农业机器人为什么开始研究果实的六维姿态?
- 2026-06-27 16:51:10

图片由AI创作
本文清研智慧农业原创整理
清研智慧农业源于清华装备院智能系统与大数据分析研究中心
“专注农业自动化非标定制研发”

农业机器人的视觉任务主要是“找果实”。
相机在画面中识别出一颗草莓,再通过深度信息计算它离机器人多远,看起来已经足以完成采摘。但机械臂真正靠近后,问题很快暴露出来:机器人知道果实在哪里,却不知道它朝向哪里、果柄在哪一侧,也不知道末端执行器应该从哪个角度接近。
2026年,美国佛罗里达大学与普渡大学联合团队,把研究重点放在了草莓的“六维姿态”上。
这不是视觉模型又多输出了几个参数,而是农业机器人开始尝试回答一个更接近作业的问题:这颗果实应该怎么下手?
不同训练配置下的6D姿态估计定性结果(采用DINOv2-B骨干网络)。各列分别对应:真值(GT)、仅使用合成数据训练(Syn),以及分别使用递增量的真实数据训练得到的模型(R1、R3、R6、Real)。坐标轴采用颜色编码:X轴(红色)、Y轴(绿色)、Z轴(蓝色)。仅使用合成数据训练所得姿态在所有场景中均与真值相差甚远。即使仅加入一组真实数据(R1),误差也大幅减小;随着真实数据比例增加,预测结果逐渐逼近真值。来自康奈尔大学arXivFrom《 Simulation to the Real-World: An In-Field 6D Pose Datasetand Baseline for Robotic Strawberry Harvesting》

01
知道果实在哪
不等于知道怎么摘
普通目标识别解决的是二维位置:果实出现在画面的哪个区域。
加入深度信息后,机器人可以进一步获得果实在空间中的三维位置,也就是左右、上下和前后三个方向的坐标。
六维姿态则在三维位置之外,再增加三个方向上的旋转信息。
通俗地说,它不仅要知道草莓悬挂在哪里,还要知道草莓是竖着、斜着还是横着,尖端朝向哪里,果柄位于哪个方向。
这种差别对人来说并不明显。毕竟人看到一颗倾斜的草莓,会自然调整手腕,从侧面托住果实,再避开叶片和旁边果实。
机器人却需要把这种判断拆成明确的空间参数。
同样位于一个坐标点上的两颗草莓,如果一颗果柄朝上、果尖朝下,另一颗被枝叶挤压后横向倾斜,机械臂就不能使用完全相同的接近路径。末端姿态不变,可能导致夹爪碰到果肩、从果实表面滑落,或者在进入时撞上周围叶片。
因此,三维位置告诉机器人“去哪里”,六维姿态才开始回答“以什么角度去”。
02
六维姿态
真正建立的是一个动作坐标系
六维姿态最重要的价值,并不是把果实描述得更精细,而是给机械臂提供一个可以执行动作的局部坐标系。
以草莓为例,研究团队把果柄方向定义为果实坐标系的一条主轴。只要这条轴被估计出来,机器人就可以据此安排末端方向,判断从果实侧面还是底部接近,并使夹爪尽量避开柔软表面和周围遮挡。
对于苹果,这套信息可以服务于吸附位置和旋拧方向;对于番茄和甜椒,则可以帮助机器人区分果实主体、果柄方向与切割区域;对于香蕉、茄子等形状更长的对象,姿态还会直接决定抓取点和承托方式。
六维姿态因此处在机器视觉与运动控制之间。
它把“画面中有一颗果实”,转化成“机械臂可以按照某个方向接近”。
农业视觉也由此从对象识别,进一步走向动作生成。
该团队提出了一种六自由度(6DoF)位姿与三维尺寸估计器,能够在单次观测中同时估计所有草莓实例的尺寸和位姿。值得强调的是,该方法能够识别此前未见过的草莓,且无需依赖任何特定的草莓CAD模型。为训练模型,该团队构建了一个专用于草莓六自由度位姿与三维尺寸估计的合成数据集,命名为Straw6D(上图)。此外,该团队的模型在真实图像上展现出了从模拟到现实的迁移能力(下图);源于康奈尔大学arXiv《Single-Shot 6DoF Pose and 3D Size Estimation forRobotic Strawberry Harvesting》由格罗宁根大学伯努利研究所人工智能系团队发布

03
为什么直到2026年
研究才开始向真实农场推进
六维姿态在工业机器人领域并不是新概念。
工厂里的零部件尺寸固定,有准确的三维模型,摆放环境和光照也相对稳定。算法可以拿着零件的标准模型,与相机图像进行匹配,再计算它的位置和方向。
水果完全不同。
两颗草莓不会拥有完全相同的大小、轮廓和表面形状。即使属于同一品种,它们也会因成熟度、生长位置和挤压状态出现差异。果实还会被叶片遮挡、成串重叠,并在风、机械臂接触和枝条回弹下发生运动。
这意味着,工业机器人常用的“一个零件对应一个精确三维模型”,很难直接照搬到农业。
此前已有国外团队尝试利用仿真环境生成草莓的六维姿态和尺寸数据。
模型可以在虚拟场景中自动获得准确坐标,不需要人工逐张标注,甚至能够达到较高的运行速度。
但真正的问题一直没有被充分回答:在仿真环境中学会判断姿态的模型,进入真实草莓田后还能不能工作?
本文推荐的这项研究第一次针对这个问题建立了真实田间草莓六维姿态数据集。团队在实际农场采集了12040张图像,标注了16037个草莓实例,并通过相机标定、三维重建和三维包围框标注,建立果实相对于相机的位置与方向。
这项工作的意义,不只在于数据量,而在于它第一次让研究者能够直接比较虚拟果实和真实果实之间的差距。
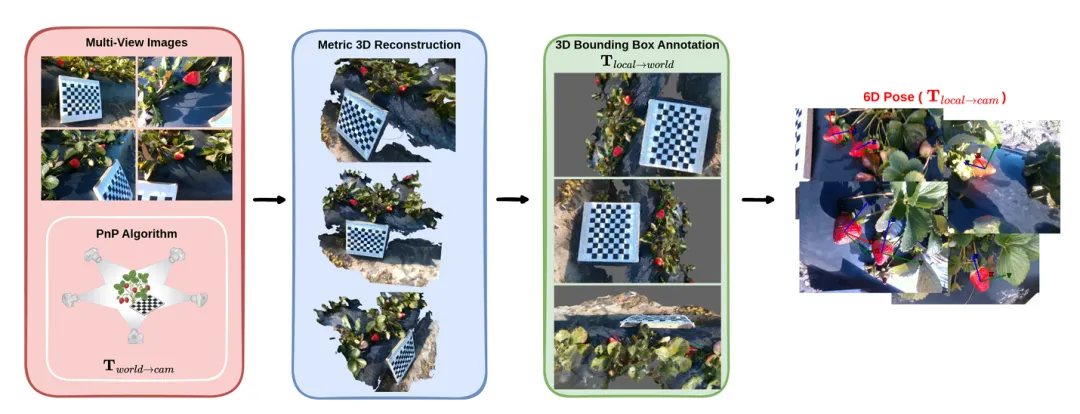
真实世界数据集构建流程概述。首先,在草莓植株附近放置棋盘格并录制视频序列,然后对每一帧应用PnP算法估计世界到相机的变换矩阵 Tworld→camTworld→cam 。同时,使用COLMAP进行公制三维重建,并在生成的点云上手动标注三维边界框,以获得 Tlocal→worldTlocal→world 。与此同时,在RGB图像帧上手动标注二维边界框。最终,六自由度位姿真值通过 Tlocal→cam=Tworld→cam⋅Tlocal→worldTlocal→cam=Tworld→cam⋅Tlocal→world 合成。来自康奈尔大学arXivFrom《 Simulation to the Real-World: An In-Field 6D Pose Datasetand Baseline for Robotic Strawberry Harvesting》
04
一个残酷结果
能识别,不代表能判断姿态
研究结果揭示了一个非常典型的农业视觉问题。
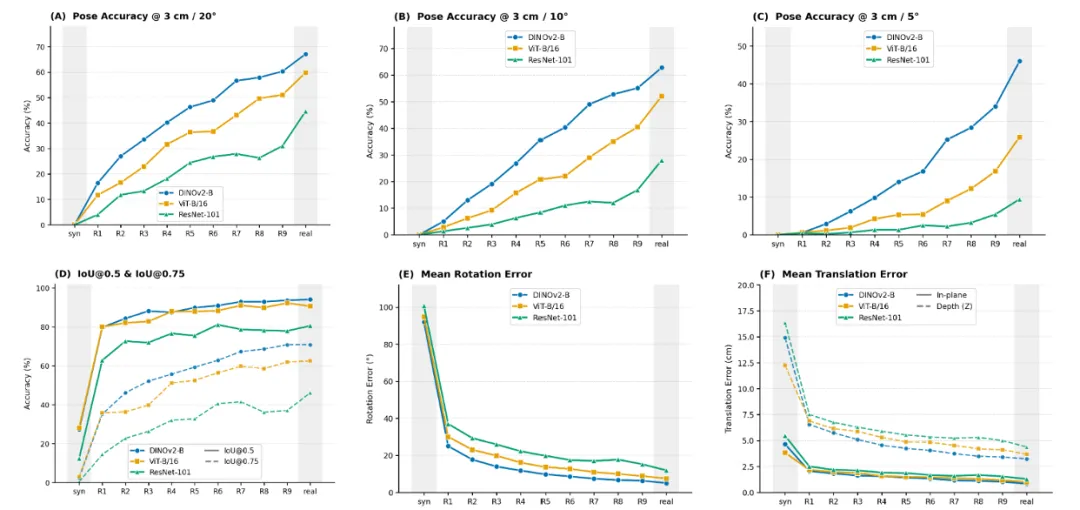
在论文设定的联合位置与角度阈值下,只使用合成数据训练的模型,在真实田间图像上的六维姿态准确率为零,多种模型的平均旋转误差均超过90度。
这并不意味着模型完全看不到草莓,而是说明它即使找到了目标,也无法可靠判断真实果实的空间朝向。
当训练数据中加入10%的真实图像后,表现迅速改善。其中一组模型的平均旋转误差从91.9度下降到25度,二维检测表现也明显提高。继续增加真实数据后,目标检测较快趋于稳定,但六维姿态仍然持续改善。
这组差异说明,识别“画面里有没有草莓”相对容易迁移;判断草莓在三维空间中究竟如何倾斜,则需要模型理解更细的轮廓、遮挡和几何关系。
模型可以很快学会认出一颗草莓,却很难仅凭虚拟图像学会判断真实草莓如何悬挂。
05
最难估计的
还是前后距离
论文还发现,在仅使用单目彩色图像时,深度方向仍是六维姿态估计中的主要瓶颈。
使用全部真实数据训练后,表现最好的模型在图像平面方向上的平均位置误差约为0.83厘米,前后深度误差却达到3.23厘米,接近前者的四倍。
这个差距会直接传递到机械臂。
画面中的左右误差较小,末端仍可能对准果实;但如果前后距离判断错误,机械臂可能提前闭合、碰撞果实,或者停在目标前方抓空。
因此,六维姿态研究并没有证明单目相机已经足够。
恰恰相反,它把长期隐藏在“识别准确率”之后的深度误差暴露了出来。
未来的实际系统仍可能需要把彩色图像、深度相机、多视角观察和机械臂运动结合起来,在接近过程中不断更新果实姿态,而不是只在远处计算一次坐标。
不同主干网络架构和训练配置下的基线结果。 Syn表示仅使用合成数据训练;R1–R9表示混合训练集,其中包含10%–90%的真实数据;Real表示仅使用真实数据训练。各子图展示了不同旋转阈值下的姿态精度、二维检测质量、平均旋转误差以及分解后的平移误差。灰色阴影区域表示仅使用合成数据和仅使用真实数据的训练配置。(A–C)分别是在平移误差3cm、旋转阈值20°、10°和5°下的姿态精度。(D)二维检测质量(IoU@0.5和IoU@0.75)。(E)平均旋转误差。(F)分解为平面内(ϵx2+ϵy2ϵx2+ϵy2)和深度(ϵzϵz)分量的平均平移误差。来自康奈尔大学arXivFrom《 Simulation to the Real-World: An In-Field 6D Pose Datasetand Baseline for Robotic Strawberry Harvesting》
06
果实的姿态
也不是一个完全确定的答案
农业对象还存在一个特殊问题:它们经常具有近似对称性。
草莓大体围绕果尖到果柄的主轴对称。
从某些方向看,果实绕这条轴旋转一定角度后,画面中的外形几乎没有变化。算法很难判断它究竟旋转了多少。
同时,六维姿态通常用一个三维包围框或简化模型表示果实,但真实果实并不是刚性几何体。它会变形,表面不同区域的承压能力也不同。
因此,六维姿态并不能直接等同于最佳抓取点。
它能够告诉机器人果实大致朝向哪里,却不能单独回答果柄是否被叶片遮挡、夹爪落在哪一块表面最安全、周围是否存在足够的进入空间,以及果实受到接触后会如何移动。
真正完成采摘,还需要果柄检测、实例分割、局部表面重建、避障规划、视觉伺服和力反馈共同参与。
六维姿态是一座桥,但还不是完整的采摘方案。
07
农业视觉正在从“看懂”走向“能动手”
六维姿态成为研究重点,反映出农业机器人正在跨过一个重要阶段。
过去的模型主要回答“这是什么”和“它在哪里”;现在的模型开始回答“它以什么状态存在”和“机械臂应该如何接近”。
两者之间的差别,正是图像识别与机器人作业之间的差别。
这也会改变农业数据的价值。
未来真正服务机器人的数据,不会只包含果实框、成熟度和分割轮廓,还需要记录果实朝向、果柄轴线、可抓取区域、接近方向和碰撞空间。
数据不再只描述对象,而要能够支撑下一步动作。
但2026年的研究也给行业泼了一盆冷水:即使已经建立较真实的虚拟农场,仅依靠合成数据仍无法可靠处理真实田间的六维姿态。真实作物、真实遮挡和真实相机条件,仍然是农业机器人不可绕开的训练基础。
因此,农业机器人未来的竞争,不只是看谁拥有更大的视觉模型,还要看谁能建立真实场景数据、动作标注和执行反馈之间的闭环。
清华大学天津高端装备研究院智能系统与大数据分析研究中心围绕机器视觉、三维感知、视觉伺服、柔性末端和机器人控制开展农业场景研发。对于采摘项目,研究中心关注的不只是把果实识别出来,而是继续判断果实姿态、可抓取区域与接近路径,并将这些视觉结果真正转化为机械臂能够稳定执行的动作。
农业机器人研究六维姿态,最终不是为了把果实看得更复杂,而是为了让机器第一次真正知道,该从哪里伸手。
#智慧农业#农业机器人#采摘机器人#清华农业#农业机器人开发#农业机器人定制研发#农业机器人研发找陈灏#清华装备院陈灏#农业自动化
清研智慧农业
清华大学天津高端装备研究院智能系统与大数据分析研究中心,聚焦软件、智能装备、大数据与人工智能技术,面向智慧农业、农业自动化、农业机器人及设施农业场景,提供非标装备研发、机器视觉与智能感知、农业大模型、系统集成及智慧农业规划运营等服务。
中心依托研究院高端装备与工程转化能力,构建五大农业工程团队,推动工业级技术在农业生产、加工与园区项目中的落地应用。



特别说明

本文部分内容(包括但不限于文字、图片、数据等)来源于互联网公开信息,旨在传递更多资讯,仅供学习交流之用。其版权均归原作者或原始出处所有。
为支持原创,本公众号会尽量标注来源。如您发现本公众号中有内容侵犯了您的合法权益,请立即通过后台留言或添加客服微信等方式与我们联系,我们将在核实后第一时间进行处理。
未经本公众号明确授权,任何个人或组织不得将本文内容用于商业性转载或摘编。转载请联系后台开白;凡从本公众号转载本文至其他平台所引发的一切纠纷、后果及法律责任,均由转载方自行承担,本平台概不负责。
*往期精选*
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 美好家园荣膺渭南现代农业市域产教联合体副理事长单位
- 自治区农业农村厅办公室关于印发2026年中央农业产业发展(渔业)资金项目实施方案的通知
- 第二弹!「十五五」农业农村现代化规划核心考点全拆解(公务员/考研必看)
- 来自四川农业大学的官方报道[庆祝][庆祝][庆祝]
- 2026年成都农业科技中心招聘编辑部主任
- 全省唯一“互联网+”现代农业产业园在花都顺利通过验收
- 陇南市西和县农业农村局党组书记、局长、四级调研员王平仲接受审查调查
- 中国农业科学院棉花研究所2026年高层次人才引进公告
- 盘锦把产业和文旅农业往三大片区里死磕,家门口的厂子和湿地总归让本地人换来了安稳饭碗
- 农业产业化国家级重点龙头企业,国家高新技术企业,固原宝发农牧有限责任公司产品实景图片
