华中农业大学 Nat. Commun. | 多模态知识迁移预训练:M2UMol框架突破分子表示学习的模态完整性限制
在计算机辅助药物发现领域,分子表示学习(Molecular Representation Learning, MRL)已成为支撑分子性质预测、药物-药物相互作用预测等核心任务的关键技术。近年来,基于预训练的MRL方法通过在大规模无标注分子数据上进行自监督学习,显著提升了下游任务的预测性能。然而,现有多模态预训练方法普遍面临一个实际应用瓶颈:它们要求分子数据在预训练和微调阶段均具备完整的多模态信息,而在真实场景中,除二维拓扑图外的其他模态数据往往难以获取。针对这一挑战,华中农业大学章文教授团队,在Nature Communications发表了一种创新的多模态到单模态知识迁移预训练框架M2UMol,为解决模态不完整条件下的分子表示学习问题提供了新思路。研究背景与问题提出
分子表示学习的核心目标是将分子特征化为数值向量,以支持下游的机器学习任务。传统方法依赖人工设计的分子描述符,受限于领域知识的覆盖范围。深度学习驱动的MRL方法则能够自动挖掘分子的潜在特征,在药物发现的多项任务中展现出显著优势。
现有MRL方法通常处理三类分子模态:一维SMILES序列、二维拓扑图和三维构象图。自监督预训练MRL方法可分为单模态和多模态两大类。单模态方法聚焦于单一模态,通过掩码预测或对比学习等任务学习分子表示;多模态方法则试图捕获不同模态间的互补信息以提升表示质量。
然而,现有多模态方法存在明显局限。"一对一"范式仅建模两种模态间的关系,难以充分利用多模态知识;"一对多"范式虽整合了多种模态,但要求预训练和微调阶段的模态完整性。这导致两个实际问题:一是无法利用大规模模态缺失的分子数据进行充分预训练;二是难以适应下游应用中仅有二维拓扑图可用的常见场景。
M2UMol框架设计
M2UMol的核心创新在于设计了一套多模态到单模态的知识迁移机制,使预训练阶段学习到的多模态知识能够有效迁移至二维模态编码器,从而在下游任务中仅需二维输入即可模拟多模态信息。
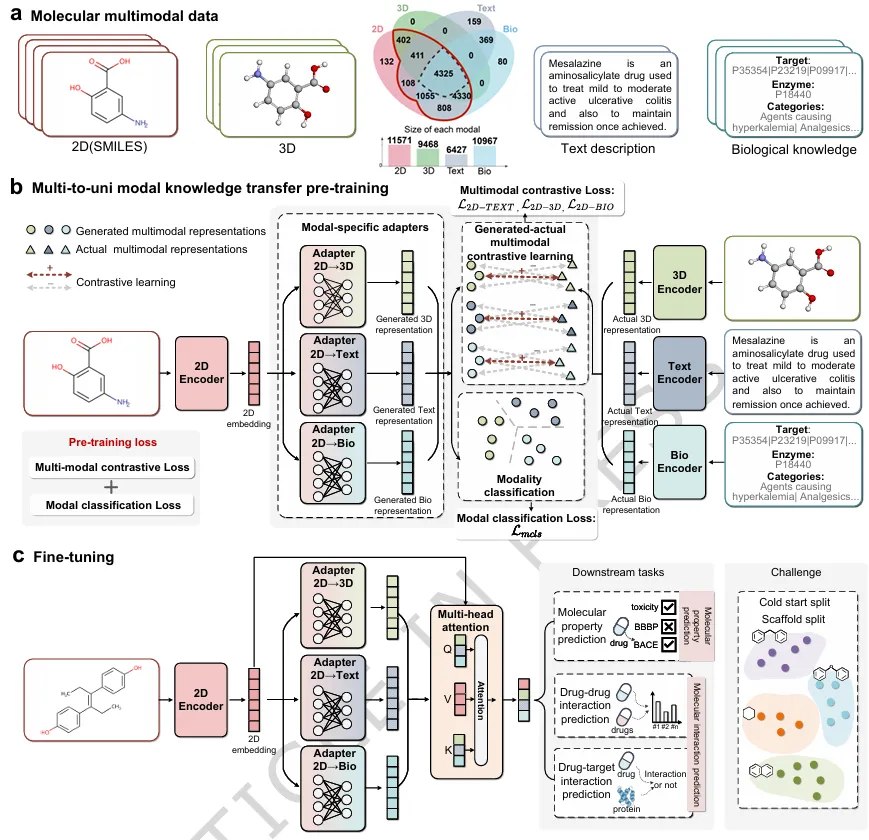
▲ Fig.1 | M2UMol框架概述。如图1所示,M2UMol构建了包含11,571个类药分子的多模态数据集,涵盖四种模态:二维拓扑图、三维构象图、文本描述和生化特征。框架的预训练阶段包含两个核心组件:
第一,模态特异性适配器。M2UMol为每种目标模态设计了独立的适配器模块,用于基于二维分子表示生成伪多模态表示。这些适配器在预训练过程中学习如何将二维编码器捕获的信息转换为对应模态的表示形式。
第二,双重自监督预训练任务。生成-实际多模态对比学习任务旨在对齐适配器生成的伪多模态表示与实际多模态编码器产生的真实表示,引导多模态知识向二维编码器迁移;模态分类任务则要求将生成的表示正确分类到对应的模态类别,促使适配器捕获模态特异性知识,生成具有高区分度的表示。
在微调阶段,预训练的二维编码器和模态特异性适配器协同工作:二维编码器学习分子的二维表示,适配器则生成三维、文本和生化模态的伪表示。这些多源表示通过多头注意力机制进行自适应融合,得到最终的分子表示用于下游任务预测。
实验验证与性能分析
研究团队在分子性质预测和分子相互作用预测两大类任务上对M2UMol进行了系统评估。
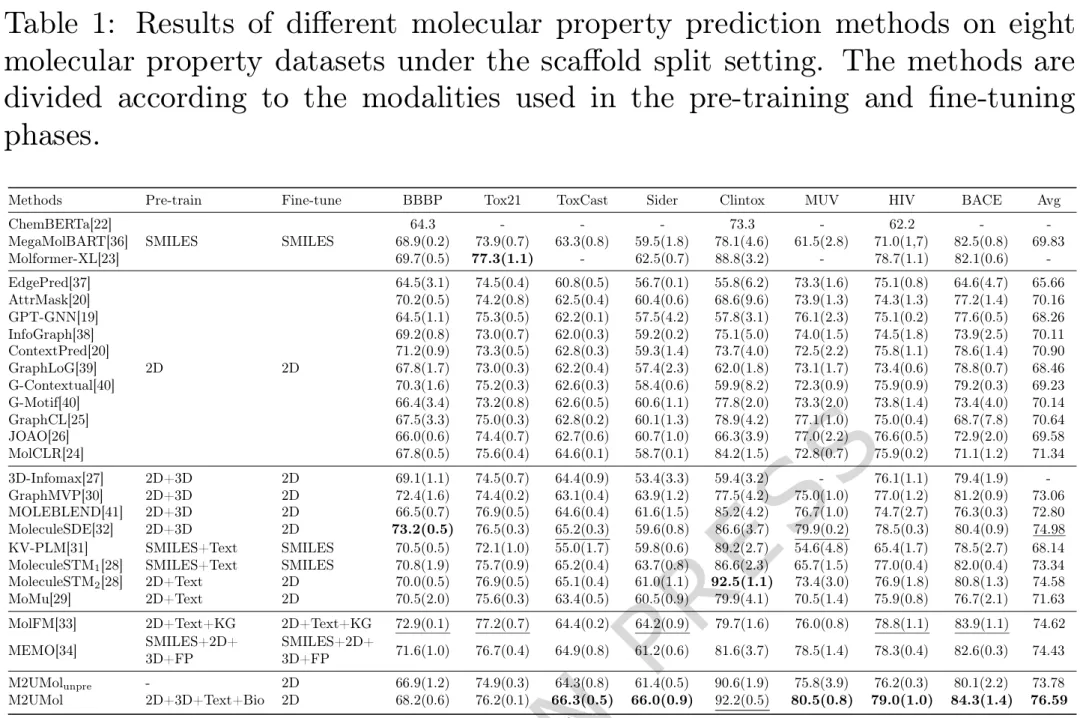
▲ Table 1 | 不同分子性质预测方法在八个数据集上的结果在分子性质预测任务中,M2UMol在MoleculeNet基准的八个数据集上进行了测试,涵盖物理化学、生物物理和生理学三类性质。如表1所示,在更具挑战性的scaffold split评估设置下,M2UMol在多数数据集上取得了最优或次优性能,尤其在BBBP、Tox21、SIDER和ClinTox等数据集上展现出显著优势。值得注意的是,M2UMol仅使用约1.1万个分子进行预训练,而对比方法通常需要数百万分子,这充分体现了框架的高效性和可扩展性。
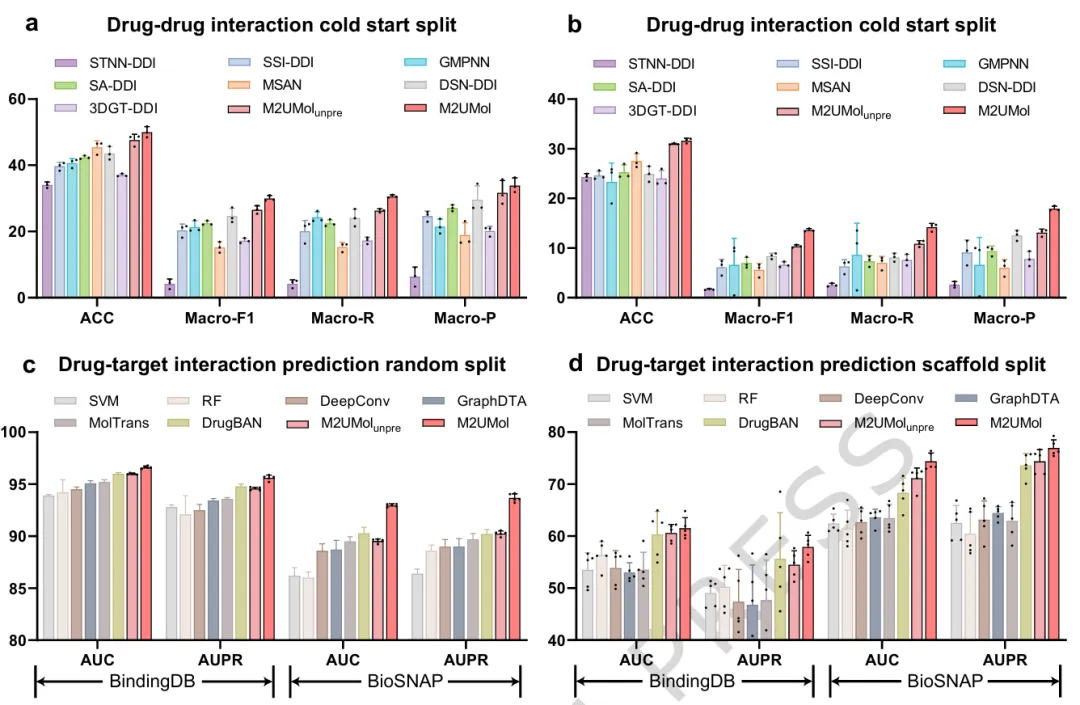
▲ Fig.2 | M2UMol与基线方法在分子相互作用预测任务上的结果。在分子相互作用预测任务中,研究团队评估了药物-药物相互作用和药物-靶点相互作用预测性能。实验结果表明,M2UMol在多个评估指标上均优于现有方法,验证了多模态知识迁移策略在复杂分子关系建模中的有效性。
多模态知识迁移的有效性验证
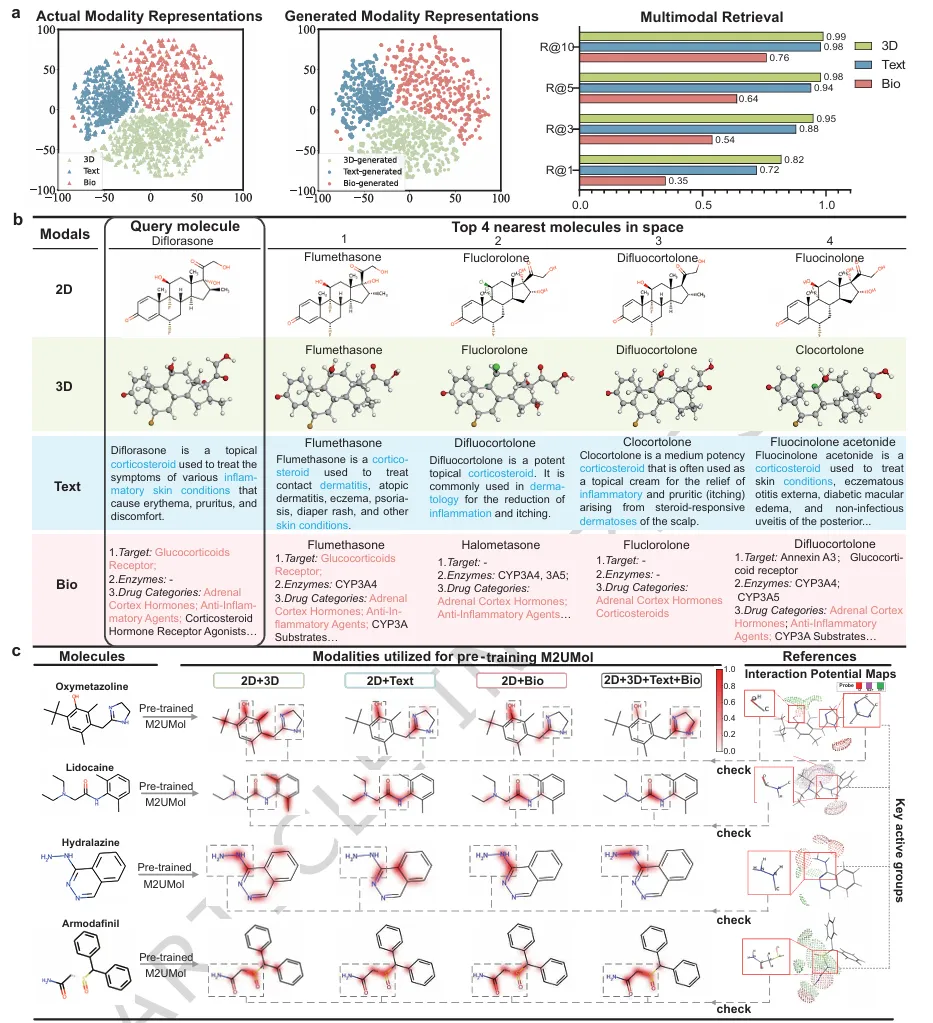
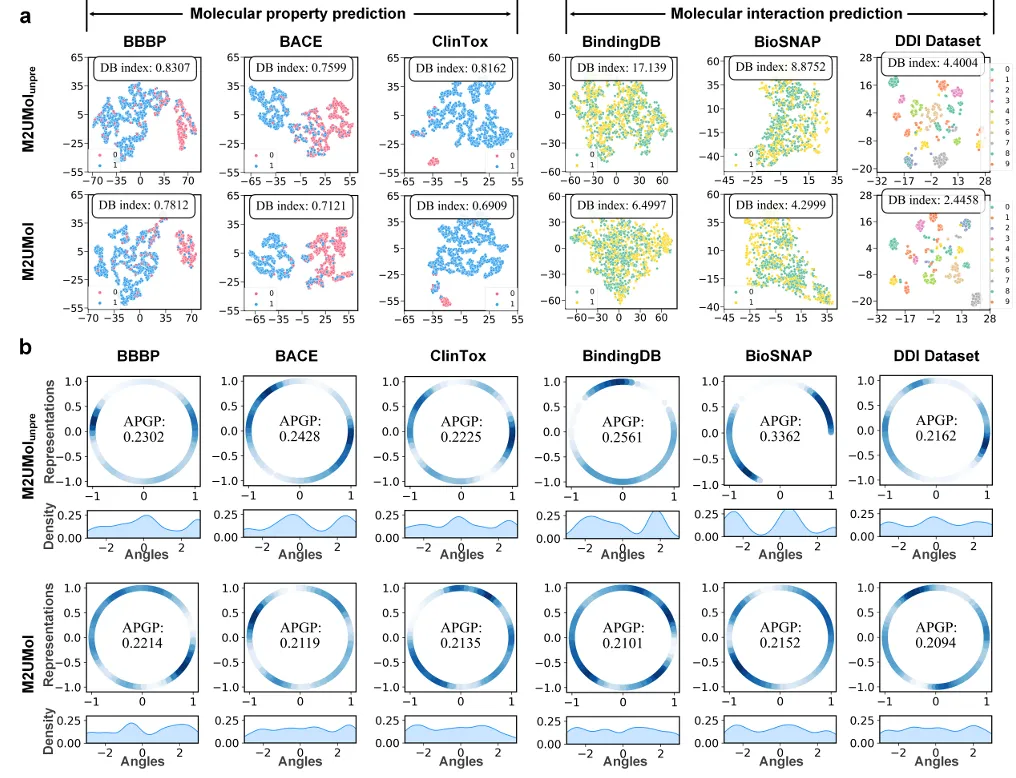
▲ Fig.3 | 所设计的多模态到单模态知识迁移预训练的研究。为深入理解M2UMol的工作机制,研究团队设计了多组消融实验和可视化分析。通过对比不同模态组合的预训练效果,证实了多模态信息的互补性对提升分子表示质量的重要作用。表示空间的可视化分析显示,M2UMol学习到的分子表示具有良好的区分性和均匀性,能够有效区分不同性质的分子。
此外,研究团队还验证了生成的伪多模态表示的质量。通过多模态检索实验,证实适配器生成的表示能够准确匹配对应的真实多模态数据,表明知识迁移过程保留了模态特异性信息。
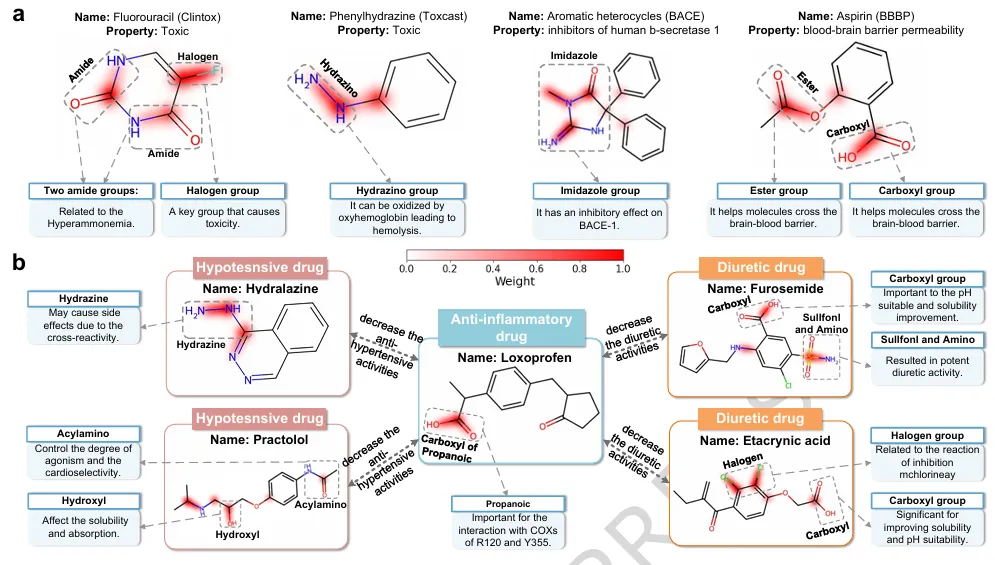
可解释性与实用工具
▲ Fig.5 | 各下游任务中分子的可视化,用于探究M2UMol提供的洞见。M2UMol不仅提供准确的预测,还具备良好的可解释性。通过注意力权重分析,可以识别对预测结果贡献最大的分子子结构,为药物设计提供有价值的参考信息。研究团队基于M2UMol开发了用户友好的软件包,集成了分子表示学习、关键功能基团分析、多模态数据检索等功能,可便捷应用于药物发现的多个环节。
总结与展望
M2UMol通过创新的多模态到单模态知识迁移策略,有效解决了现有多模态预训练方法对模态完整性的依赖问题。该框架仅需少量多模态数据即可完成高效预训练,并在下游任务中仅依赖二维分子图即可获得多模态增强的表示,显著提升了方法的实用性。实验结果验证了M2UMol在多项分子任务中的优越性能和高效率。
该研究为分子表示学习领域提供了新的技术范式,对于面临类似模态缺失挑战的其他多模态学习任务也具有借鉴意义。未来研究可进一步探索更多模态的融合策略,以及在更大规模数据上的预训练效果。相关代码、预训练权重和软件包已开源,可供研究者在药物发现相关领域中使用。
参考文献:Xiong, Z., Wang, Z., Huang, F. et al. Multi-to-uni modal knowledge transfer pre-training for molecular representation learning. Nat Commun (2026). https://doi.org/10.1038/s41467-026-69302-6
本文由AI4Mat前沿编译分享,旨在学术交流。文中所有图文版权归原作者及出版社所有。
关注我们,获取更多AI+材料前沿进展

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
