《食品科学》:河北农业大学王树桐教授、李波副教授等:基于可解释性机器学习和高光谱成像技术的苹果表面农药异常残留无损检测
- 2026-06-23 18:47:30


1
光谱特征分析
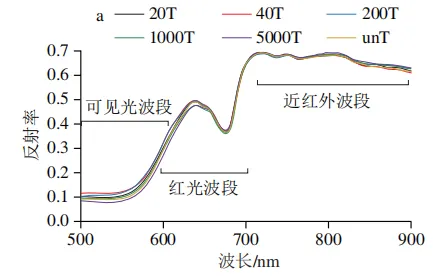
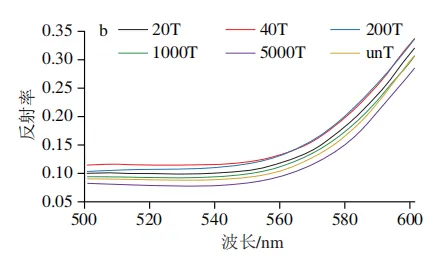
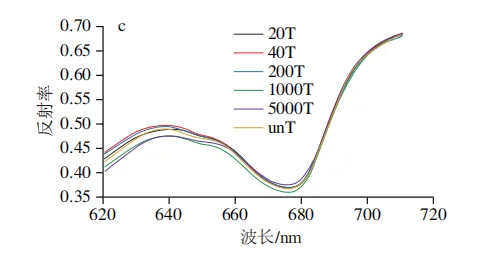
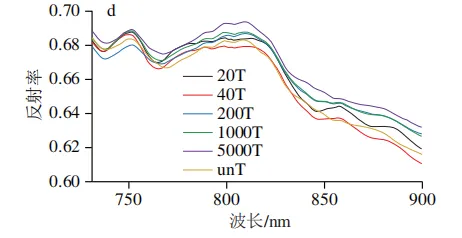
在不同戊唑醇残留梯度下,苹果表面的平均反射率曲线如图2所示,各个处理组的平均光谱曲线表现出相似的趋势,但在特定波段范围内表现出明显的质量浓度依赖性差异。在可见光波段(500~600 nm),苹果表面光谱反射率随波长的增加而上升,且随着戊唑醇残留量的增加,反射率呈先增加后降低的非线性变化规律,这通常与农药制剂在果面的分布差异有关。在红光波段(620~700 nm),戊唑醇残留量的增加引发的光谱反射率的变化在波峰和波谷处最为显著。在近红外波段(750~900 nm),戊唑醇残留量的增加导致反射率曲线出现明显的分离现象。该波段对有机物分子键合频与倍频振动具有较强响应,反射特征的系统性变化很可能源于戊唑醇分子中苯环、C—N等官能团的特征吸收。
 |  |
 |  |

2
光谱数据预处理分析
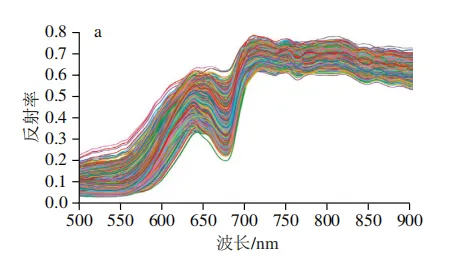
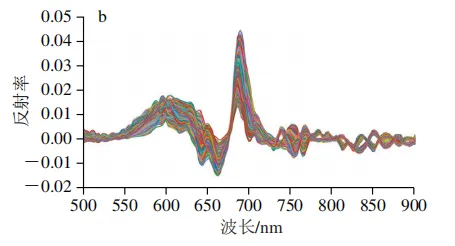
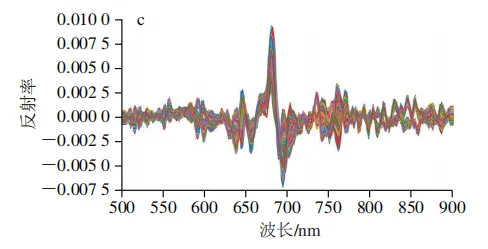
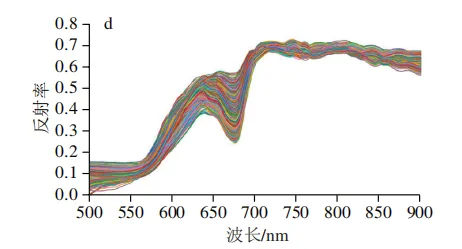
在原始全光谱数据中存在大量噪声,这些干扰信号会降低模型的判别精度。为提高模型的预测准确性与鲁棒性,本研究对原始数据进行SG平滑处理后,分别进行1D、2D和MSC等光谱预处理,经预处理后得到的光谱平均反射率曲线如图3所示。
 |  |
 |  |

3
预处理方法与全波段模型性能分析
为基于全光谱数据,结合多种预处理方法(RAW、1 D、2 D、M S C)与机器学习算法(P L S-D A、XGBoost、SVM、RF、LGBM、DT),构建了多种分类模型(表2)。通过系统比较不同组合在训练集与测试集上的性能,以确定较优的预处理方法与算法组合。
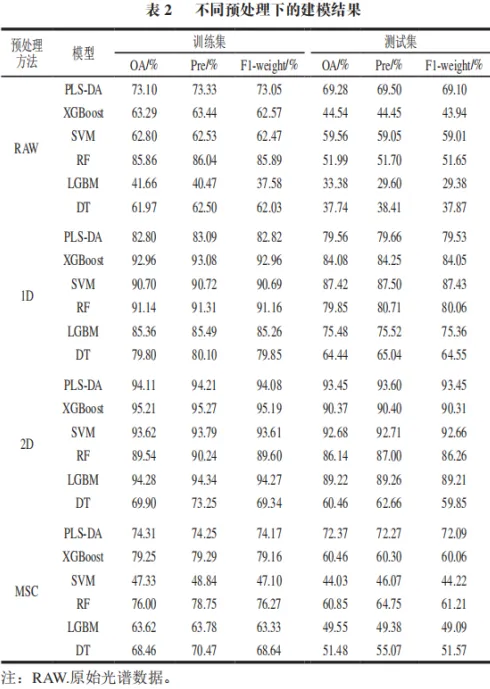
预处理方法对模型预测性能具有显著影响。原始光谱数据(RAW)所建模型性能普遍欠佳,且各模型的分类准确率存在较大差异。测试集最佳OA仅为69.28%(PLS-DA),而其余模型在测试集上的OA均低于60.00%,表明原始数据中存在大量噪声与冗余信息。经1D预处理后,所有模型的性能均得到显著提升。以SVM模型为例,其在训练集上的OA从62.80%提高至90.70%,F1-weight从62.47%提高至90.69%;在测试集上,OA和F1-weight也分别从59.56%和59.01%提升至87.42%和87.43%。XGBoost、PLS-DA和RF模型在测试集上的OA均超过79.00%,表明1D预处理有效抑制了光谱数据中的噪声干扰。经1D和2D微分处理后,所有模型性能均得到显著提升,其中2D预处理效果最为突出。2D-PLSDA和2D-SVM模型在测试集上的OA分别达到93.45%和92.68%,相比原始数据分别提高了24.17个和33.12个百分点,表明微分处理能有效消除基线漂移并放大细微光谱差异,从而增强了与戊唑醇质量浓度相关的特征信息。相比之下,MSC预处理的效果较为有限,仅对部分模型有轻微改善,未能显著提高模型在测试集上的分类性能。
综合比较不同预处理方法下各模型的分类表现,2D-PLS-DA模型在测试集上取得了最高的分类准确率(OA=93.45%)和F1-weight(93.45%),最适合本研究的分类任务,故后续特征筛选均基于2D预处理后的数据进行。
4
光谱数据降维和特征波长筛选
4.1 VIP
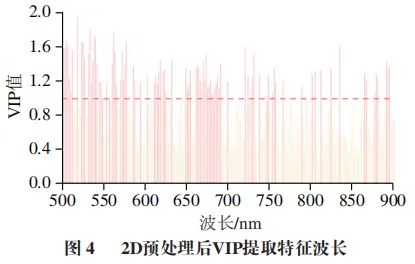
利用内置于PLS模型框架中的VIP算法,自动计算各波长变量的VIP得分。以VIP>1.0作为显著性阈值筛选特征波长,筛选结果如图4所示,从全光谱中共提取出95个关键特征波长,这些波长集中分布于500~600 nm与650~700 nm两个区域。
4.2 SPA
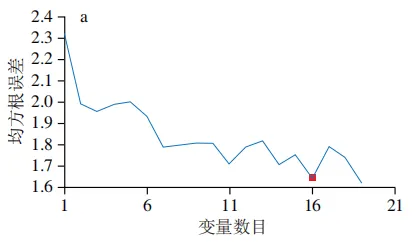
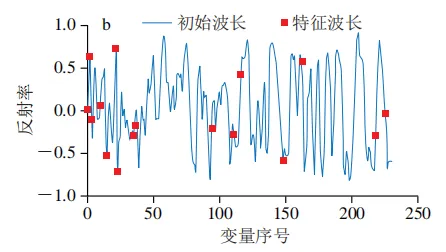
采用SPA进行特征波长筛选时,将最大特征波长数设置为30。如图5所示,随着所选波长数目的增加,均方根误差值先下降而后逐渐趋于平稳,表明模型误差在此阶段已达到最小值并趋于稳定,后续引入的变量不再提供有效信息。SPA最终优选出的特征波长变量数为16个,此时均方根误差值最低,为1.642。
 |  |
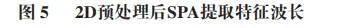
4.3 RFA
结合SHAP分析与RFA的策略以获取更具解释性的特征波长子集,基于SHAP值的RFA筛选过程如图6所示。首先,基于已构建的2D-PLS-DA模型进行SHAP分析,计算各波长变量的SHAP值,并取其绝对值以量化特征重要性,进而得到所有变量的重要性排序序列。随后,应用RFA算法,依据上述排序从高到低依次将波长变量加入模型,并逐次评估模型的分类性能。结果显示,随着特征波长数量的增加,模型的OA与F1-weight均呈现先快速提升后逐渐稳定的变化趋势。当特征波长数增加至51个时,模型性能趋于稳定,表明该特征子集已充分捕获关键判别信息,进一步增加变量数量对性能提升无显著贡献,故最终确定51个特征波长作为RFA筛选结果。
 |  |  |
5
基于特征波长的模型性能分析
如表3所示,基于不同特征子集构建的PLS-DA与SVM模型性能存在显著差异。总体而言,基于SHAPRFA算法筛选出的51个特征波长所构建的SVM模型,在训练集和测试集上的OA分别达到94.99%、94.87%,不仅显著优于其他特征选择方法所建模型,也略优于使用全部232个波段的模型(全波段-SVM OA=92.68%)。这表明SHAP-RFA在有效降低数据维度(降维率达78.02%)的同时,最大限度地保留了与分类最相关的关键信息。
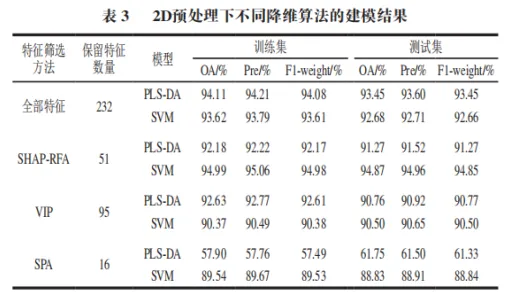
相比之下,基于VIP方法筛选95个特征波长所建立的PLS-DA与SVM模型,测试集性能(OA分别为90.76%和90.50%)虽低于全特征模型,但仍保持了可接受的分类能力,说明VIP筛选出的波长变量仍具较强判别力。SPA方法所筛选的16个特征波长所建的PLS-DA模型性能显著下降(测试集OA=61.75%,F1-weight=61.33%),表明特征数量过少导致有效信息丢失严重,不足以支撑模型获得良好泛化能力;然而同样基于SPA特征子集的SVM模型仍达到了88.83%的OA,体现出SVM算法在处理低维特征时仍具有较强的建模能力。
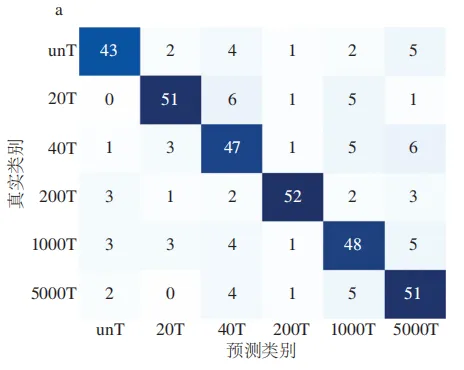
通过绘制2D-SHAP-RFA-SVM模型在最优参数下的混淆矩阵(图7)显示,绝大多数样本被正确分类,且误判主要发生在相邻低质量浓度组(如unT与5000T之间),而质量浓度差异大的组间几乎无混淆,表明模型能有效捕捉与质量浓度显著相关的光谱特征。
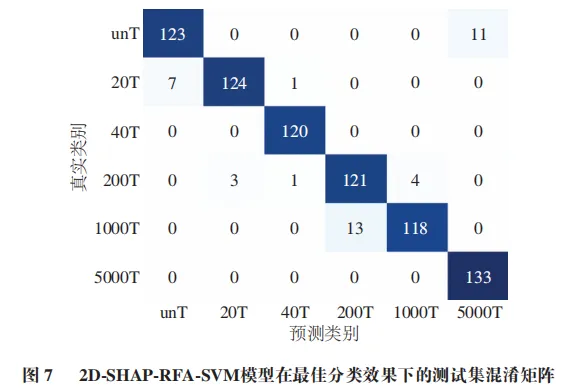
综合比较可知,2D-SHAP-RFA-SVM模型在测试集上表现最佳,其性能指标均超过94.50%,且所使用的特征数仅为全波长的21.98%,实现了在高精度分类的前提下大幅降低模型复杂度,因此可作为苹果表面戊唑醇异常残留判别的最优模型。
6
SHAP特征重要性分析
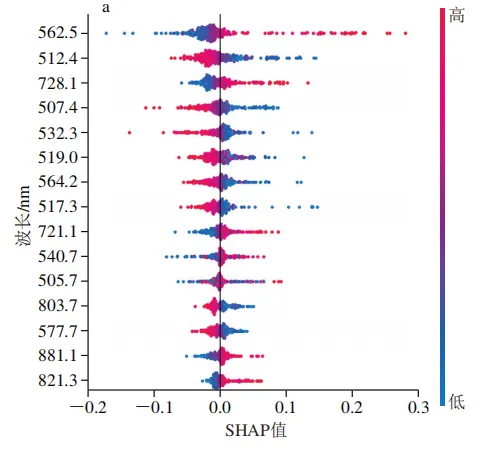
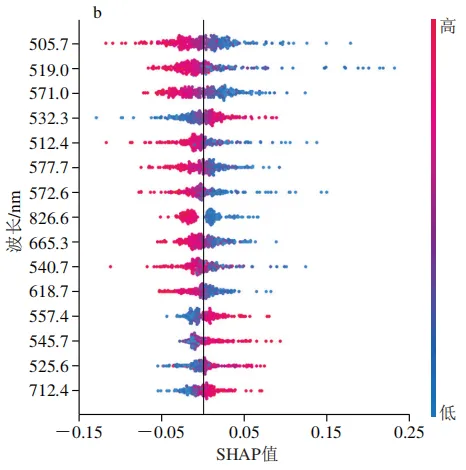
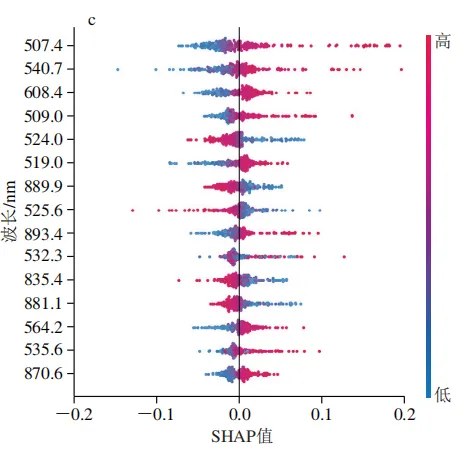
为解析最优模型的决策机制,本研究对2D-SHAPRFA-SVM模型特征贡献进行了可解释性分析。SHAP蜂群图(图8)展示了各质量浓度类别下重要波长的SHAP值分布情况。SHAP分析表明模型的分类决策依赖于一个由可见光与近红外波段共同构成的复杂特征谱,而非单一波段。以20T类别为例(图8a),重要性前15的波长中562.5、728.1、721.1、540.7、881.1、821.3 nm的特征值分布与SHAP值呈正相关,即该处特征值升高会显著增加模型将样本预测为20T类的概率。关键波长同时涵盖了500~600 nm的可见光波段与700~900 nm的近红外波段。
 |  |  |
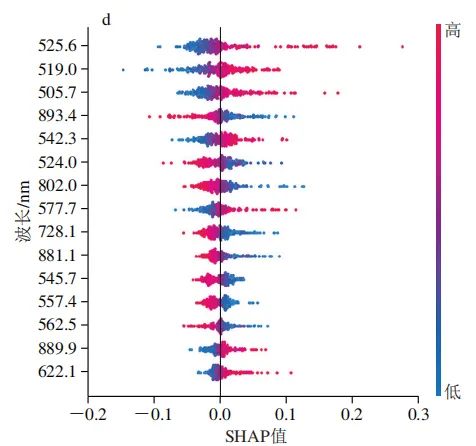 | 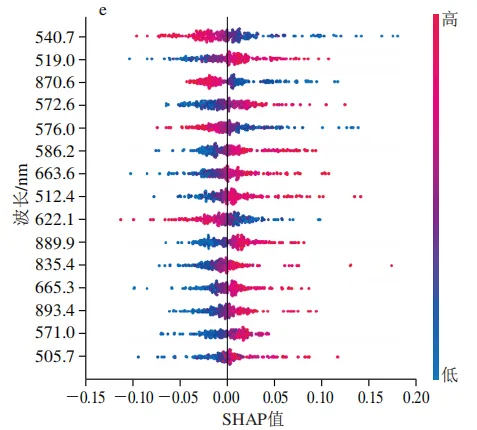 | 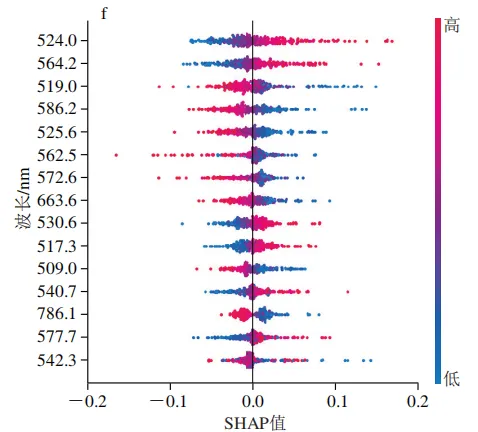 |

这种多波段协同决策的模式在所有类别中均存在,但主导波段与质量浓度梯度均有直接关联。在低质量浓度类别(5000T)中,关键波长分布较为广泛,可见光波段与近红外波段特征共同发挥着重要作用;在中质量浓度类别中(40T、200T、1000T)中,主要由可见光波段占据分类决策的基础;而在高质量浓度类别(20T)中,近红外波段的贡献趋于主导地位。SHAP分析清晰地揭示了这种随质量浓度梯度变化的差异化特征重要性,描绘了模型决策路径的动态转变。这一发现为探索模型决策机制背后的生物物理学基础提供了关键见解。
图9进一步展示了全局重要性排名前15的特征波长,所选特征在不同类别判别中表现出差异化的影响力。
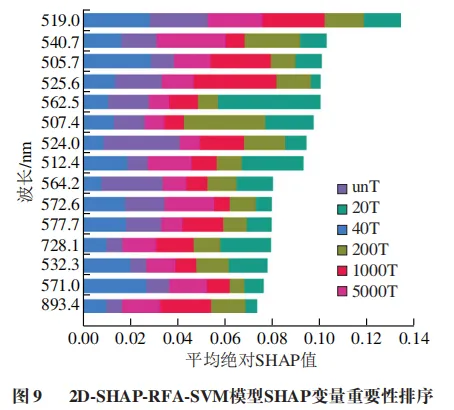
其中,波长519.0 nm对模型输出的总体贡献最大。特征波长多集中于500~600 nm波段内,其或与戊唑醇药剂在苹果表面的不均匀分布密切相关,该结果将特征波长对数据的贡献与潜在的理化机理相关联,极大地增强了模型的可信度和可解释性。SAHP特征重要性分析为理解模型决策过程及特征波长优化提供了有效工具。
7
模型的时间泛化性验证
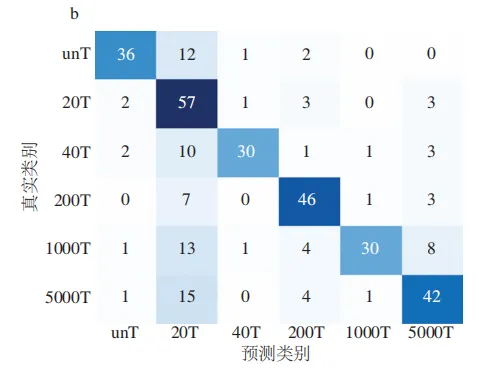
模型的跨期验证结果呈现出性能衰减趋势。基于相同的处理方法获取的自然渗透8 d和15 d的样本数据,采用2D-SHAP-RFA-SVM模型进行分类,其模型准确率分别降至78.07%与70.67%(图10)。该结果表明,模型所依赖的关键光谱特征与农药未充分降解的高质量浓度初始状态高度相关,这与建模数据来源于为自然渗透1 d的样本相符。随着贮藏时间的延长,果实表面戊唑醇的降解以及苹果自身代谢所引起的理化性质变化,共同导致了光谱特征的动态演变。这些新特征在一定程度上会掩盖由初始农药残留所主导的光谱响应模式,致使原有判别特征的显著性逐渐减弱,其说明模型性能衰退主要源于模型学习特征与动态变化的样品状态之间关联性的失效。
 |  |

8
讨 论
本研究聚焦于采前应急喷施或采后浸泡等违规行为导致的高风险农药残留问题,通过HSI技术与机器学习算法相结合,实现了苹果表面戊唑醇异常残留的精准、无损判别。研究结果表明,随着戊唑醇残留质量浓度的增加,苹果表面光谱在可见光与近红外区域的反射特性呈现系统性变化。该现象与戊唑醇制剂中载体物理特性、药剂分布均匀性所引起的光散射效应,以及戊唑醇分子中苯环、C—N键等官能团的振动吸收密切相关。这一发现为基于光谱技术判别农药残留提供了可靠的物理化学依据。
尽管原始光谱数据可用于构建预测模型,但高维数据中存在的冗余信息和噪声干扰往往导致模型计算效率降低和分类精度下降。因此,光谱预处理已成为高光谱建模中的关键环节。在本实验中,2D预处理在6种机器学习模型中均显著提高了模型性能,这主要是因为微分运算能够有效消除基线漂移和背景干扰,并放大由微量农药残留所引起的细微光谱差异。邓昀等建立林地土壤有机质反演模型时同样发现1.25阶导数处理可以有效提高模型精度。
9
结 论
本研究基于HSI技术与机器学习算法,实现了苹果表面戊唑醇农药残留等级的精准分类,主要结论如下:1)在苹果表面施用梯度质量浓度戊唑醇后,其光谱在可见光和红外区域呈现显著质量浓度依赖性差异;2)在相同分类模型框架下,不同预处理对模型分类准确率有直接影响,2D预处理后建模效果优于1D、MSC预处理;3)基于2D预处理数据,SHAP可解释性分析结合RFA算法,筛选出51个特征波长,所构建的SVM模型(2D-SHAPRFA-SVM)在分类性能上显著优于全波段模型,分类准确率达到94.87%,在数据降维与提升预测精度之间取得了最优平衡;4)SHAP分析精准解析特定农药残留等级的关键响应波长,为模型优化及专用传感器设计提供理论依据;5)模型的时间泛化性验证说明构建稳健的农药残留检测模型应考量农药与基质本身的时变特性,避免因样品状态动态演变而导致的模型性能衰退。更重要的是,本研究聚焦探讨农残检测模型从追求“精度”到追求“精度与可解释性并重”的范式转变,为人工智能技术在农业传感中的可信、可靠应用提供了数据支撑。
作者简介

李波,副教授,硕士生导师,河北农业大学“青年才俊”引进人才,国家苹果产业技术体系病虫害防控研究室团队成员,研究领域为作物真菌病害流行预测及高光谱遥感技术在苹果病害早期识别与预警中的应用转化工作,助力提升果园病害管理的智能化水平。以第一作者或通信作者在Frontiers in Plant Science、Biological Control、Plant Disease、Frontiers in Microbiology 、International Journal of Molecular Sciences等期刊发表论文8 篇。主持河北省科技厅、教育部国际合作与交流司等部门科研基金6 项。

实习编辑:李杭生;责任编辑:张睿梅。点击下方阅读原文即可查看全文。图片来源于文章原文及摄图网
近期研究热点



为了帮助食品及生物学科科技人员掌握英文科技论文的撰写技巧、提高SCI期刊收录的命中率,综合提升我国食品及生物学科科技人员的高质量科技论文写作能力。中国食品杂志社拟定于2026年8月13—14日在安徽合肥举办“第13届食品与生物学科高水平SCI论文撰写与投稿技巧研修班”,为期两天。

长按或微信扫码进行注册

长按或微信扫码进行注册
为对标农业农村部2035年科技规划及“十四五”“十五五”发展方向,推动农产品加工与储运的工程化、智能化、绿色化升级,由湖南省农业科学院、湖南农业大学、北京食品科学研究院、国际食品科技联盟(IUFoST)、中国农业大学、岳麓山工业创新中心主办,湖南大学、中南林业科技大学、长沙理工大学、湖南中医药大学、湘潭大学、岳麓山实验室协办,中国食品杂志社、洞庭实验室、湖南省食品科学技术学会、湖南省农产品加工与质量安全研究所、湖南农业大学食品科学技术学院、Springer Nature-《Agricultural Products Processing and Storage》杂志承办的“第二届农产品加工与食品制造国际学术研讨会—创新引领绿色智造,AI赋能科技进步”,将于2026年9月19-20日(9月18日会议报到)在中国 湖南 长沙召开。

长按或微信扫码进行注册
会议招商招展
联系人:杨红;电话:010-83152138;手机:13522179918(微信同号)

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 精准协商献良策 延链增值兴农业——扶绥县政协助力特色农业产业集群提质增效
- 【农业系列职称】关于做好2026年度全省农业系列职称申报评审工作的通知
- 耀州区政协经济和农业农村委员会、经济和农业农村工作室开展委员读书活动
- 农业也能很硬核!首农用中关村精神“种出”农业新质生产力
- 梅雨期渔业生产管理防范措施
- 黑龙江北大荒农业股份有限公司关于补缴税款相关事项的公告
- 2026年上海市农业广播电视学校(上海市农民科技教育培训中心)公开招聘工作人员公告
- 农业银行化隆支行:守护金融权益 数智温暖民生
- 【农业良种工程】关于2026年省重点研发计划(农业良种工程)拟立项项目公示的通知
- 中国援基里巴斯农业技术首期培训班毕业典礼隆重举行
