南京农业大学国家特聘专家团队在《Nature》子刊发表研究论文
- 2026-06-26 14:52:39
点击关注上方“AI地球探针”,选择加"星标"置顶
重磅干货,第一时间送达


近日,南京农业大学赵方杰团队联合中科院分子植物科学卓越创新中心万里团队,在《Nature Plants》期刊上发表了题为“Transition metal-enhanced immunity in Arabidopsis roots via an NLR pair”的研究成果。该研究不仅揭示了一对在根系中特异性表达的NLR抗病基因如何协同调控植物对过渡金属的耐性与对土传青枯病菌的抗性之间的微妙平衡,更从分子层面阐明了过渡金属通过激活NLR胞内受体蛋白活性来增强根系免疫力的全新机制。
植物生存依赖于铁、锰、铜、锌、镍等多种过渡金属元素的吸收,同时也需应对镉、铅等有害金属离子的威胁。研究团队利用正向遗传学策略,筛选到一种对过渡金属高度敏感的拟南芥突变体stm1。经过图位克隆、基因组重测序及功能回补验证,确定其因果基因为STM1,该基因编码一种含有TIR结构域的NLR胞内受体蛋白。实验发现,在过量过渡金属存在的环境下,stm1突变体的根系中效应因子触发的免疫反应(ETI)被显著激活。这种过度激活虽然大幅提升了植株对青枯病菌的防御能力,却导致了对过渡金属敏感、根系生长严重受抑的负面表型。
深入探究表明,真正直接触发免疫反应的并非STM1本身,而是与STM1以“头对头”方式成对排列的另一个NLR基因STM2。遗传学证据显示,若在stm1突变背景下进一步敲除STM2基因,植株不仅能完全恢复对过渡金属的耐受性,其对青枯病菌的抗性也会随之减弱。此外,敲除ETI通路核心基因EDS1、PAD4或ADR1s同样能消除过渡金属敏感性。值得注意的是,STM1和STM2主要在根系表达,且其编码蛋白精准定位于根系的内皮层细胞。作为调控矿质元素吸收转运及阻挡土传病菌入侵的关键屏障,内皮层的这一特性凸显了该基因对在根系免疫中的核心地位。
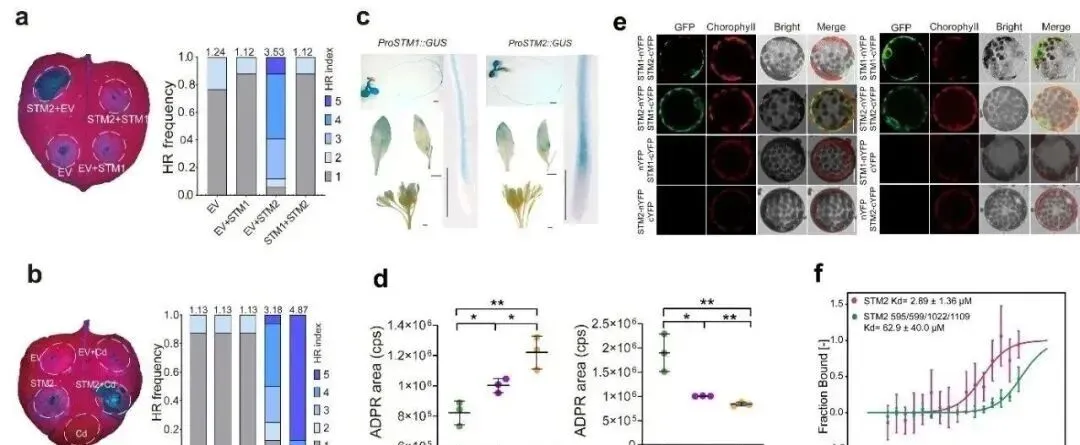
关于过渡金属激发STM2免疫功能的具体机制,研究团队结合烟草叶片超敏反应(HR)实验与重组蛋白体外酶活分析发现,STM2具备NAD+水解酶活性,这是触发下游免疫级联反应的关键开关。当STM2在烟草叶片中单独表达时,会诱发超敏反应;而加入镉、锌或铜等过渡金属后,STM2的NAD+水解酶活性及超敏反应强度均显著增强。相反,若同时表达STM1,则会有效抑制STM2的酶活性及其引发的超敏反应。微量热泳动实验进一步证实,镉、锌和铜离子能够直接结合STM2蛋白,其中位于LRR结构域的三个半胱氨酸和一个组氨酸残基是关键的金属结合位点;对这些位点进行点突变后,过渡金属对STM2超敏反应的促进作用大幅降低。蛋白互作实验则揭示,STM1能与STM2发生物理互作,并阻碍STM2形成同源寡聚物,从而从结构上解释了STM1对STM2免疫功能的抑制机理。
综上所述,这项研究揭示了植物基因组中一类特殊的“头对头”NLR基因对的新型作用模式:STM2作为免疫效应的执行者,通过直接结合过渡金属来增强其NAD+水解酶活性及免疫功能;而STM1则扮演“刹车”角色,通过抑制STM2的活性,防止植物因过度免疫而对过渡金属产生敏感性并导致生长受阻。STM1/STM2基因对因此成为调节植物应对非生物胁迫与生物胁迫之间权衡的关键枢纽。这也是学界首次发现的参与植物根系免疫的成对NLR抗病基因,填补了以往研究多聚焦于地上部抗病基因的空白。
展望未来,挖掘STM1/STM2的自然变异资源,结合土壤中普遍存在的过渡金属胁迫与土传病原菌流行压力,解析这两者在双重选择压力下的适应性进化特征,将为复杂生态环境下的可持续农业发展提供宝贵的基因资源。
该论文由南京农业大学赵方杰教授与中科院分子植物科学卓越创新中心万里研究员共同通讯,南京农业大学高铖青年研究员与中科院陈思思博士研究生为共同第一作者。
近日,南京农业大学赵方杰团队联合中科院分子植物科学卓越创新中心万里团队,在《Nature Plants》期刊上发表了题为“Transition metal-enhanced immunity in Arabidopsis roots via an NLR pair”的研究成果。该研究不仅揭示了一对在根系中特异性表达的NLR抗病基因如何协同调控植物对过渡金属的耐性与对土传青枯病菌的抗性之间的微妙平衡,更从分子层面阐明了过渡金属通过激活NLR胞内受体蛋白活性来增强根系免疫力的全新机制。
植物生存依赖于铁、锰、铜、锌、镍等多种过渡金属元素的吸收,同时也需应对镉、铅等有害金属离子的威胁。研究团队利用正向遗传学策略,筛选到一种对过渡金属高度敏感的拟南芥突变体stm1。经过图位克隆、基因组重测序及功能回补验证,确定其因果基因为STM1,该基因编码一种含有TIR结构域的NLR胞内受体蛋白。实验发现,在过量过渡金属存在的环境下,stm1突变体的根系中效应因子触发的免疫反应(ETI)被显著激活。这种过度激活虽然大幅提升了植株对青枯病菌的防御能力,却导致了对过渡金属敏感、根系生长严重受抑的负面表型。
深入探究表明,真正直接触发免疫反应的并非STM1本身,而是与STM1以“头对头”方式成对排列的另一个NLR基因STM2。遗传学证据显示,若在stm1突变背景下进一步敲除STM2基因,植株不仅能完全恢复对过渡金属的耐受性,其对青枯病菌的抗性也会随之减弱。此外,敲除ETI通路核心基因EDS1、PAD4或ADR1s同样能消除过渡金属敏感性。值得注意的是,STM1和STM2主要在根系表达,且其编码蛋白精准定位于根系的内皮层细胞。作为调控矿质元素吸收转运及阻挡土传病菌入侵的关键屏障,内皮层的这一特性凸显了该基因对在根系免疫中的核心地位。
关于过渡金属激发STM2免疫功能的具体机制,研究团队结合烟草叶片超敏反应(HR)实验与重组蛋白体外酶活分析发现,STM2具备NAD+水解酶活性,这是触发下游免疫级联反应的关键开关。当STM2在烟草叶片中单独表达时,会诱发超敏反应;而加入镉、锌或铜等过渡金属后,STM2的NAD+水解酶活性及超敏反应强度均显著增强。相反,若同时表达STM1,则会有效抑制STM2的酶活性及其引发的超敏反应。微量热泳动实验进一步证实,镉、锌和铜离子能够直接结合STM2蛋白,其中位于LRR结构域的三个半胱氨酸和一个组氨酸残基是关键的金属结合位点;对这些位点进行点突变后,过渡金属对STM2超敏反应的促进作用大幅降低。蛋白互作实验则揭示,STM1能与STM2发生物理互作,并阻碍STM2形成同源寡聚物,从而从结构上解释了STM1对STM2免疫功能的抑制机理。
综上所述,这项研究揭示了植物基因组中一类特殊的“头对头”NLR基因对的新型作用模式:STM2作为免疫效应的执行者,通过直接结合过渡金属来增强其NAD+水解酶活性及免疫功能;而STM1则扮演“刹车”角色,通过抑制STM2的活性,防止植物因过度免疫而对过渡金属产生敏感性并导致生长受阻。STM1/STM2基因对因此成为调节植物应对非生物胁迫与生物胁迫之间权衡的关键枢纽。这也是学界首次发现的参与植物根系免疫的成对NLR抗病基因,填补了以往研究多聚焦于地上部抗病基因的空白。
展望未来,挖掘STM1/STM2的自然变异资源,结合土壤中普遍存在的过渡金属胁迫与土传病原菌流行压力,解析这两者在双重选择压力下的适应性进化特征,将为复杂生态环境下的可持续农业发展提供宝贵的基因资源。
该论文由南京农业大学赵方杰教授与中科院分子植物科学卓越创新中心万里研究员共同通讯,南京农业大学高铖青年研究员与中科院陈思思博士研究生为共同第一作者。
🌟 课程一:基于claude code、codex双AI协同论文写作撰写与质量校准:从"数据分析→论文初稿→交叉审稿"全流程
🌟课程二:2026基于前沿AI-Agent2.0驱动的科研全链路实战营:一站式掌握LLM与Notebooklm应用、数据分析、自动化编程、文献管理到论文写作的核心技能、手把手搭建本地LLM与Agent,体验多模型“圆桌会议”的头脑风暴、基于N8N与OpenClaw、Claude Code构建从文献挖掘到成果产出的自主智能体、解锁Seedance2,轻松将论文转化为高质量的科研科普视频献及知识管理、科研写作与绘图、构建个人AI助手与科研工自动化作流培训班
🌟课程三:最新AI-Python机器学习、深度学习核心技术与前沿应用及OpenClaw、Hermes自动化编程
🌟课程四:关于举办“OpenClaw、Hermes+Vibe Coding核心实战玩法,手把手教你本地部署与云端协同,实现知识、论文自动化工作流”培训班

📢 课程核心差异化
1.双模型交叉审稿:Claude Code写代码和论文,Codex作为独立审稿人打分、挑错、提改进意见——两个不同AI系统互相review迭代,比单一AI自查深入一个层次。
2.真实全流程:数据获取→清洗分析→统计检验→论文撰写→多轮审稿→投稿准备,两天走完核心环节。
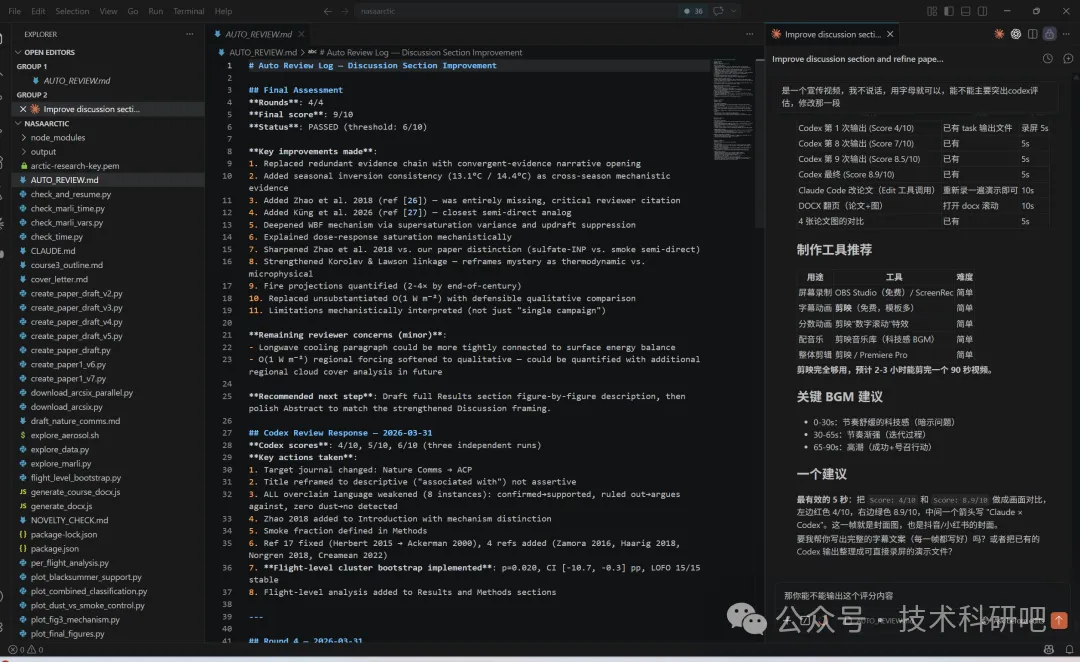
3.真实案例:讲师以自己论文为例,展示Codex审稿从4/10逐步改进到8/10的完整轨迹(12轮迭代,课堂展示精华3轮)。
4.Claim校准:让两个AI分别评估论文核心结论的可信度,教学员用AI做批判性思考而非盲目接受。
5.学科通用:核心方法适用于任何"数据→分析→论文"的定量研究场景。
📢 课程完整产出
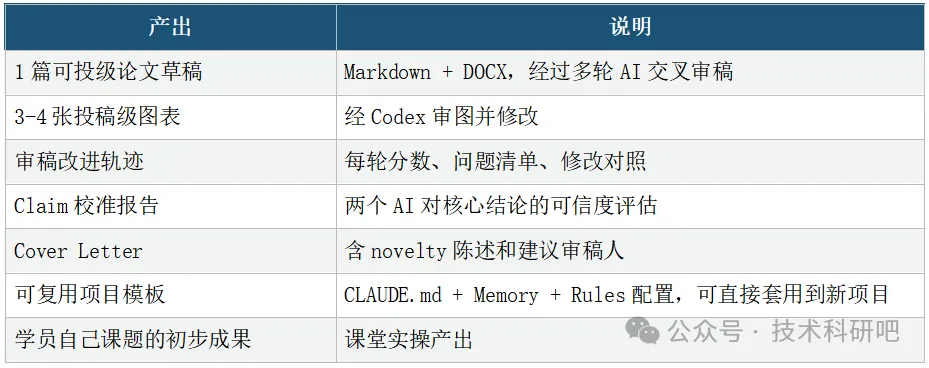
培训时间:5月16日-17日
学习方式:线上直播+助学群长期辅助指导+永久回放特权课程内容
📋 课程内容简要
第一天:Claude Code科研深度使用——从数据到论文初稿
产出:完整Claude Code项目环境-- 数据已下载、清洗、分析
1、Claude Code安装验证与模型选型(Opus/Sonnet/Haiku的成本与能力权衡)
产出:可用的Claude Code环境
2、CLAUDE.md:用一个配置文件教AI理解你的项目背景和规范
产出:项目专属CLAUDE.md
3、Memory系统:跨对话保持研究上下文(方向、数据、发现)
产出:Memory配置
4、实操:为自己的科研课题创建Claude Code项目结构
产出:完整项目骨架
案例实践:对比有/无CLAUDE.md时的回答质量——从"通用聊天"变成"懂你课题的助手"
模块二、数据获取与自动化分析
1、用Claude Code生成数据下载脚本(API/FTP/Web多种方式)
产出:下载脚本
2、数据清洗:缺失值、异常值、格式转换(NetCDF/HDF5/CSV/Excel)
产出:清洗脚本
3、自然语言→分析脚本:描述研究假设,Claude Code自动设计分析方案
产出:200+行Python脚本
4、统计检验:Bootstrap CI、Cohen's d效应量、多重比较校正
产出:统计结果JSON
案例实践:一句话需求→自动生成完整脚本→跑通→输出结果
模块三、科研绘图
1、投稿级图表标准(字体、DPI、配色、error bars)
产出:matplotlib模板
2、常见图表类型实操:scatter、heatmap、bar+CI、时间序列
产出:3-4张图
3、多panel组合图:gridspec布局与统一配色
产出:组合figure
模块四、论文初稿自动生成
1、论文结构设计:Title → Abstract → Intro → Results → Discussion → Methods
产出:论文大纲
2、Results:Claude Code读取JSON结果,生成带精确数字的段落
产出:Results初稿
3、Discussion:机制解释、文献对比、局限性
产出:Discussion初稿
4、Introduction:背景、知识空白、本文贡献
产出:完整初稿v1
关键技巧:如何让AI引用真实数字而非编造;如何用Memory防止长文写作中上下文丢失
模块五、AI伦理与期刊政策
1、主流期刊的AI使用政策(Nature/Science/Elsevier/ACS/AGU最新规定)
2、AI辅助写作的披露规范:哪些必须声明、怎么声明
3、数据隐私与保密:什么数据不能上传到云端API
4、可复现性:Prompt日志、环境版本
第二天:Codex交叉审稿 + 迭代改进 + 投稿准备
产出:论文经过3轮交叉审稿,含完整改进记录-投稿级图表-论文DOCX + Cover Lette-学员自己课题的初步成果
模块六、Codex首次审稿
1、Codex CLI配置与使用方式(consult模式发送审稿请求)
产出:可用的Codex环境
2、把论文初稿发给Codex:要求打分、列弱点、找overclaim
产出:首次审稿报告(预计4-6/10)
3、解读审稿意见:overclaim、missing citations、statistical gaps
产出:问题清单
关键时刻:学员亲眼看到论文被打低分——"AI审稿比真人审稿更直接"
模块七、双AI迭代改进
1、Round1:修复措辞(confirms→supports, rules out→argues against)
Codex审查:重新打分
预期变化:+1-2分
2、Round2:补引用、加统计检验、完善limitations
Codex审查:再次审稿
预期变化:+1分
3、Round3:针对性修复剩余弱点
Codex审查:终审
预期变化:达到可投级
核心重点:
-科研措辞分寸:从"proves"到"is consistent with"
- 引文补充:用Claude Code的WebSearch查找缺失引用
- 每轮改进的对照记录
备注:课程案例经过12轮才从4/10到8/10。课堂3轮是精华流程展示,学员课后可继续迭代。
模块八、Claim校准——让两个AI交叉质询
1、Claude和Codex分别评估核心结论的可信度,对比分歧
产出:双方评分对比
2、根据交叉质询结果调整论文claim强度
产出:校准后的措辞
模块九、审图 + 投稿文件生成
1、Codex审图:标签、单位、配色、可读性
产出:审图报告
2、修图:去夸张标题、加error bars、colorblind-safe配色
产出:终版图表
3、Claude Code生成DOCX(嵌入图表)
产出:论文DOCX
4、引用格式化(Nature-style/APA/国标,按目标期刊选择)
产出:引用列表
5、Cover Letter自动生成
产出:cover_letter.md
模块十、学员实操 + 进阶路径
1、学员用自己的数据/课题跑一遍核心流程(分析→初稿→Codex审稿)
时间:45min
2、共性问题集中讲解 + 讲师答疑
时间:30min
3、进阶路径概览:远程计算(AWS/阿里云)、自定义SKILL、MCP扩展、引文管理器对接
时间:15min
注:请提前自备电脑及安装所需软件。
📞 报名咨询
微信二维码:

课程二

📢 科研真正的挑战从来不是“有没有答案”,而是:如何高效整合信息、持续产生高质量IDEA,并把研究想法快速转化为可发表成果。而这,正是大多数通用AI使用方式所无法解决的。
本课程是一门面向科研人员、研究生、博士生、高校教师以及高端知识工作者的系统化实战训练营,以“工具即生产力,Agent即科研合作者”为核心理念,带你从“使用AI”进阶到“构建AI系统”。课程将系统讲解如何将主流大语言模型深度融合进:
1.科研写作与论文生产流程
2.实验与科研数据分析
3.文献管理与知识体系构建
4.科研绘图与学术级可视化表达
5.多模型协作的创新型科研思考
6.基于NotebookLM 的研究资料整合、来源引用与可信推理
7.Google生态系统自动化科研工作流与AI Agent系统
通过真实科研场景与完整案例,你将学会如何让AI主动协助你思考、决策与创作,而不仅仅是被动回答问题。
通过本课程,你将不只是学会“使用AI”,而是能够真正做到:
1.构建属于自己的科研AI Agent,让AI成为你的长期研究助手
2.打造可持续复利的个人科研系统,知识与成果持续积累
3.显著提升科研效率与创新能力,减少重复劳动,专注高价值思考
4.让AI成为你稳定、可靠、可进化的科研合作者
这不是一门“教你玩AI的课程”,而是一门帮助你在AI时代建立长期科研竞争力的系统训练营。最后将总结Google Gemini(Nano Banana),AI Studio,Notebooklm等谷歌一系列生态系统,如何使用这些打造专属个人自动科研系统。
当前AI发展日新月异,大模型迭代速度显著加快,或许有一天人类终将被AI淘汰,但希望你我不是最先被AI淘汰的个人。
通过大语言模型生成数据统计图



Ollama部署LLAMA/DeepSeek
本地模型性能优化
RAG构建个人知识库
微调vs RAG的选择策略
Open WenUI本地部署,
如何结合Zotero和Open WenUI搭建本地知识系统
在本地环境里构建类似NotebookLM的科研生态系统(不需要科学上网,就能运行)
案例7:
本地部署DeepSeek→构建:
专属科研问答系统
私有文献分析Agent
结课成果:
一个私有科研AI Agent
多LLM分工机制
批判型/创新型Agent设计
自动迭代研究方案
模型的能力越强,Idea的创意更好
案例8:
ChatGPT+Claude→自动进行多轮讨论,生成创新研究方向。
结课成果:
一份「可投稿级研究IDEA说明书」
N8N基础与部署
多软件自动联动
多模型优势整合
全流程科研自动化设计
整合Google工作系统流
实战案例
案例9:
构建一个完整系统:
通过DeepSeek创建全自动科研文献搜索总结系统
最终交付:
一套可长期使用的科研文献搜索总结自动化系统
第十一章、Seedance 2.0视频生产大模型基础与科研科普自动化
课程三

📢 【全栈技能,层层递进】
从Python高阶编程(函数式、OOP、性能优化)出发,掌握XGBoost、LightGBM等经典机器学习工具,深入CNN、Transformer、扩散模型等前沿架构;同时以科学问题为牵引,强化SHAP可解释性分析、因果推断与不确定性量化,确保AI模型的物理一致性与科学严谨性。
【革命性效率工具:氛围编程与上下文工程】
告别繁琐的重复编码。课程深度教授Vibe Coding(氛围编程)——通过自然语言与AI协同编程,实现"零门槛"快速原型开发;掌握上下文工程与RAG技术,让大模型精准理解您的领域数据,自动生成可执行的分析代码、SQL查询与科研图表,将数据分析效率提升十倍。
【科研自动化:从Chat到Agent的跃迁】
学习构建OpenClaw智能体工作流,让AI自主完成数据清洗、多维度归因分析、假设检验与报告生成。通过MCP架构连接您的本地数据库与计算环境,实现"一句话需求→自动化分析→交付洞察"的端到端科研流水线,彻底解放您的生产力。
【差异化优势】
实战导向:9大案例模块覆盖图像光谱分析、时空序列预测、科学归因、论文Idea探索等真实场景
人机协同:不仅教算法原理,更教"如何指挥AI做科研"——从提示词设计、代码审查到多Agent协作
前沿融合:传统统计思想 × 现代深度学习 × 大模型自动化三重视角,打通从算法理解到科研落地的最后一公里
本课程将为您提供兼具学术严谨性、工程实用性、技术前瞻性的学习平台。让AI成为您科研团队中最得力的智能助手,加速从数据洞察到科学发现的全过程。
专题十:自进化的Agent
Hermes Agent从私有化部署到智能体自我进化:本地化深度研究助手的构建
1.从静态配置到动态进化:AI Agent能力获取范式的跃迁
2.Hermes Agent运行时架构解析
3.私有化部署实践:本地模型(Qwen3.5 27B)接入与vLLM优化配置
4.技能蒸馏与自动化编程:从任务执行到Python Skills的生成与优化
5.多后端执行环境配置:Docker、SSH、Singularity的场景化选择
6.子Agent并行策略:任务拆解、隔离执行与结果聚合机制
7.与OpenClaw的协同与迁移:记忆导入、配置互通与分层架构设计
8.知识沉淀的自动化策略:Skills版本控制、冲突解决与长期进化路径
9.本地化科研助手的典型应用场景
案例分析与实践(十)课程四

🎁 学员课前准备
为确保每位学员都能顺利上手实操,课程开始前一周将讲解详细的环境配置教程,并提供一份配置说明文档,助你轻松搞定复杂环境搭建!
1.安装好Python、Git、VS Code
2.准备至少1-2个可调用API的模型账号
3.准备安装或已安装OpenClaw、Hermes、Cursor、Claude Code、Codex
4.自带一个科研题目、一份数据样例或2-3篇代表性论文,便于课堂演练
5.若计划实操本地部署,建议电脑具备较大内存或可连接GPU服务器
🎯课程结束后建议交付成果
1.一个已完成基础配置的OpenClaw科研环境
2.一份《科研任务-模型-Token选型卡》
3.一份《本地大模型部署与接入说明卡》
4.一份《科研Agent编程工具对比表》
5.两个科研Skill初稿
6.一份《科研MCP接入蓝图》
7.一份《科研云端数据管理与下载流程模板》
8.一套个人多模型论文写作自动化流程图
9.一份《个人OpenClaw科研助手搭建方案》
10.一份《NotebookLM、Claude Code、Obsidian的知识工作流》
⚡ 培训目标
1. 独立完成 OpenClaw、Hermes的安装、配置、模型接入与基础使用。相对于Openclaw,Hermes具有自我成长的功能。
2. 理解 Token、上下文窗口、调用成本与模型能力边界
3. 学会比较并选择不同大模型,尤其是 DeepSeek 、Qwen、Chatgpt、Opus、Gemma4、Kimi、GLM、Minimax
4. 掌握开源大模型本地部署的基本路径,如Ollama的适用场景,Ollama本地部署Gemma4和Qwen3.5后运行Claude,保存本地数据隐私性。Openclaw、Codex、Claude Code运行本地大模型
5. 学会建立科研数据的云端存储、快速下载与版本化管理流程
6. 掌握Vibe Coding在科研编程中的正确工作方法
7. 学会用Agent完成科研数据可视化与结果解释
8. 学会使用Cursor、VS Code、Codex、Claude Code 完成科研代码任务
9. 学会编写科研SKILL,理解MCP的扩展价值
10. 设计一套属于自己的多模型论文写作自动化工作流
11.掌握一套从NotebookLM、Claude Code、Obsidian知识管理自动化工作流(无论是老师还是学生都可以复现MIT研究生48小时掌握一门课)
12.通过Hermes Agent生成Karpathy的LLM-Wiki的Obsidian知识库
📢重点专题说明
1.如何讲清楚Token选择:
1)Token是模型处理文本的基本计量单位,不等于简单字数
2)选模型不仅看“聪不聪明”,还要看上下文、速度、成本和稳定性
3)真正高效的科研工作流通常是多模型分工,而不是只用一个最贵模型
4)要教会学员把高质量模型用在关键步骤,把高性价比模型用在重复步骤
2.中国两个大模型与美国三个大模型对比:
1)DeepSeek适合推理链、代码、数学与结构化任务
2)Qwen适合中文理解、通用办公、生态兼容和平台接入
3)Gemini的Nano Banana适合绘图
4)Opus搭配Claude Code适合写代码和论文
5)Chatgpt5.4搭配Codex适合执行任务
6)教学中应强调“任务分工”而不是简单比较谁更强
3.如何“养龙虾进行科研”:
1)长期培养一个懂你课题和工作习惯的科研助手
2)用规则、Skill、MCP、知识材料和模板持续迭代Agent
3)把每次科研实践沉淀成可复用的流程资产
4.本地部署与云端协同:
1)敏感数据、私有材料和高频重复任务优先考虑本地模型
2)高质量推理、长文写作和复杂审阅可调用云端强模型
3)最实用的方案往往不是全本地或全云端,而是“本地保密+云端增强”的混合策略
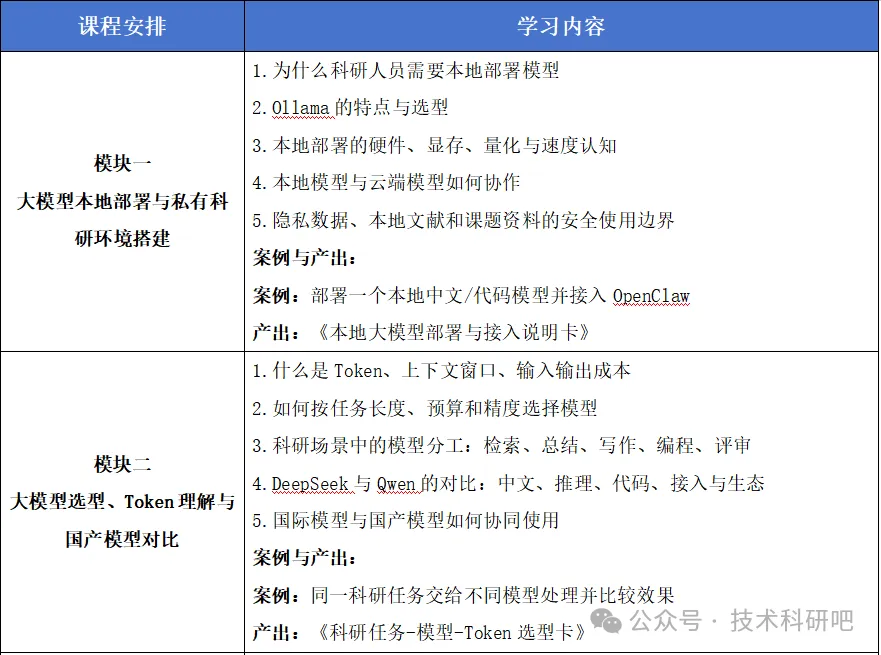
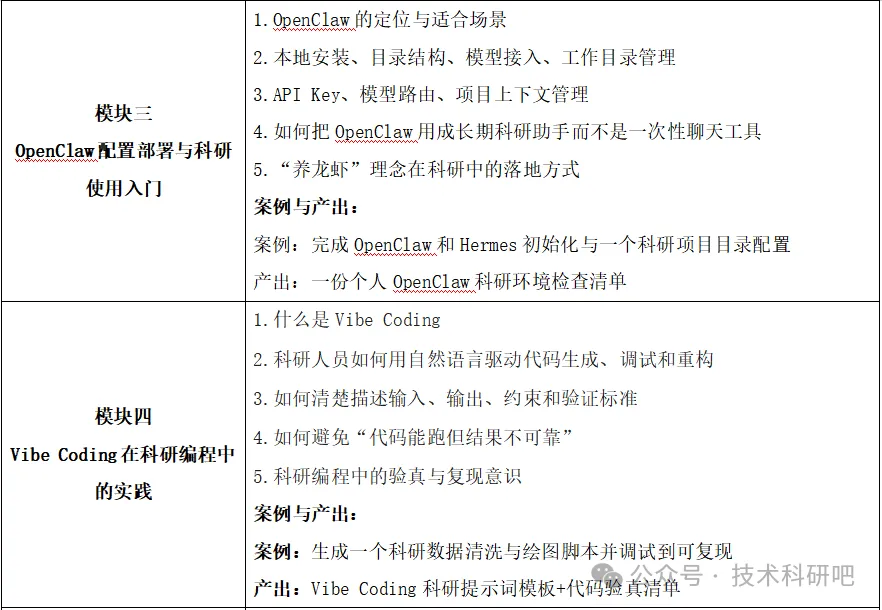
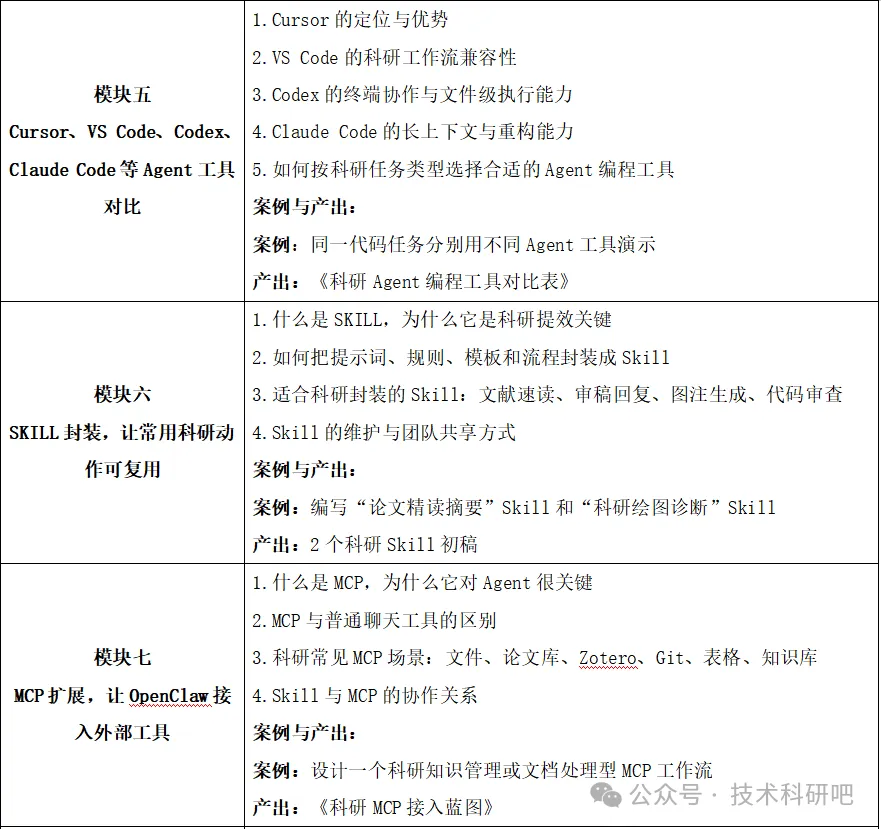
📋 课程内容简要
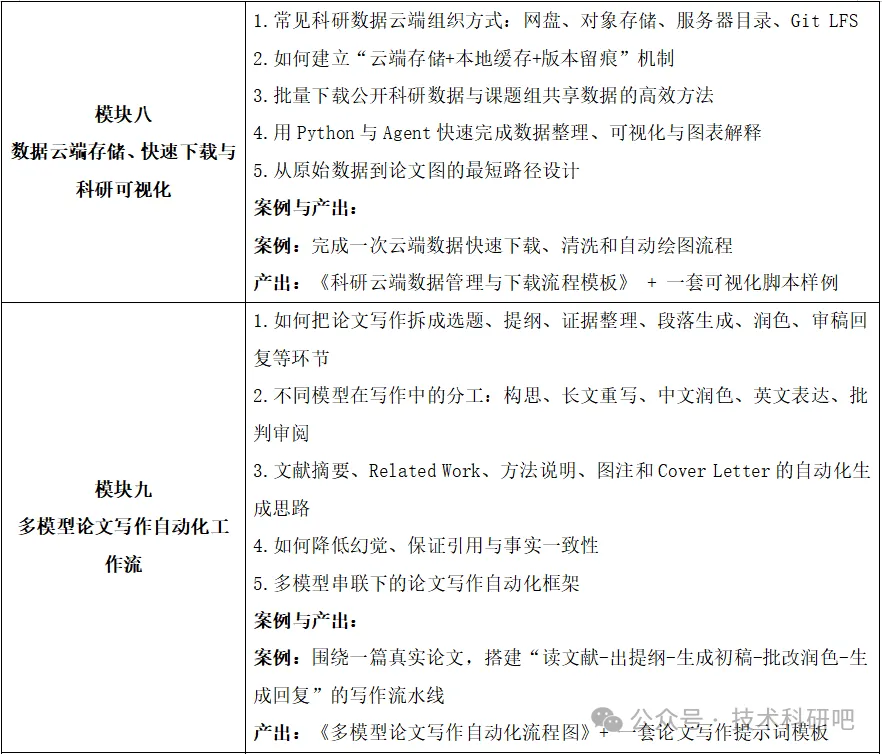

课程五

📢 课程核心差异化
1.真实数据驱动:使用Cochrane/JAMA已发表RCT的真实数据,非模拟数据,可溯源至原始文献。
2.一条主线贯穿:从PICOS设计→PubMed检索→AI筛选→效应量计算→DL随机效应模型→森林图→漏斗图→亚组分析→敏感性分析→Results段落,两天做完完整Meta-Analysis。
3.AI深度提效:用Hermes Agent自动生成检索式、批量筛选文献、运行统计脚本、生成投稿级图表、撰写Results段落——亲眼见证AI把传统2周的工作压缩到2小时。
4.代码经双轮审阅:所有脚本经两轮代码审阅(Codex Review),Egger检验修正为加权回归(WLS)、SMD方差统一为含J²的Hedges标准公式、PRISMA计数改为动态计算,统计公式逐项验证。
5.带走你的专属科研智能体:你将带走一个配置好的Hermes Agent和Meta-Analysis统计Skill,利用其自进化能力,未来可一键复用到你的任何课题中。
📢 课程完整产出
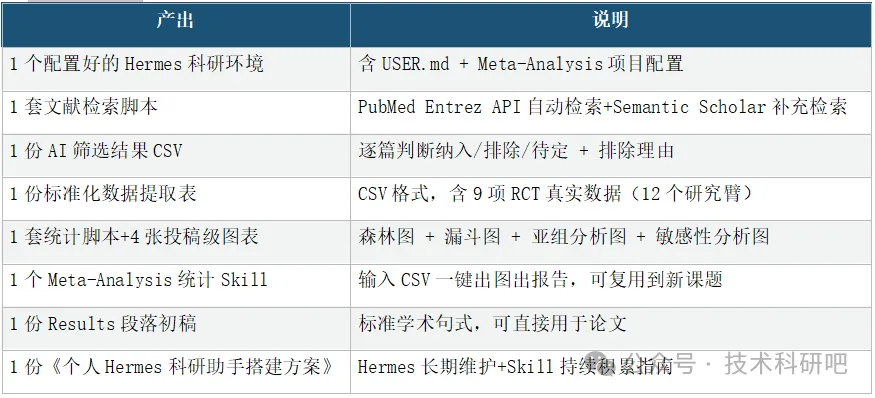
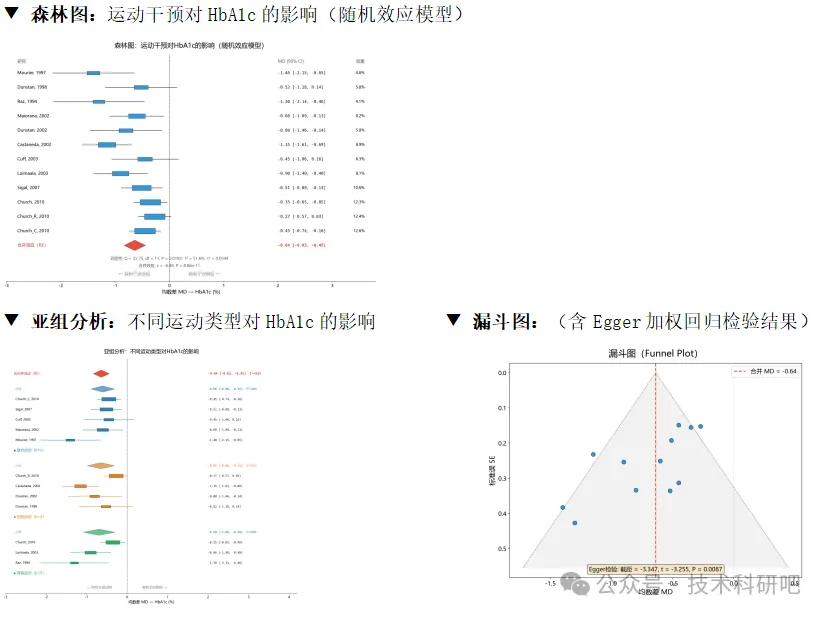
📢 【课程产出图表示例】(以下均为课程真实数据生成)
📅 培训时间
直播时间:5月30日-31日(腾讯会议直播)
🎯 培训方式
在线直播+助学群辅助+导师面对面实践工作交流
📋 课程内容简要
第一天:Hermes部署 + AI辅助文献检索与筛选
产出:Hermes科研环境 + 检索脚本 + 筛选结果 + 数据提取表
模块一、Hermes Agent部署与科研配置
1、Hermes安装→模型接入(DeepSeek/OpenAI/Anthropic)→验证运行
2、模型选择策略:Opus写作/Sonnet编码/Haiku批量筛选/Ollama本地
3、配置USER.md:让Hermes从通用助手变成"你的课题组成员"
4、备用方案:Claude Code替代+预录数据集兜底
模块二、PICOS设计与检索策略
1、AI辅助检索策略设计:Hermes生成PubMed检索式+MeSH词扩展
2、检索式逻辑完整性检查
3、其他学科案例展示(大气科学、心理学、教育学)
模块三、AI自动化文献检索与初筛
1、PubMed Entrez API批量检索(Biopython) 产出:检索脚本
2、Semantic Scholar补充检索 + 去重合并
3、AI辅助标题摘要筛选(逐篇判断+排除理由) 产出:筛选CSV
4、PRISMA 2020流程图生成(matplotlib动态计算)
模块四、数据提取与效应量计算
1、数据提取表设计+AI辅助PDF数据提取
2、效应量计算:均数差(MD)+标准化均数差(Hedges'g,含J校正)
3、使用课程真实数据(9项RCT/12臂,含Church 2010三臂试验说明)
第二天:统计分析 + Skill封装 + 个人落地
产出:4张投稿级图表 + 统计Skill + Results段落 + 个人方案
模块五、Meta-Analysis统计分析
1、DerSimonian-Laird随机效应模型(手动实现5步算法,纯numpy)
2、异质性检验:Q统计量、I²、τ²产出:统计报告
3、森林图:权重方块+合并钻石+数值标注(纯matplotlib)
4、亚组分析:按运动类型分组+组间异质性Q_between
5、漏斗图+Egger加权回归检验(正确WLS实现)
6、Leave-one-out敏感性分析 产出:4张投稿级图表
模块六、Skill封装与Hermes进化
1、将全套统计流程封装为Hermes Skill(输入CSV一键出图出报告)
2、Hermes自动优化Skill+团队共享方式
3、MCP扩展简介:Zotero文献管理、批量读PDF
模块七、AI辅助结果解读与写作
1、Hermes自动解读统计输出→生成Results段落初稿
2、标准学术句式模板(效应量+CI+P值+异质性描述)
3、AI写作边界:擅长格式化结果描述,需人工核验数值和引用
模块八、综合演练与个人落地
1、两天流程回顾:PICOS→检索→筛选→提取→统计→解读
2、学员自选题实操(60分钟):用自己的选题走全流程
3、Hermes长期维护方案:持续进化+Skill积累
4、Q&A+课后资源发放。
注:请提前自备电脑及安装所需软件。
📞 报名咨询
微信二维码:


关于举办“OpenClaw、Hermes+Vibe Coding核心实战玩法,手把手教你本地部署与云端协同,实现知识、论文自动化工作流”培训班
培训时间:5月23日-24日
基于claude code、codex双AI协同论文写作撰写与质量校准:从"数据分析→论文初稿→交叉审稿"全流程
培训时间:5月16日-17日
最新AI-Python机器学习、深度学习核心技术与前沿应用及Agent自动化全链路实践高级应用
培训时间:5月16日-17日 23日-24日
最新Hermes Agent 技能封装与科研自动化实战:以 Meta-Analysis 为例-实现从文献检 索到绘图的一站式工作流
培训时间:5月30日-31日
点击课程标题了解详细介绍
北斗高精度数据解算实战:破解城市峡谷/长基线/无网区难题,从毫米级定位到自动化交付的全流程攻坚进阶培训班
培训时间:西安现场:5月20日-24日 直播时间:5月21日-24日
第五期:最新AI+Python驱动的高光谱遥感全链路解析与典型案例实践高级培训班
培训时间:5月22日-23日、29日-30日
第八期:融合DeepSeek、GIS 与 Python 机器学习的全流程地质灾害风险评估、易发性分析、信息化建库、灾后重建及SCI论文成果撰写高级培训班
培训时间:5月20日-21日、25日、27日-28日
最新合成孔径雷达干涉测量InSAR数据处理、地形三维重建、形变信息提取、监测等实践技术应用
培训时间:5月23日-24日 30日
从机理到实践告别“黑箱”模拟:OpenGeoSys(OGS6)多物理场THMC 全耦合建模与Python自动化分析高级实战营
培训时间:5月23日-24日、30日-31日
AI赋能下的流域径流模拟、气候变化影响评估及水文水资源管理实践技术培训班
培训时间:5月16日-17日、23日-24日
1、学生可联系课程专员申请助学折扣优惠;
2、报名成功后即成为Ai尚研修终身会员,享受会员福利
3、会员参会最高享受7.5折优惠
4、平台会员免费课程无需购买,可直接进行观看
5、无门槛参加Ai尚研修举办的线上答疑交流会
6、公众号资源无条件全部获

 Ai尚研修客服
Ai尚研修客服
END
Ai尚研修丨专注科研领域
技术推广,人才招聘推荐,科研活动服务
科研技术云导师,Easy Scientific Research
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 最低490分!内蒙古农业大学2025年广东专业录取分数线
- 乡村振兴最新资讯,金融赋能农业科技与产业协作交流对接会在深圳举办
- 刘后华 | 农业、康养、文旅:新时代、新思想、新高度、新融合的产业升级战略
- 【小农说】设施农业 | 草莓种植:娇贵果的“温度密码”,差1℃都亏钱
- 俄罗斯农业热点新闻盘点简报(2026年4月)
- 夏粮季抢收破局:农业供应链代采+库融,破解收粮大户资金死局
- 王子阳 | 不完全市场下农业合约的治理困境与破解路径——基于甘肃省张掖市甘州区玉米制种代繁产业的田野考察
- AI+智慧农业 大模型deepseek+yolo实现棉花病虫害识别
- 【通知公示】农业农村部 公安部 中国海警局关于开展2026年海洋伏季休渔专项执法行动的通知
- 高碑店招聘:农业技术员(种植方向)、会计、销售、综合文职专员
