学完前两课,我对AI能做什么、不能做什么,大概有了个模糊的轮廓。
这次讲课的Andrew教授没有继续讲概念,而是挨个拆解了不同岗位正在被AI改变的方式——销售、招聘、市场营销、制造业、农业……
这次的笔记,就围绕三个问题展开:
☆ 机器学习项目怎么做?
☆ 数据科学项目怎么做?
☆ 以及,它们会怎么影响你我这样的普通人?
用一个最简单的例子:让智能音箱听懂“Alexa”这个词。
第一步:收集数据
首先得找人录音——说“Alexa”的,说“你好”的,说其他乱七八糟词的,统统录下来。每个音频片段都要标注清楚:这一段说的是什么。
这就是机器学习的基础:喂数据。
第二步:训练模型
把音频作为输入A,把“是不是Alexa”作为输出B,让算法去学。
第一次跑出来的结果大概率很烂——把“你好”识别成Alexa,把Alexa识别成“你好”。没关系,调参数、改模型、再跑。反复很多次,直到效果勉强能看。
这个过程,就叫迭代。
第三步:派送模型
把训练好的模型装进智能音箱,送到用户手里。
然后问题来了——有用户说话有英国口音,但训练数据全是美国人录的。结果音箱死活听不出用户在说Alexa。
这时候就需要回收数据,把英国用户的语音加进去,重新训练,更新模型。
所以完整的流程其实是:
收集数据 → 训练模型 → 派送 → 回收新数据 → 再训练 → 再派送 → …
没有一次成型,只有不断循环。
另一个例子:自动驾驶识别其他车辆
同样的三步走:
1. 收集数据:拍一堆车前视角的图片,然后在每张图上手动标出其他车的位置(画框框)。
2. 训练模型:让算法学习“图片里的哪些像素是车”。一开始它会把树认成车,慢慢调整,直到能准确定位。
3. 派送模型:装车上路。然后发现——遇到高尔夫球车,它认不出来了。于是回收高尔夫球车的图片,再训练,再更新。
道理是一样的:AI不是一次性写好的代码,是喂数据喂大的孩子。
机器学习产出的是一个能用的系统(比如语音识别模型)。
数据科学产出的是一组能指导行动的见解(比如“海外用户运费太高,所以下单少”)。
例子一:优化电商销售漏斗
销售漏斗就是用户从“进网站”到“下单”的全过程:
访问网站 → 浏览商品 → 点进详情 → 加入购物车 → 进入支付 → 完成下单
第一步:收集数据
记录用户从哪来、看了多久、在哪一步退出、IP地址显示在哪个国家。
第二步:分析数据
数据团队可能会发现:
☆ 海外用户进入支付页的多,但最后下单的少——可能是国际运费太贵吓跑了
☆ 某些国家午休时间流量暴跌——大家睡觉去了,没人在线购物
第三步:提出假设和行动建议
☆ 把部分运费隐藏进商品价格里,让结算时没那么肉疼
☆ 午休时段少投广告,省点预算
然后执行,然后继续收集数据,继续分析,继续优化。
例子二:优化生产线
一个咖啡杯的生产流程:
混合黏土 → 捏成杯形 → 上釉 → 烧窑 → 质检
1.收集数据:黏土湿度、供应商、混合时长、窑温、烧制时间、成品有没有裂痕……
2.分析数据:数据团队可能发现——湿度低 + 窑温高 = 容易裂;而且中午外面暖和,窑温要相应调低。
3.提出建议:调整不同时段的湿度和温度参数。
执行后继续收集数据,继续优化。
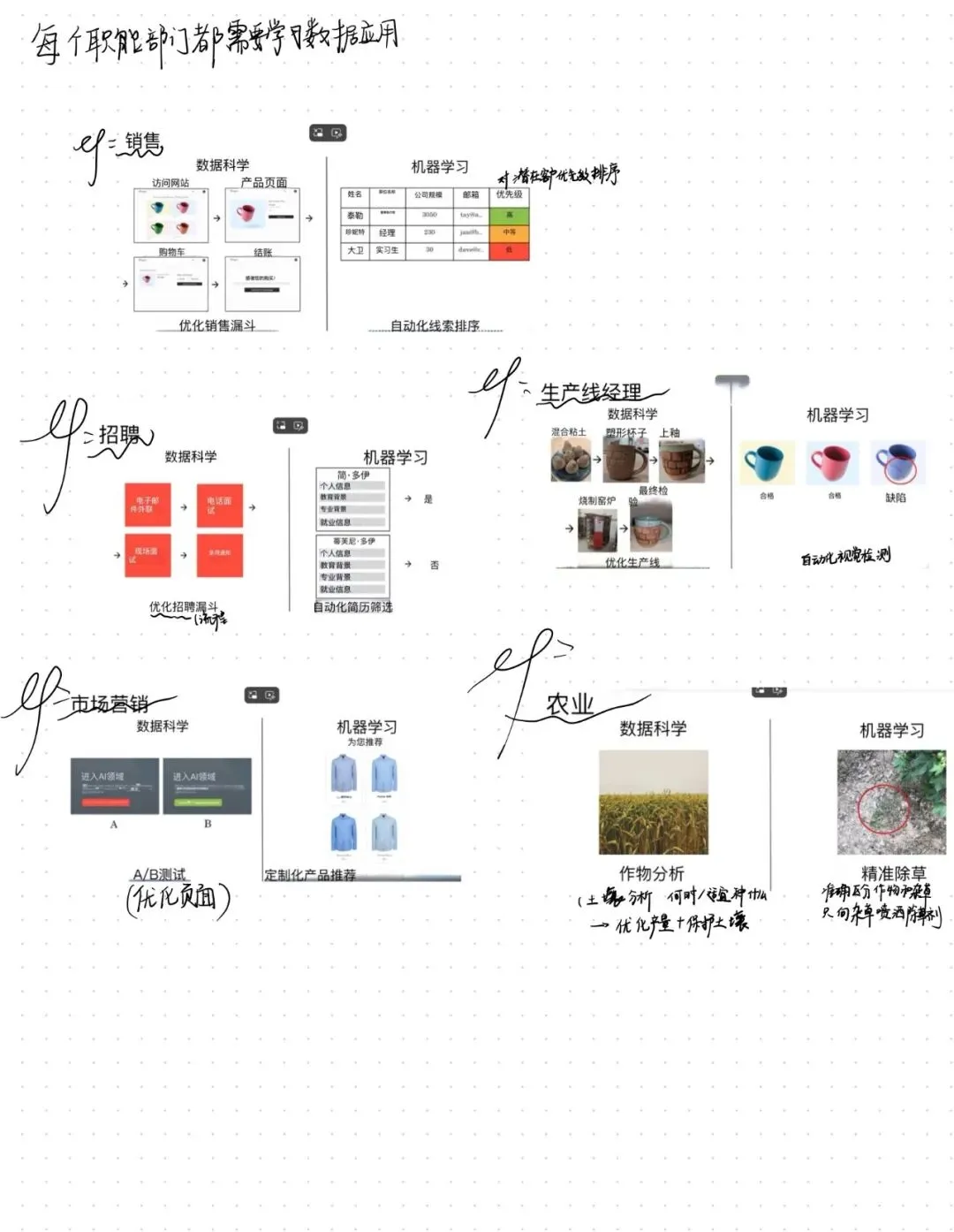
这一部分让我印象很深——教授挨个讲了不同岗位怎么被AI影响。
销售
☆ 数据科学:帮你分析销售漏斗,找出转化率低的环节
☆ 机器学习:帮你给潜在客户排序,优先联系大公司CEO,而不是实习生
招聘
☆ 数据科学:分析招聘漏斗,发现电话面试通过率太低,可能是面试官太严了
☆ 机器学习:自动筛选简历(但要注意算法偏见,不能因为性别、种族筛掉合适的人)
市场营销
☆ 数据科学:A/B测试,看红色按钮还是绿色按钮点击率高
☆ 机器学习:个性化推荐——你看过我买蓝色衬衫,下次就给你推蓝色衬衫
制造业
· 数据科学:优化生产线参数,减少次品率
· 机器学习:自动视觉检测,用摄像头识别咖啡杯有没有划痕
农业
☆ 数据科学:分析土壤、天气、市场价格,推荐什么时候种什么
☆ 机器学习:精准喷洒——拍张照片,识别出杂草,只喷除草剂在杂草上,不喷作物
第三课结束,我学到的是这些
1. 机器学习项目三步走:收集数据 → 训练模型 → 派送,然后循环
2. 数据科学项目三步走:收集数据 → 分析数据 → 提出行动建议,然后循环
3. 两者产出不同:机器学习产出系统,数据科学产出见解
4. AI正在渗透每一个岗位,不是将来时,是现在进行时
如果你也是AI小白,欢迎一起慢慢学。、