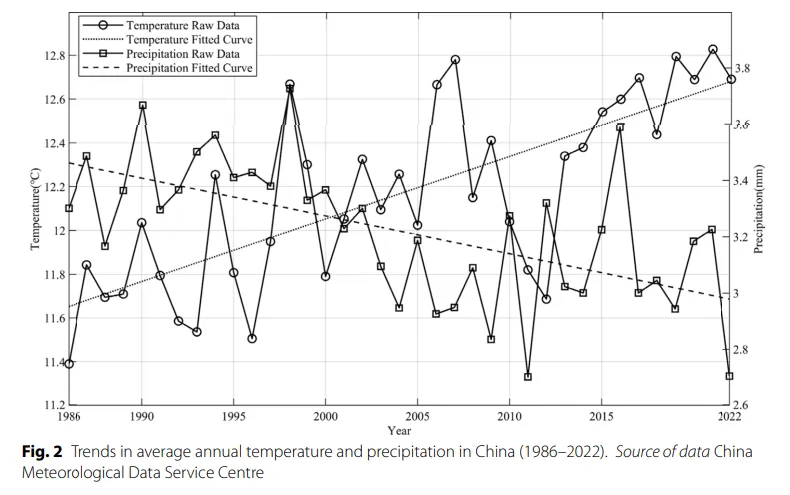
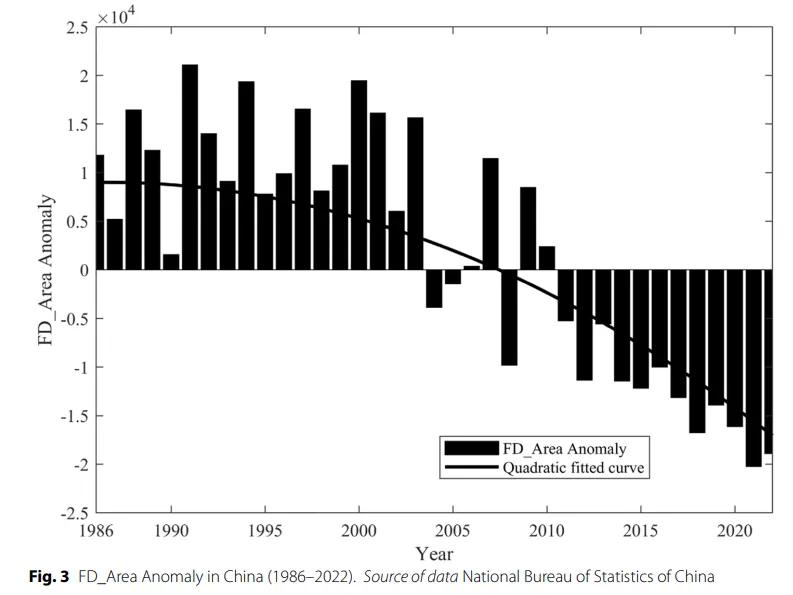
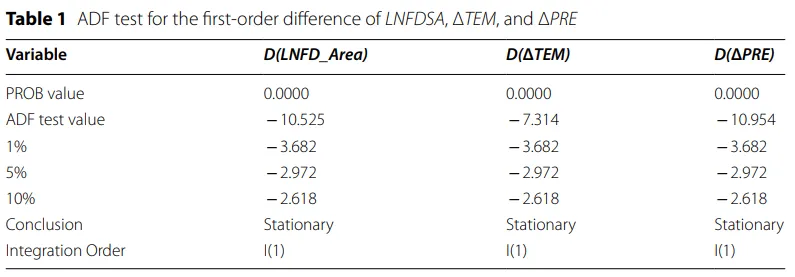
作者发现温度异常和降水异常与灾害面积之间存在长期均衡关系。降水偏少会显著推高洪旱受灾面积,而温度和降水的异常变化会通过动态调整影响灾害规模。误差修正项系数约为0.263,意味着一旦系统偏离长期均衡状态,每年会有大约26.3%的偏离被“拉回去”。
作者比较了多种Copula函数后发现,Gumbel copula拟合效果最好,说明农业保险最需要警惕的不是日常波动,而是极端灾害年份的集中赔付风险。论文进一步估计出,农业保险赔付率和洪旱受灾面积占耕地比重同时达到高位的概率约为11%左右,这个数值不算夸张,却足够说明尾部风险是真实存在的。
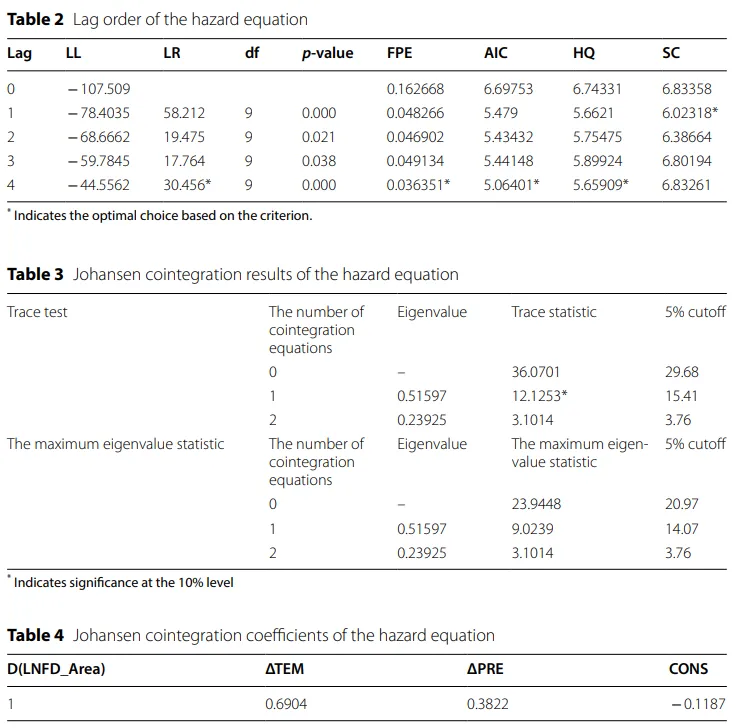
作者先检验模型该放几个滞后期,再检验变量之间有没有长期均衡关系,最后把这个长期关系写成具体的系数表达式。原文表2的结果决定选取的滞后期,做Johansen协整检验之前,通常要先建立VAR系统,而VAR模型里一个关键问题就是“要带几期滞后”。这个表就是拿不同滞后阶数下的AIC、HQ、SC、FPE等信息准则来比较,看看哪一个更合适。表里第4阶在多个指标上带了星号,所以作者最后选了lag=4。
原文表3做了Johansen协整检验。前面单位根检验已经说明这些变量都是一阶单整的,所以接下来就要看它们之间是否存在长期稳定关系。这些变量之间存在 1 个协整关系。这意味着温度异常、降水异常和洪旱受灾面积虽然短期会波动,但从长期看,它们存在一个共同的均衡关系。
原文表4展示长期关系。既然表3说明存在协整关系,那么表4就是在报告这个协整方程里的系数。表中显示,协整方程里ΔTEM 和ΔPRE都进入了长期关系式,系数分别对应温度异常和降水异常对受灾面积长期变化的影响。作者随后根据这个表把长期关系写成了具体表达式,并据此解释,降水不足会扩大洪旱受灾面积,温度和降水异常会共同塑造农业灾害的长期变化。
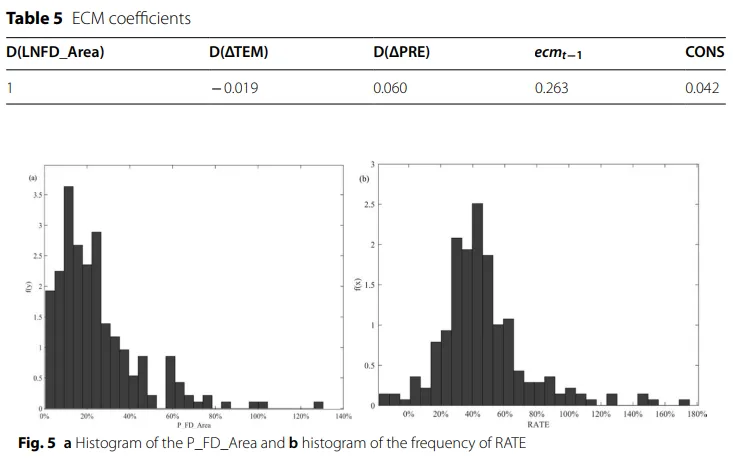
原文表5是估计误差修正模型。作者前面已经用协整检验证明,温度异常、降水异常和洪旱受灾面积之间存在长期均衡关系。但协整只说明“长期上有关联”,还不能说明短期波动怎么往长期均衡拉回去。所以这里就接着用ECM,看短期内气温、降水的变化会怎样影响受灾面积变化,以及系统偏离长期均衡后会以多快的速度调整回来。当洪涝和干旱受灾面积偏离长期均衡时,系统每年大约会纠正 26.3% 的偏离。
原文图5展示两个核心变量的分布特征。左边的图是 P_FD_Area的直方图,也就是洪涝和干旱受灾面积占耕地面积比重的分布;右边的图是RATE的直方图,也就是农业保险赔付率的分布。因为 Copula 很关心变量在尾部、极端值上的联合表现,所以作者先要判断,这两个变量是不是偏态分布、是不是有厚尾、是不是存在极端值聚集。
从图上看,左边的P_FD_Area呈现出右偏分布,说明中国农业更多面对的是高频但相对较轻的灾害,小灾多、大灾少。右边的RATE则更接近一个尖峰厚尾分布,说明农业保险赔付率大多数年份集中在某个区间附近,但仍然存在少数赔付率很高的年份。
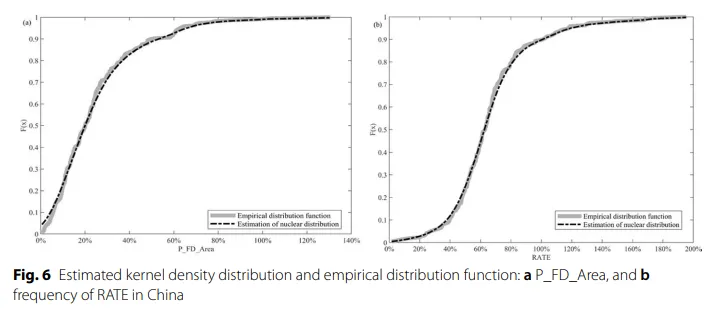
原文图6展示两个核心变量的分布。原文据此指出,P_FD_Area 呈现右偏分布,说明中国农业更多面对的是高频但相对较轻的洪旱灾害;而 RATE 呈现尖峰厚尾特征,说明赔付率大多集中在某一区间,但少数年份会出现较高赔付。这张图展示的是这两个变量的分布并不简单,后面用 Copula 而不是普通线性模型是有依据的。
表6检验序列有没有显著自相关。这里作者用了Breusch–Godfrey LM test for autocorrelation,原假设是“不存在序列相关”。表里给出的p值是0.8174,远高于常见显著性水平,所以不能拒绝原假设。
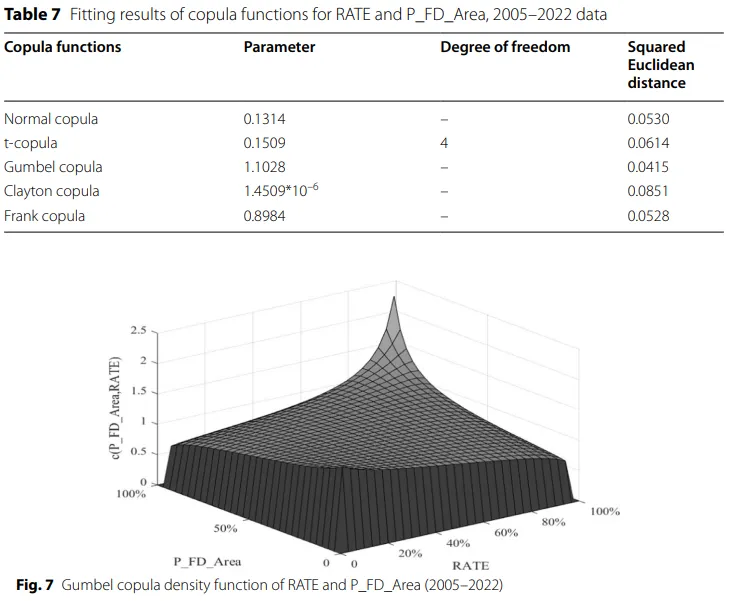
原文表7是比较不同Copula函数的拟合效果。作者把Normal copula、t-copula、Gumbel copula、Clayton copula、Frank copula都拿来试了一遍,然后用Squared Euclidean distance作为判据来判断谁拟合得最好。这个指标可以简单理解成“模型拟合结果离经验分布有多远”,数值越小,说明拟合越贴近真实数据。表里可以看到Gumbel copula的距离最小,为 0.0415,所以作者最终选它作为后续分析灾害损失与保险赔付关系的最优模型。
图7把这个最优模型对应的依赖结构画出来。图中高处明显集中在右上区域,这说明当 灾害损失高、赔付率也高 时,二者会表现出更强的联动,这正是原文强调的 上尾相关。
原文图8展示样本分区分布。作者把“灾害面积占比”和“保险赔付率”同时放进一个坐标系里看频数分布。更直观地说明不同组合状态下,样本主要集中在哪些区域。原文随后把这个空间划分为四个区域,用来区分“小灾低赔”“小灾高赔”“大灾低赔”“大灾高赔”这几类情况。
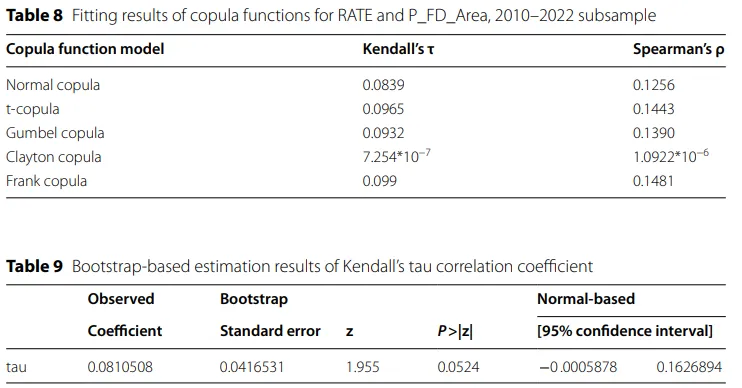
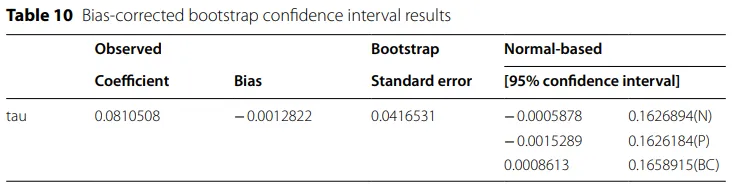
原文表8、9、10分别做了子样本稳健性检验和Bootstrap稳健性检验。表8基于2005到2022 年全样本得到的。这里作者把样本缩短为2010到2022年,重新比较不同copula模型下的 Kendall’s τ和Spearman’s ρ,想看在政策性农业保险进一步发展之后,结论会不会变掉。结果是,作者仍然认为Gumbel copula最能反映这种依赖结构。因为样本量并不算特别大,作者担心相关系数估计会受小样本偏误影响,所以进一步对Kendall’s tau做了bootstrap检验。表9先给出基于重复抽样得到的标准误、z值和p值,说明这个正相关关系在常规近似下已经接近显著。表10则更进一步,给出偏差修正后的置信区间。这里最关键的信息是,偏差修正后的区间已经排除了0,所以作者据此认为,灾害损失和保险赔付之间确实存在显著的正向相关。
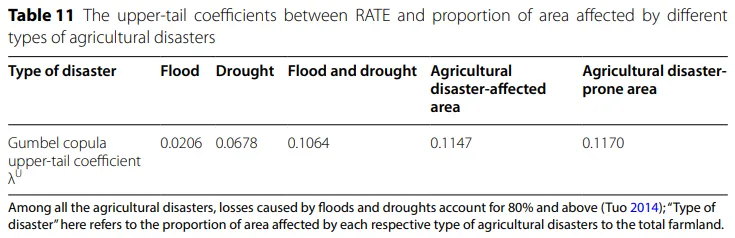
表11把“上尾相关”具体拆开来看。作者把不同类型的灾害指标拆开,分别去算上尾系数,包括洪灾、旱灾、洪旱合计、农业灾害受灾面积和农业灾害成灾面积等。从表里的数值看,单独的洪灾上尾系数较低,单独的旱灾更高一些,而把洪旱合并或使用更综合的灾害面积指标时,上尾系数会更高。










 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
