
论文: Dream to Recall: Imagination-Guided Experience Retrieval for Memory-Persistent Vision-and-Language Navigation
来源: IEEE TPAMI 2026 | 上海交通大学
农业机器人进田作业,最大的 bug 是什么?
不是传感器不够贵,不是算法不够新——而是每次进田都像"第一次"。
传统农业机器人导航,本质上是一次性的:执行完任务,清空内存,下一次重新来过。今天在3号大棚巡检完,明天去5号大棚,还是什么都不知道。地形、作物布局、障碍物分布……全部重新学。
这像什么?像一个每次进教室都失忆的学生。
上交最新论文 Memoir(IEEE TPAMI 2026)解决的就是这个问题——让导航机器人真正记住自己走过的路,并且能用"想象力"主动调用相关记忆,越走越聪明。
01 传统记忆系统有哪些 bug?
在说 Memoir 之前,先搞清楚之前的方案差在哪。现有记忆persistent VLN 方法有两个致命问题:
Bug 1:要么全盘照搬,要么完全不用
之前的方案分两派:一派把历史上所有观测一股脑塞进模型——环境复杂起来,计算量爆炸,有效信息被噪声淹没;另一派只做固定窗口查找——只参考最近几步的记录,更早的经验全丢了。两种都是极端,都有严重缺陷。
Bug 2:只记"看到了什么",不记"怎么走的"
之前的方法只存储环境观测(这个路口有一棵玉米,那个转角有灌溉管道),但完全忽略了导航行为历史——我是怎么决定在这里左转的?为什么在这个分岔口选了这条路而不是那条?这些决策策略本身也是宝贵的经验,但之前的系统根本不屑于记。
02 现有主流方法对比
Memoir 之前,记忆persistent VLN 领域主要有这几个方案:
TourHAMT:把完整导航序列堆进记忆,但冗余太多,性能反而下降。
ESceme:用更广阔的空间上下文增强视觉表示,放弃导航历史。
OVER-NAV:构建多模态拓扑图,用固定距离检索关键词-观测对应关系。
GR-DUET:目前最强的方法,在 DUET 架构基础上保留完整拓扑记忆,但把所有记忆都塞进去,计算成本高。
它们共同的问题:记忆是静态的,检索是暴力的。 Memoir 的核心突破是让检索变得"智能"——用想象力驱动。
03 Memoir 的核心:让想象力成为检索钥匙
人的导航是怎么做的?
面对一条指令"从大棚入口走到第三排番茄架",有经验的人不会翻遍所有记忆,而是在脑子里先预演一遍路线,然后带着这个预演去查:"上次走这条路,遇到过什么障碍?在哪里拐弯的?哪段最难走?"
这就是 Memoir 的核心洞察:想象未来状态 = 最精准的记忆检索 query(查询钥匙)
不是被动翻记忆,而是带着"预测"去找相关经验。
和传统"想象-规划"的本质区别
之前也有"想象式规划"方法,用世界模型生成轨迹。但这些方法孤立生成轨迹,没有和真实记忆挂钩,容易产生"幻觉"——想象出来的路线在实际环境中根本不成立。
Memoir 的关键区别:想象是有根的,世界模型生成的预测状态是用来查询真实长期记忆的,检索到的经验再反哺决策,形成闭环。想象不是凭空编造,而是精准召回的触发器。
04 三大技术组件拆解
Memoir 由三个核心组件构成,形成一套完整的"记忆-想象-检索-决策"闭环。
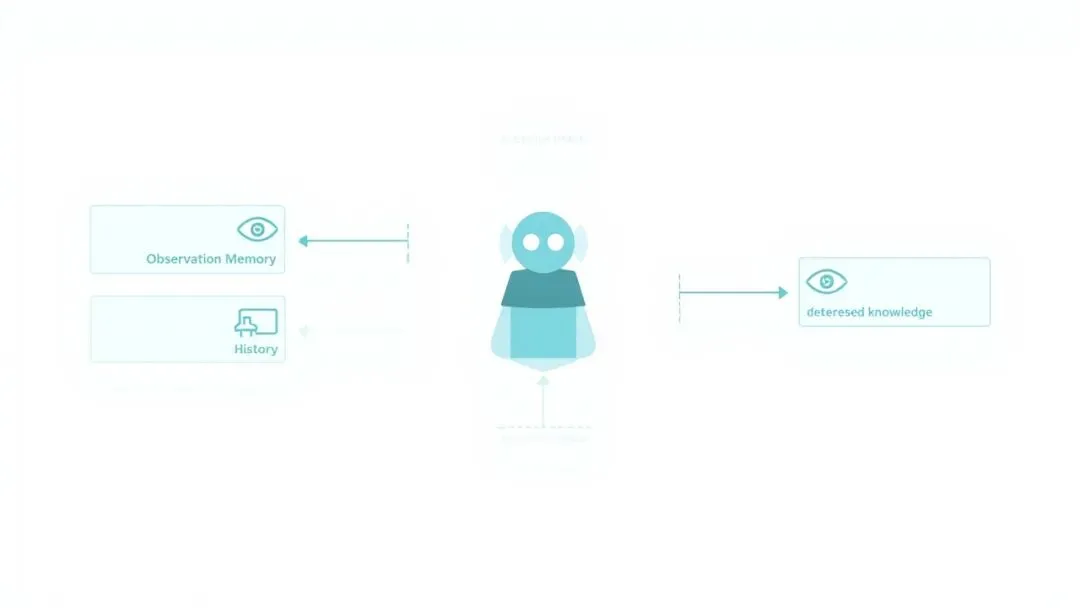
组件一:语言条件化的世界模型
问题:标准世界模型(基于 RSSM 架构)只学环境动态,不理解 VLN 任务里的语言指令。
解法:在标准 ELBO 损失函数里加入指令条件和奖励信号(衡量到目标的距离),训练一个语言条件化的对比变分世界模型。
训练目标有三个损失项:
- 𝒥_REWARD:预测到目标远近的能力,用于判断想象何时终止
- 𝒥_NCE(对比损失):学会区分正确和错误的状态-观测配对,核心是用 cosine 相似度衡量潜空间里状态和观测的匹配程度
- 𝒥_KL:确保潜状态的后验分布接近先验,维持模型稳定
为了提升长时域预测能力,还加入了 multi-step overshooting 技术——直接预测 d 步之后的潜状态,而不是一步步滚动预测,避免误差累积。
组件二:混合视点记忆(HVM)
这是 Memoir 的核心创新之一。
之前的记忆系统把"环境观测"和"导航历史"分开存储,各管各的。Memoir 提出了混合视点级记忆(Hybrid Viewpoint-Level Memory),在每个视点同时存储两类信息:
- 观测库(Observation Bank):在该视点看到的环境特征
- 历史库(History Bank):到达该视点过程中的决策序列——包含了决策策略的编码
两类信息都锚定在同一视点上,检索时可以同时召回"在那里看到了什么"和"当时是怎么决策的"。
组件三:经验增强的导航模型
检索到的记忆不是简单拼接,而是通过三个专用编码器分别处理:
三者融合后输出最终导航决策。
05 检索算法是怎么工作的?
Memoir 的检索流程比之前的方法优雅得多。算法如下:
Step 1:世界模型想象未来轨迹
从当前位置出发,根据当前指令,世界模型递归地想象未来状态序列。每一步想象都会产生一个 query 状态。
Step 2:双路检索
有了想象状态作为 query,同时发起两路检索:
- 历史检索:在历史库中,用想象状态的序列相似度匹配,召回决策模式最相似的历史路径
- 观测检索:在观测库中,用状态-观测兼容度分数(由对比学习学到的相似度函数 f(zt, ot) 衡量)做拓扑搜索,找到最匹配的观测点
Step 3:自适应过滤
检索结果不是全盘接收,而是根据兼容度分数动态过滤:
- 随着想象步数增加,过滤阈值逐步放宽(ρ_o 和 γ_o 控制)
Step 4:路径重建与图更新
对每个检索到的候选视点,找到从当前位置到它的最短路径,把路径上的所有视点加入检索集,并更新当前拓扑地图。
整个过程最妙的地方:想象是动态的 query,检索是精准的匹配。想象往前走,记忆被激活,不需要遍历全部历史。
06 实验结果:数字很扎实
Memoir 在 10 种不同测试场景下验证,覆盖 IR2R、R2R 等多个主流 VLN 基准。
| 指标 |
结果 |
| IR2R 上 SPL 提升 |
+5.4%(相比最佳 baseline GR-DUET) |
| 训练速度 |
8.3 倍加速 |
| 推理时记忆占用 |
降低 74% |
| 上限空间 |
73.3% vs 93.4%(神谕分析) |
8.3 倍训练加速 + 74% 推理内存降低这两个数字最值得注意:精准检索比一股脑塞记忆,既快又省。
上限分析(73.3% vs 93.4%)说明,当前 Memoir 只发挥了这种范式 78% 的潜力,还有巨大提升空间。这对研究者是好事——方向对了,剩下的是工程优化。
07 对农业机器人的启示
农业机器人是具身智能最典型的落地场景之一。温室,果园,大田——环境相对结构化、作业周期长、重复访问同一区域。
采摘机器人:第一次进草莓大棚,记住哪排通道最窄、哪排产量最高、哪段转弯最难控制。下次再来,直接调用记忆,节省大量重复探索时间。路径规划从零开始变成"记忆+微调"。
巡检机器人:在农田中反复巡逻,每次都记住病虫害发生的热点区域。久而久之,形成一张"病虫害风险地图"——哪些地块在什么时期容易出问题,机器人会主动提前加强监控,而不是被动响应。
喷药机器人:记住往年在哪些地块、什么时间发生过什么病害,下次提前加强监控路径。HVM 的行为历史记录能力在这里非常有用——记录的不只是"这里有病虫害",还包括"上次我是从哪个方向接近、如何决策喷洒范围的"。
嫁接机器人/移栽机器人:这类需要在狭窄空间精确操作的机器人,行为记忆可以记住每次操作的微妙调整策略,越做越精准。
关键启发:从"全量记忆"到"精准召回"
Memoir 范式对农业机器人最重要的启发是:不要囤积数据,要学会精准检索。
农业环境每年都在变——作物换季、灌溉系统调整、新的种植行距、临时搭建的大棚隔断。全量记忆会很快过时,但如果是根据当前任务动态生成 query,精准召回相关经验,机器人就能在动态环境中持续学习,而不是积累一堆过时数据。
08 总结
Memoir 的核心贡献,是提出了"想象力引导检索"的新范式:
不是被动积累记忆,而是主动用世界模型预测未来状态,精准召回相关历史经验。
三大创新:语言条件化世界模型让想象有语义方向;混合视点记忆同时存储观测和决策历史;专用编码器让检索结果真正服务决策。
对于农业机器人而言,这是从"执行命令"走向"自主决策"的关键一步。温室果园的复杂地形、多变的作业任务、重复访问的特性——都是这种范式最好的试验场。
当然,从 VLN 论文到农业机器人落地还有距离:真实农田环境比模拟器复杂得多,世界模型需要更强的泛化能力,多机器人协同场景下记忆如何共享。但方向是对的。
参考链接
- 论文:https://arxiv.org/abs/2510.08553[1]
- 代码:https://github.com/xyz9911/Memoir[2]
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
