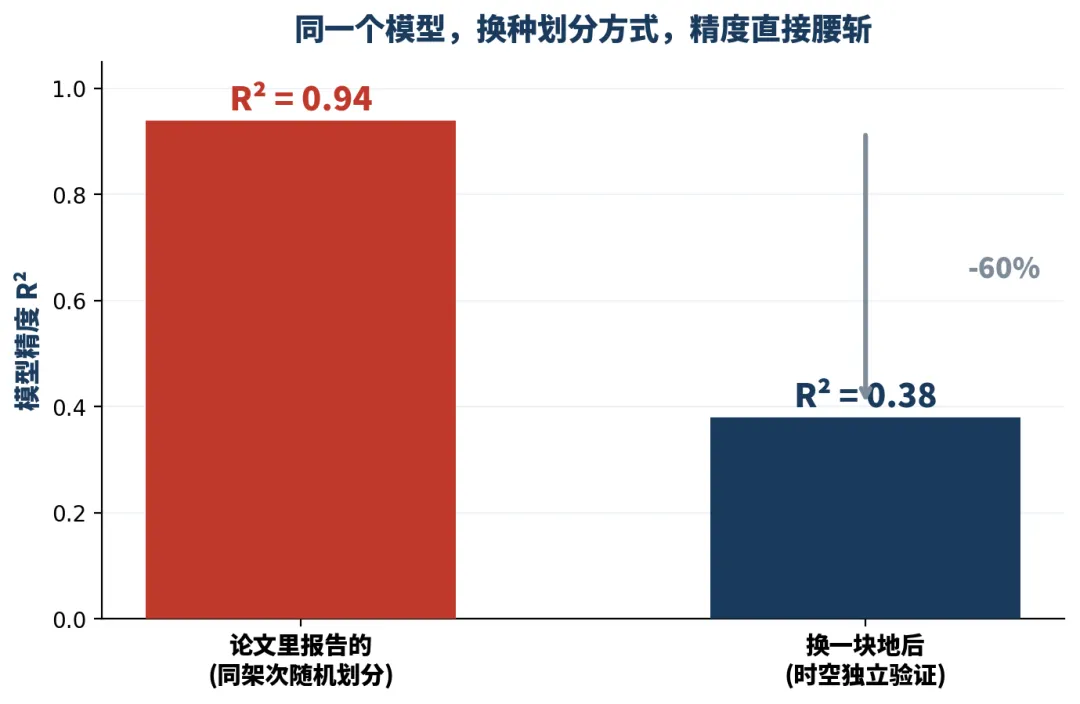
老实的做法是测试集和训练集应该完全来自不同的批次,这么一搞,论文里那个好看的 R² 会怎样?有写论文写的就感觉解决了农业重大问题一样。
0.96 掉到 0.38。不是模型变菜了,是那个 0.94 本来就不作数——自己骗自己。大家的R方低才是正常的,因为农业本身就是面临问题非常多,结果大家都各那边说自己跑的贼好。凭什么R方低就发不了论文?R方好看的那些论文,审稿人觉着nb,他查了吗?他复现了吗?
你要是觉得夸张,看顶刊的数。普林斯顿团队 2023 年发在 Patterns 上的一篇系统调查:
跨 17 个领域、294 篇论文,因为数据泄漏得出了过分乐观的结论。划重点——这些论文没一篇伪造数据。代码能跑、图能复现、数据也公开,全都「干净」,结论却是错的。
遥感加农业正好是重灾区。光被 Hindawi 撤掉的遥感深度学习论文就一堆,U-Net 分类的、影像融合的,撤稿理由写着「系统性操纵出版流程」。而这还只是被逮到的。
耿同学有个态度:先别急着骂人品,看看是啥环境逼出来的。这行数据泄漏这么常见,原因很实在:
① 数据贵。飞一次无人机、标一次田都烧钱,地就那么几块,样本本来就少,谁舍得「浪费」数据去做严格的独立验证。
② 都在卷指标。R²=0.5 没人理,0.95 才进得了好刊。目标变成刷分以后,数据泄漏就成了大家心里有数的捷径——没人伪造,但人人都在挑那个最好看的分法。
③ 审稿人懒得查复现。谁会真去下你的数据、重跑你的代码、换个分法试试?没人。于是虚高的精度一路绿灯。
说白了就是一套大家默契装看不见的玩法。它比 P 图麻烦多了——P 图还有人查,这个连查的人都没有。耿同学刀再快也砍不到这。
▸ 把外部验证的数也写出来。内部交叉验证好看不算数,换块地之后掉了多少,照实写进去。
▸ 敢写 negative result。模型在某个生育期不灵、迁到商业田有偏差,这些不丢人。
▸ 对自己做过的实验和报告负责一辈子。 如果有人找你要论文数据和代码,就给,尽可能地开源公布。如果你要造假,不如淘宝买花钱买论文更直接。
最后
耿同学把最底下那层掀开了。但他查的毕竟是「连AI都扫得出」的货。真正让这行慢慢不被信的,是那些干净、好看、结果贼牛逼的论文。。。。。
搞得就是每个paper都解决了很大的问题,结果几十年过去了,该有的问题还有。。。。然后现在拿了个AI的方法继续发论文。。。。。 反正有损失啥都是农民,不是这研究农业的人 :)
参考:Kapoor & Narayanan, "Leakage and the reproducibility crisis in machine-learning-based science," Patterns, 2023;Hindawi 遥感深度学习论文撤稿公告(2023)。本文说的是学术生态现象,不针对任何具体个人。