农业机器人“视觉识别”的核心瓶颈
- 2026-06-23 23:44:38

图片由AI创作
本文清研智慧农业原创整理
清研智慧农业源于清华装备院智能系统与大数据分析研究中心
“专注农业自动化非标定制研发”

训练集里的精度,是开卷考试。
01
训练集精度
不等于田间可用
过去几年,关于农业视觉识别论文很多。
有人做水果检测,有人做杂草识别,有人做病虫害分类,有人做成熟度判断。
很多论文都会展示一个不错的指标:准确率、召回率、平均精度、分割精度。
这些指标有研究价值,但它们不等于产业现场的可用性。
农业场景和工业场景最大的不同,是变量太多。
同样是番茄,上午和下午的光照不同;
同样是草莓,叶片遮挡程度不同;
同样是杂草,不同地块的土壤颜色、作物苗期、相机角度都会变化;
同样是病斑,不同品种、不同生育期、不同拍摄距离下,图像特征也会发生变化。
所以,农业视觉识别真正难的是“换场景以后还能不能识别”。
2025年一篇关于智能水果采摘机器人视觉感知的综述指出,深度学习、三维重建和图像分割正在提高采摘机器人感知能力,但光照变化、植物定位、果实遮挡和复杂背景仍然是视觉系统走向实际应用的重要挑战。
这句话基本上放到所有农业机器人都是成立的。
采摘机器人、除草机器人、喷施机器人、巡检机器人,第一关都不是机械动作,而是视觉系统能不能在真实现场稳定工作。
来自frontiers《A review of visual perception technology for intelligent fruit harvesting robots》;
由福建农林大学、福建师范大学闽南理工学院与三明学院研究团队发布

02
农业视觉识别
不能只迷信模型换代
现在很多项目一遇到识别问题,第一反应是换模型。
从某个检测模型换到另一个检测模型,从旧版本换到新版本,再加注意力模块、轻量化模块、多尺度结构,论文指标可能会提升。
但产业现场常见的问题并不是模型版本落后。
而是数据太窄,场景太单一,测试集和真实现场太像,模型只学会了某一个基地、某一种光照、某一个拍摄角度下的图像特征。
2024年一篇关于农业场景中目标检测模型的系统综述提到,目标检测模型在农业中应用很快,但研究高度分散,模型性能受数据采集、数据处理、网络改造、集成和部署等环节共同影响。
这说明,农业视觉识别不是单纯“换算法”的问题。
如果数据采集没有覆盖真实光照、遮挡、品种、地块和作业状态,模型再先进,也可能只是把训练集记得更牢。
真正要思考的是:
这个模型有没有跨地块测试?
有没有跨季节测试?
有没有在不同相机角度下测试?
有没有在遮挡、阴影、泥水、反光、叶片重叠的情况下测试?
有没有接到真实执行设备上验证?
如果这些问题没有回答,模型精度再高,也很难直接支撑农业机器人落地。
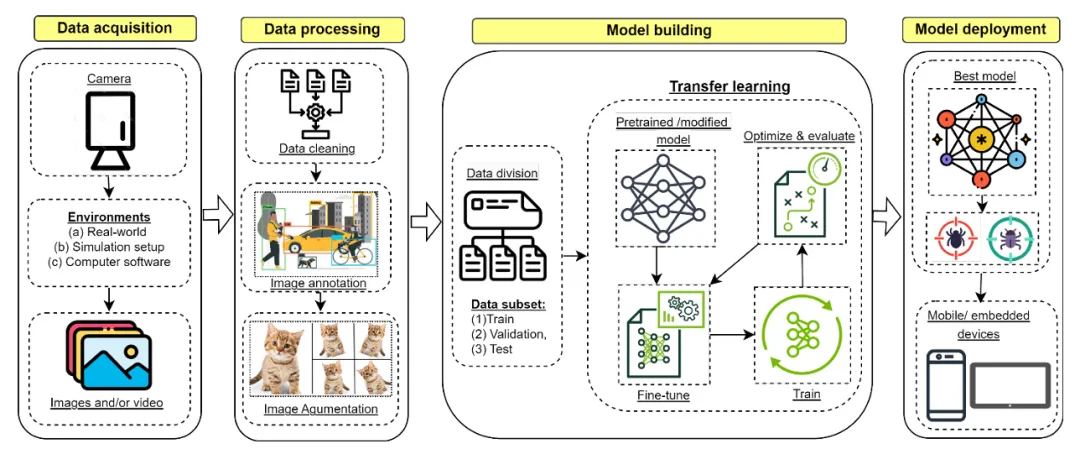
该图清晰展示了YOLO在农业应用中从“数据采集→数据处理→模型开发(含网络修改)→集成与部署”的完整端到端流程;来源康奈尔大学arXiv《Agricultural Object Detection with You Look Only Once (YOLO) Algorithm: A Bibliometric and Systematic Literature Review》
03
最大瓶颈是“域迁移”
农业视觉识别有一个专业问题,叫域迁移。
简单说,就是模型在一个场景训练得很好,换到另一个场景就失效。
比如在一个番茄温室训练出来的成熟度识别模型,到了另一个温室可能下降;在一块棉田训练出来的杂草识别模型,到了另一块地可能误判;在晴天采集的数据上训练出来的模型,到了阴天、逆光、叶片遮挡严重时,效果会变差。
2025年一篇关于农业图像分析中域适应的综述,把农业领域采用域适应的原因总结为:标注数据有限、模型迁移能力弱、农业环境动态变化强。
这才是很多农业视觉项目落地慢的根本原因。
实验室里,数据是整理好的。
现场里,数据是变化的。
模型不是部署一次就结束,而是要随着作物生长、环境变化、设备位置变化和管理方式变化持续调整。
2023年一项关于农业机器人语义分割域适应的研究也指出,视觉系统在新田块、新机器人和新作物上性能衰减,是农业机器人真实应用和商业化采用的主要瓶颈之一。研究尝试用无监督域适应方法,让系统在不增加额外人工标注的情况下适配不同田块、不同机器人和不同作物。
这给产业一个非常直接的启发:
农业视觉识别真正要做的,不只是训练一个模型,而是建立一套能适配新场景的模型迭代机制。
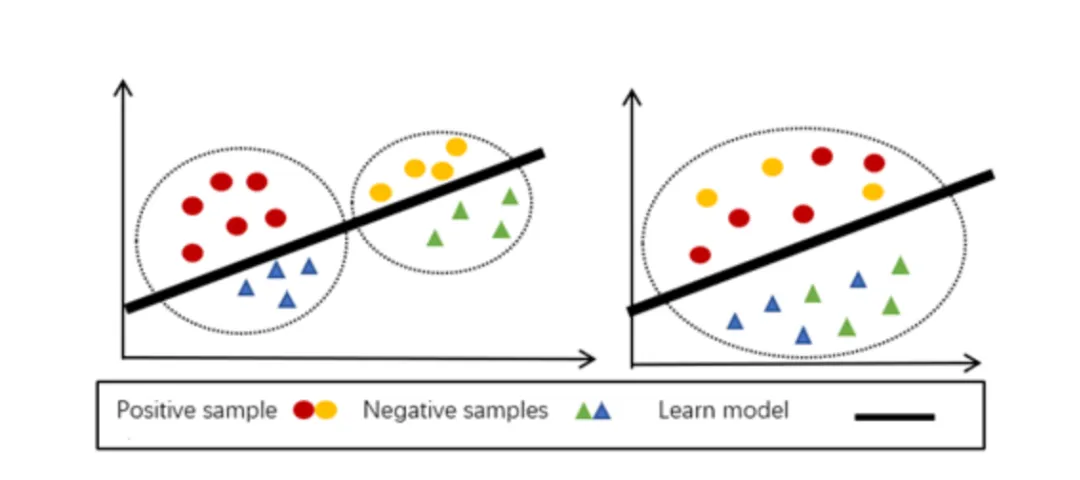
源数据和目标数据的示意图:左侧为原始特征分布,右侧为域适应后的新特征分布。域适应技术有助于缓解源域与目标域之间的“域迁移”问题。来源于康奈尔大学arXiv《Domain Adaptation in Agricultural Image Analysis: A ComprehensiveReview from Shallow Models to Deep Learning》
04
阴影、遮挡和背景
往往比算法本身更致命
农业视觉模型在现场失效,很多时候是因为背景太复杂。
阴影就是一个典型问题。
2025年一项关于甘蔗地入侵杂草检测的研究提到,模型在真实田间容易受到环境条件和标注数据不足影响。研究者通过诊断发现,模型存在“阴影偏差”,会把阴影误识别为植被,因此进一步采用半监督方法,利用未标注数据提升模型鲁棒性。
这个案例很有代表性。
在农业现场,模型并不总是学到了“植物是什么”,它有时学到的是“绿色区域”“阴影边界”“土壤纹理”“拍摄角度”这些表面特征。
所以,农业视觉算法优化不能只看最终指标,还要做错误分析。
误识别发生在哪些光照条件下?
漏检发生在哪些遮挡状态下?
模型是否把阴影、杂物、支架、果箱当成目标?
同一目标在不同距离、不同角度、不同生育期下表现是否稳定?
这些问题比单纯提升零点几个百分点的指标更重要。
因为农业机器人不是用来发表论文的,它是要接刀具、喷头、机械臂、报警系统和生产流程的。
一旦识别错了,后面就可能误除苗、误喷药、漏采果、误报警。
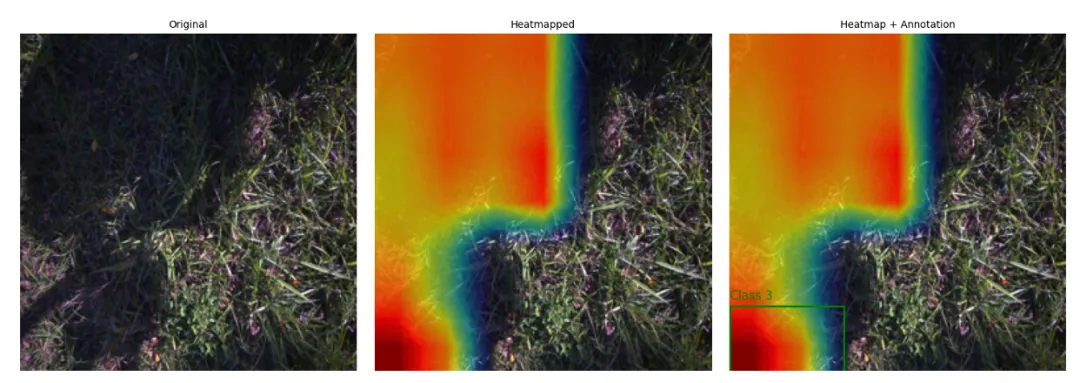
Grad-CAM 可视化揭示了“阴影偏差”。热图显示,模型的注意力(红色区域)偏离了目标杂草叶片,转而聚焦于背景阴影,这一关键失效模式引导我们的研究转向了目标检测。
来源康奈尔大学arXiv《Weed Detection in Challenging Field Conditions:ASemi-Supervised Framework for Overcoming Shadow Bias andData Scarcity》
05
检测之后怎么办
决定视觉识别有没有产业价值
农业视觉识别最容易被错误认知的地方,是把“识别出来”当成终点。
但对农业机器人来说,识别只是起点。
采摘机器人识别出番茄,还要判断成熟度、果柄位置、可采路径、是否遮挡、先采哪个、怎么避开旁边果实。
除草机器人识别出杂草,还要判断作物苗位置、除草边界、刀具是否能下去、喷头是否打开、是否需要二次复查。
巡检机器人识别出病斑,还要判断风险程度、是否报警、是否派工、是否需要记录位置并复查。
所以,农业视觉系统必须进入执行闭环。
要知道,视觉识别不能孤立交付。
客户真正需要的不是一套“能识别图片”的模型,而是一套能接入现场作业的感知系统。
它要能输出机器人或自动化设备真正需要的信息:
目标在哪里;
置信度是多少;
能不能执行;
从哪里执行;
执行完如何记录;
失败后如何复查。
只有走到这一步,视觉识别才从算法能力变成生产能力。
06
真实场景数据集
才是农业视觉的第一资产
农业视觉识别要想真正落地,第一步不是选模型,而是建设数据集。
而且不是随便拍一批图。
真实场景数据集至少要覆盖几个维度:不同地块、不同棚室、不同品种、不同生育期、不同天气、不同光照、不同遮挡状态、不同设备角度、不同作业时间。
如果要做番茄成熟度识别,数据不能只来自一个温室、一个品种、一个采收期。
如果要做杂草识别,数据不能只来自一个地块、一个苗期、一个土壤背景。
如果要做病虫害识别,数据不能只来自标准病叶照片,还要包括早期病斑、混合症状、缺素、药害、机械损伤等容易混淆的情况。
数据集建设不是辅助工作,而是农业视觉系统的底座。
很多农业机器人项目走不下去,是没有持续采集、持续标注、持续验证、持续迭代的数据机制。
这也是为什么,农业视觉识别服务不能只做一次训练。
它应该包括数据采集方案、标注规范、模型训练、场景测试、错误分析、二次迭代和部署验证。
07
算法优化
要从“实验指标”转向“现场指标”
农业视觉算法如果要服务产业,就必须改变评价方式。
不能只看测试集准确率。
更应该看现场指标。
比如:
换棚以后识别下降多少;
逆光和阴影下还能不能用;
遮挡严重时漏检率多少;
误识别会不会导致误动作;
模型在边缘设备上能不能实时运行;
识别结果能不能稳定传给控制系统;
设备连续运行一天后,数据是否仍然可靠。
这些指标才决定农业机器人能不能落地。
对于除草机器人来说,漏检意味着杂草逃逸,误检意味着伤苗;
对于采摘机器人来说,误判成熟度意味着采早或漏采,定位不准意味着损伤或失败;
对于分级设备来说,识别不稳定意味着产品规格不一致,影响商超渠道和高端渠道交付。
所以,农业视觉识别的核心不是“模型有没有高分”,而是“模型能不能支撑现场决策”。
08
真正的解决方案
是数据、算法和现场验证一起做
农业机器人视觉识别的瓶颈,不可能靠一个算法包解决。
真正可交付的方案,应该是一个完整流程。
先做场景诊断,判断客户到底要识别什么、识别结果用于什么动作、现场变量有哪些、失败后影响是什么。
再做数据采集,覆盖真实场景里的作物、光照、遮挡、角度、设备位置和异常样本。
然后做数据标注和模型训练,不只是追求高指标,而是针对真实作业目标设计标签体系。
接着做模型泛化测试,把模型拿到不同地块、不同棚室、不同时间段验证,看它是否稳定。
最后才是部署和联调,把识别结果接入机器人、喷头、刀具、机械臂、分级设备或巡检系统。
也就是说,农业视觉识别的服务,不应该叫“训练一个模型”。
它更像是:
为具体农业场景建设一套可迭代的视觉感知系统。
其实,农业机器人视觉识别的真正难点,不在实验室,而在田间。
模型能在训练集上识别,不代表它能在不同基地、不同光照、不同品种、不同生育期里稳定工作。
这也是为什么,农业机器人要从样机走向应用,必须把视觉识别从“算法精度”推进到“场景泛化能力”。
真正有价值的工作,不是简单把模型换成更新版本,而是把真实场景数据集、算法优化、泛化测试和现场验证串起来。
对于农业机器人公司、智慧农业企业、分选设备企业和高标准温室运营方来说,视觉识别不再是一个后台算法问题,而是决定设备能不能干活、能不能交付、能不能持续使用的核心能力。
未来农业视觉系统的竞争,也不会只发生在论文指标上。
它会发生在真实现场里:换一个棚,换一块地,换一个季节,模型还能不能稳定识别。
这才是农业机器人视觉识别真正要跨过的门槛。
#智慧农业#农业机器人#采摘机器人#清华农业#农业机器人开发#农业机器人定制研发#农业机器人研发找陈灏#清华装备院陈灏#农业自动化#农业无人机
清研智慧农业
清研智慧农业源于清华大学天津高端装备研究院智能系统与大数据研究中心,依托清华大学顶尖科研力量与天津产业创新平台,深度融合“软件、智能装备与大数据”三大核心技术,致力于为智慧农业、工业自动化及高端制造领域提供领先的智能化解决方案。
我们不仅开展前沿技术研究,更注重成果转化与产业赋能,已成功研制出农业采收机器人、智能除草系统、农业无人机、高端自动化产线等一系列具有自主知识产权的装备与系统,推动产业向智能化、绿色化、高效化升级,助力中国从“制造大国”迈向“制造强国”。



特别说明

本文部分内容(包括但不限于文字、图片、数据等)来源于互联网公开信息,旨在传递更多资讯,仅供学习交流之用。其版权均归原作者或原始出处所有。
为支持原创,本公众号会尽量标注来源。如您发现本公众号中有内容侵犯了您的合法权益,请立即通过后台留言或添加客服微信等方式与我们联系,我们将在核实后第一时间进行处理。
未经本公众号明确授权,任何个人或组织不得将本文内容用于商业性转载或摘编。转载请联系后台开白;凡从本公众号转载本文至其他平台所引发的一切纠纷、后果及法律责任,均由转载方自行承担,本平台概不负责。
*往期精选*
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 加快农业农村现代化,“十五五”怎么干(政策解读)
- 【新疆】农业普查大数据与AI融合的数字农业与粮食安全智慧
- 县区科协丨子长市农业科普提升行动暨马铃薯科普亲子实践活动圆满举行
- 2026乡村振兴新型农业经营主体与新型农业社会化服务培训暨供销行业职业经理人合作经济管理师技术员农作物植保员评价考评7月25-28
- “十五五”农业农村现代化蓝图绘就:五大看点深度解析畜牧业未来
- 【权威发布】加快农业农村现代化“十五五”规划,全文来了!
- 当大模型遇上世界500强养鸡巨头:农业正在诞生一个新物种
- 2026年山东农业大学诚聘海内外人才简章(92人)
- 【淄博招聘】山东农业大学招聘92名工作人员公告
- 2026干农业必看!数字化+保姆式服务到底咋赚钱?
