这里是科研人的「方法急救站」!🚑
- • 欢迎加入我们的**"学术社群"**,每日更新热点论文复现指南!
 论文卡片
论文卡片
我们通过小程序科研零时差追踪到: Agricultural and Forest Meteorology 近期发表题为“Improving phenology prediction of wheat breeding populations by integrating deep learning and process-based crop models”的文章。第一单位为南京农业大学。
doi: 10.1016/j.agrformet.2026.111154
作者邮箱:bingliu@njau.edu.cn, yanzhu@njau.edu.cn
标签:#小麦物候 #作物模型 #气候变化 #深度学习 #长短期记忆网络 #数据融合
 cover
cover本文内容速览:
- 1. 提出科学问题
- 2. 文章的主要结论
- 3. 分析过程和方法
- 4. 研究的局限性
1. 提出科学问题
1.1 研究领域现状
小麦是全球最重要的谷物之一,其物候期(尤其是抽穗期)是影响产量和品质的关键因素。准确预测不同基因型小麦在多变环境下的物候期,对于优化作物管理和培育广适性品种具有重要意义。当前,基于过程的作物生长模型(如APSIM-Wheat和WheatGrow)被广泛应用于模拟基因型、环境和管理措施之间的交互作用。然而,这些传统模型主要基于长期的植物生理学经验知识构建,输入参数相对固定,往往难以量化极端气候事件对作物生育期的影响,导致在复杂环境下的预测精度受限。另一方面,数据驱动的机器学习方法虽然预测精度高,但常被视为缺乏生理学解释的“黑盒”。
1.2 本文要解决的关键科学问题
为了克服单一方法的局限性,本研究试图将作物生长模型的机制优势与机器学习的数据处理能力相结合,主要解决以下问题:
- • 问题 1: 如何构建一个有效的数据-模型融合框架,将长短期记忆网络(LSTM)与传统的作物生长模型(APSIM-Wheat和WheatGrow)深度整合?
- • 问题 2: 这种整合模型能否在包含极端气候变量(如冷度日、降水、日照时数)的情况下,显著提升多生态点、多基因型小麦群体抽穗期的预测精度和鲁棒性?
- • 问题 3: 如何打开机器学习的“黑盒”,从生物学机制上解释整合模型在不同环境和群体中的预测逻辑?
1.3 研究的理论/现实意义
本研究提出了一种结合深度学习与过程模型的物候预测新范式。该方法不仅提高了复杂环境胁迫下小麦抽穗期的预测精度,还保留了作物模型的生理学可解释性。这为智能作物育种中的_表型定量预测_提供了可靠的数字化工具,有助于加速适应气候变化的广适性小麦品种的筛选与改良。
2. 文章的主要结论
本研究通过对中国和欧洲多个生态点的1142个小麦基因型进行验证,证明了数据与模型融合策略的有效性。
- • 结论 1: 整合模型(APSIM-Wheat-LSTM 和 WheatGrow-LSTM)的预测精度显著优于单一作物模型和纯机器学习模型。在严格的留一环境交叉验证(LOEO)下,整合模型的均方根误差(RMSE)平均降低了40%以上,决定系数(R²)提高了约10%。
- • 结论 2: 整合模型展现出强大的跨模型和跨群体泛化能力。通过解释性机器学习方法(GradientSHAP)分析表明,整合模型能够捕捉不同生育期内冷度日、降水和日照时数对抽穗期的动态影响,准确反映了复杂环境下小麦发育的潜在生理机制。
3. 分析过程和方法
[更加详细的复现指南可加入学术社区获取!]
这篇文章的核心逻辑在于:不抛弃传统机制模型,而是利用机制模型为机器学习提供具有生物学意义的时间框架,再由机器学习去捕捉机制模型遗漏的非线性气象特征。 接下来,我们将逐步拆解作者是如何实现这一构思的。
首先,作者构建了庞大且具有代表性的数据集。研究选取了三个独立的小麦群体(AGIS、GABI 和 iWheat),共计1142个基因型,这些品种来源于全球47个国家。田间试验分布在中国和欧洲的多个典型气候区,涵盖了19个不同的“播期-地点”环境组合。这种高维度、大跨度的数据集是验证模型泛化能力的基础。
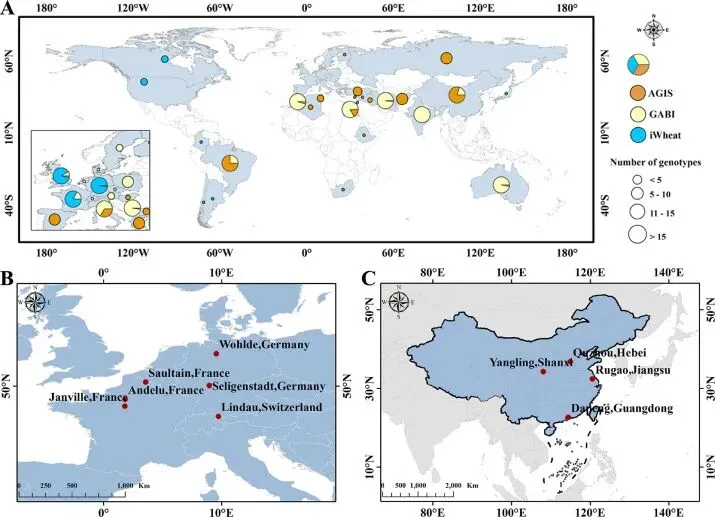 ▲Figure 1. 三个小麦群体中基因型来源的地理分布及中欧代表性种植点
▲Figure 1. 三个小麦群体中基因型来源的地理分布及中欧代表性种植点在方法实现的第一步,作者对两个经典的作物生长模型(APSIM-Wheat和WheatGrow)进行了_基因型特异性参数(GSPs)的校准_。为了避免数据泄露并测试模型的真实外推能力,作者采用了严格的_留一环境交叉验证(LOEO)_策略。即在校准某个环境下的参数时,完全不使用该环境的观测数据,而是利用差分进化(DE)算法在其他环境的数据上寻找最优参数。
接下来是本文的重头戏:整合框架的构建。作者并没有简单地将模型输出和气象数据拼接,而是设计了一个_受生育期感知的融合框架_。
具体步骤如下:
第一,利用校准好的作物模型模拟出每个基因型从播种到抽穗的六个关键物候节点,并将其划分为五个连续的生育阶段(GS1到GS5)。
第二,在这些由机制模型定义的生物学时间窗口内,提取传统模型未充分考虑的三个气象特征:累积冷度日(CDD)、阶段性降水(Prcp)和日照时数(SunH)。
第三,将这些按生育期排列的序列化气象特征输入到长短期记忆网络(LSTM)中。
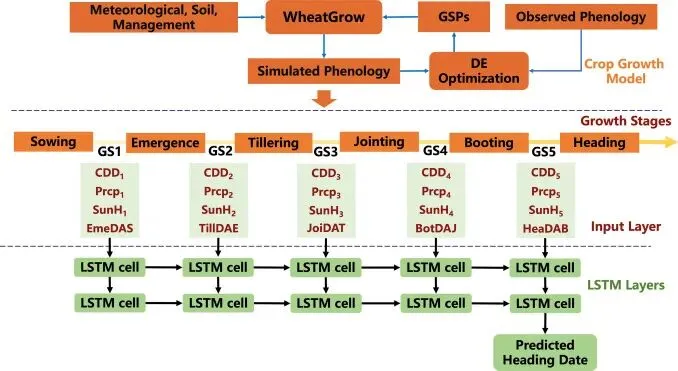 ▲Figure 2. 整合WheatGrow与LSTM预测小麦抽穗期的技术流程图
▲Figure 2. 整合WheatGrow与LSTM预测小麦抽穗期的技术流程图在这里,作者选择LSTM是非常考究的。小麦的生长是一个时间序列过程,前一个生育期的状态会影响后一个生育期。LSTM内部的_门控机制_(遗忘门、输入门、输出门)能够有效处理这种长时间依赖关系,并自适应地赋予不同生育期气象因子不同的权重。作者通过网格搜索,确定了包含两层、每层32个隐藏单元的LSTM网络结构,以平衡模型复杂度和预测性能。
为了直观展示数据的时空异质性,作者对不同环境下的抽穗期以及各生育期的气象变量进行了可视化。这些图表证明了输入特征具有极大的变异性,这对于训练鲁棒的深度学习模型至关重要。
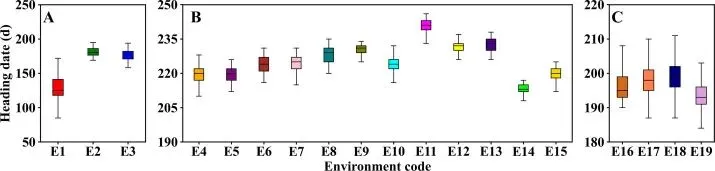 ▲Figure 3. 19个实验环境下的小麦抽穗期分布
▲Figure 3. 19个实验环境下的小麦抽穗期分布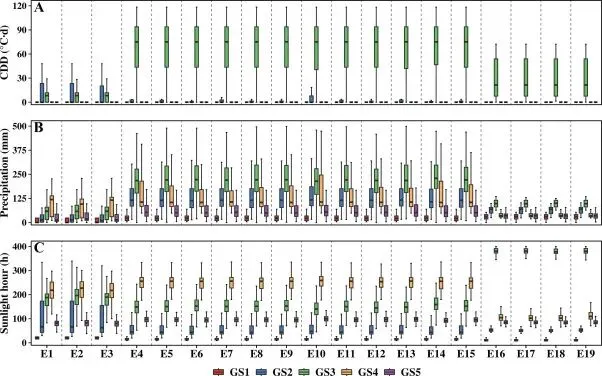 ▲Figure 4. 基于APSIM-Wheat模拟的各生育期关键气象变量分布
▲Figure 4. 基于APSIM-Wheat模拟的各生育期关键气象变量分布在模型评估阶段,作者进行了多维度的对比。不仅比较了整合模型与原始作物模型,还引入了纯数据驱动的机器学习模型(随机森林RF、LASSO回归、纯LSTM)以及非序列化的整合模型(APSIM-Wheat-RF等)。结果清晰地显示,APSIM-Wheat-LSTM和WheatGrow-LSTM在测试集上的误差最小,R²最高。这说明,缺乏机制模型引导的纯机器学习模型难以在未见过的环境中泛化,而缺乏时间序列处理能力的非序列化模型(如RF)则容易陷入过拟合。
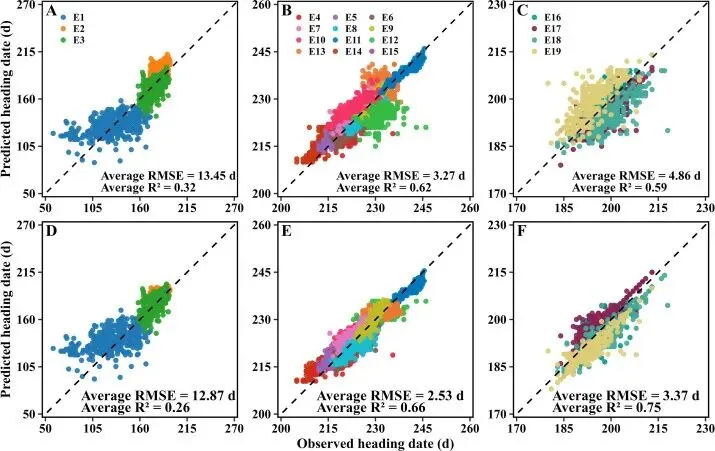 ▲Figure 6. APSIM-Wheat及整合模型在三个数据集上的预测与观测值对比
▲Figure 6. APSIM-Wheat及整合模型在三个数据集上的预测与观测值对比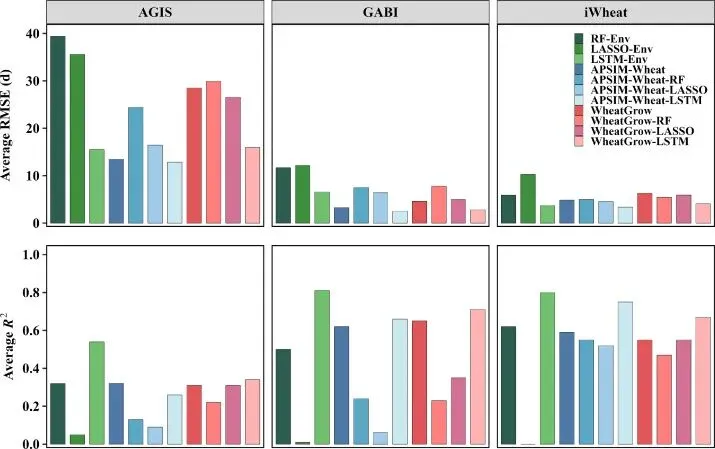 ▲Figure 8. 整合模型与其他机器学习方法在所有测试环境下的预测精度比较
▲Figure 8. 整合模型与其他机器学习方法在所有测试环境下的预测精度比较最后,为了打破机器学习的“黑盒”属性,作者引入了解释性机器学习方法(GradientSHAP)。这一步是提升文章学术价值的关键。作者量化了CDD、Prcp和SunH在五个生育期对抽穗期预测的具体贡献度。
分析结果与植物生理学规律高度吻合。例如,在GS2和GS3(分蘖到拔节期),累积冷度日(CDD)表现出极高的特征重要性。适度的CDD满足了冬小麦的春化需求,促进发育;而过高的CDD(如在AGIS群体中观察到的)则会导致春化过度或发育节律受损,从而产生负向贡献(延迟抽穗)。到了GS4和GS5(生殖生长后期),日照时数(SunH)的贡献急剧上升,这反映了长日照对光周期敏感型小麦抽穗的促进作用。
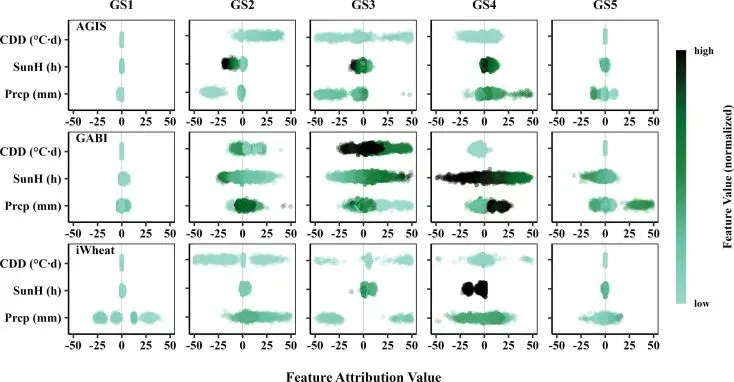 ▲Figure 9. 基于GradientSHAP的APSIM-Wheat-LSTM模型特征归因分析
▲Figure 9. 基于GradientSHAP的APSIM-Wheat-LSTM模型特征归因分析通过这种特征归因分析,作者不仅证明了模型“算得准”,更证明了模型“学得对”,其内部的预测逻辑完全符合复杂的基因-环境交互机制。
4. 研究的局限性
尽管该整合模型表现出色,但作者也客观地指出了研究中存在的局限性。
首先,用于模型校准的单基因型观测数据仍然有限。虽然采用了LOEO交叉验证策略来最大化数据利用率,但面对庞大的基因型数量,数据量不足仍会导致参数校准存在一定的不确定性。
其次,目前的整合模型_主要输入的是气象因子,对土壤和管理效应的表征有限_。例如,模型未能显式包含极端高温胁迫、干热风事件以及饱和水汽压差(VPD)等已知会显著影响小麦发育速率的变量。
最后,LSTM模型在表征土壤水分有效性时主要依赖降水变量,而_未能完全刻画土壤水分的记忆效应_(如前一季干旱对深层土壤水分的消耗)。未来的研究需要引入更多维度的胁迫指标和更高时间分辨率的数据,以进一步完善预测模型。
如果你觉得这篇文章对你有帮助,欢迎点赞👍、收藏⭐️和分享🔗给更多的科研小伙伴们!
如果你有任何问题,欢迎加入我们的学术社群与大家讨论交流💬
最后祝大家都能多多发顶刊!!

