01|导读
设施农业生产管理常常面临一个现实问题:技术知识分散在管理手册、论文和经验材料中,生产者很难快速获得准确、可执行的答案,尤其是涉及温度、湿度、营养液浓度等定量参数时,普通搜索引擎和通用大模型都容易出现信息不准、答案冗余或事实幻觉。本文速读一篇发表于 Computers and Electronics in Agriculture 的研究,解析其如何构建面向受控环境农业的知识驱动智能服务代理 ChatCEA,通过 RAG、领域知识库和知识整合模块,提升设施农业问答的准确性和实用性。
02|文章信息
题目:ChatCEA: a knowledge-driven intelligent service agent for controlled environment agriculture
期刊:Computers and Electronics in Agriculture
作者:Fulin Xia, Jiandong Pan, Renhai Zhong, Wei Liu, Tongpeng Chen, Linchao Zhu, Yi Yang, Guichao Hua, Tao Lin
通讯作者:Tao Lin
作者单位:浙江大学生物系统工程与食品科学学院、浙江大学应用遥感与信息技术研究所、浙江大学计算机科学与技术学院、杭州四维生物科技有限公司
研究对象:受控环境农业智能问答与生产管理服务
核心数据:设施农业管理手册、期刊论文、CEA 问答基准数据集
核心方法:大语言模型、检索增强生成、知识库构建、混合检索、重排序、非结构化数据处理
论文链接:https://doi.org/10.1016/j.compag.2026.111733
引用格式:Xia, F., Pan, J., Zhong, R., Liu, W., Chen, T., Zhu, L., Yang, Y., Hua, G., & Lin, T. (2026). ChatCEA: a knowledge-driven intelligent service agent for controlled environment agriculture. Computers and Electronics in Agriculture, 248, 111733.
03|研究问题
受控环境农业包括温室、植物工厂和垂直农场,核心特点是通过环境调控和栽培管理实现高效生产。但在实际生产中,种植者经常需要面对作物管理、环境参数调节、病虫害防控、水肥管理等复杂问题。
传统专家系统依赖固定规则,难以适应动态生产场景;搜索引擎虽然信息量大,但缺乏上下文理解,用户需要自行筛选和验证信息;通用大模型具备较强生成能力,但在专业设施农业场景中容易出现答案泛化、定量参数错误和事实幻觉。
本文关注的核心问题是:如何将大语言模型与设施农业领域知识结合,构建一个能够回答专业问题、处理定量参数、并支持本地部署的智能服务代理?
核心矛盾:设施农业问题专业性强、参数化程度高,而通用搜索和通用大模型难以稳定提供准确、可执行的答案。
04|方法思路
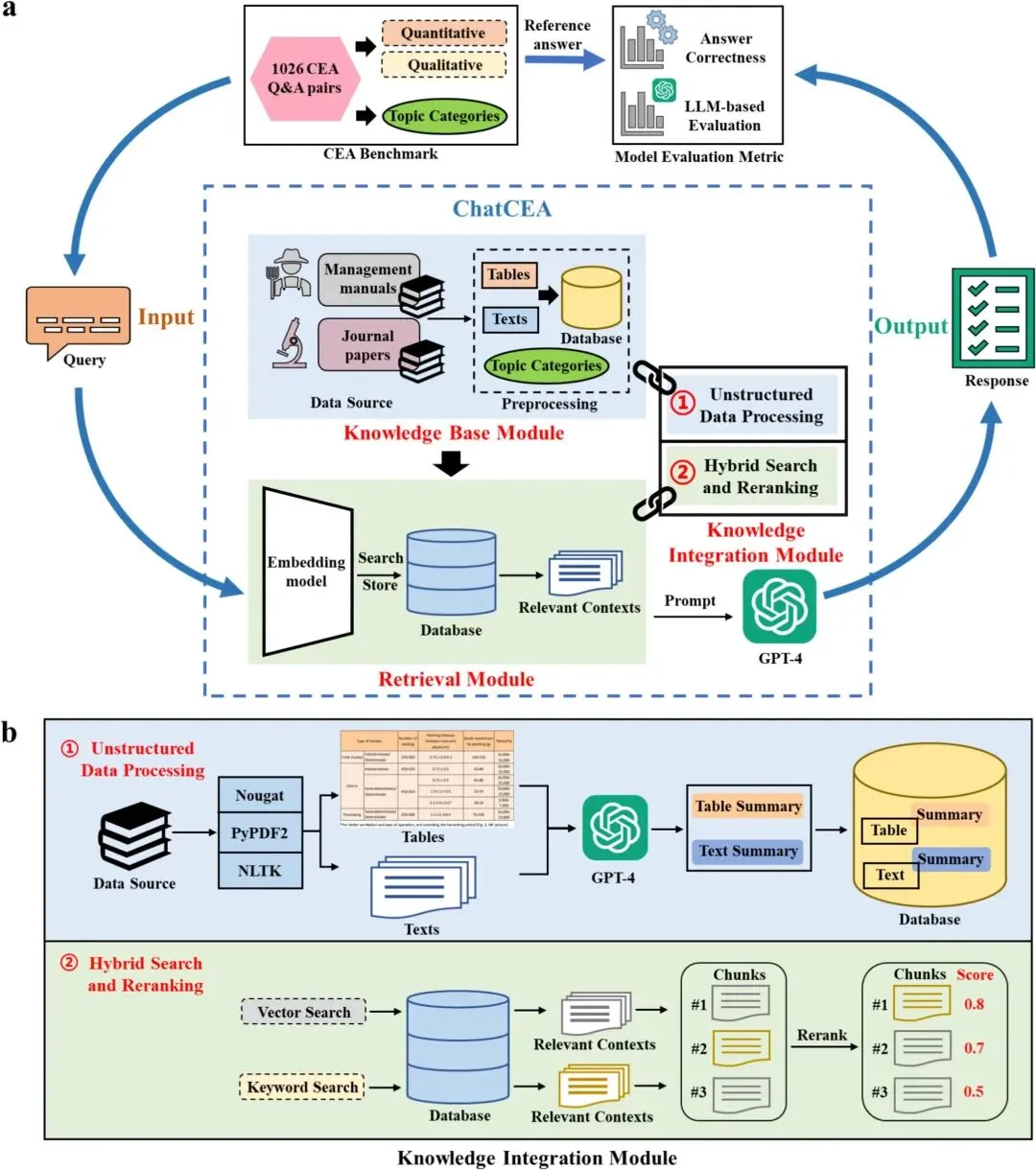
文章提出了 ChatCEA,一个基于大语言模型和 RAG 的设施农业知识驱动智能服务代理。其核心逻辑是:不是让大模型完全依赖预训练知识回答问题,而是先从设施农业知识库中检索可靠上下文,再由大模型生成面向生产管理的答案。
ChatCEA 主要包括三个模块。第一是知识库模块,整合管理手册和期刊论文,为模型提供设施农业领域知识。第二是检索模块,将文本转化为向量表示,通过语义匹配从知识库中找到与用户问题相关的内容。第三是知识整合模块,进一步处理非结构化数据,并通过混合检索和重排序提升检索结果的准确性。
也就是说,ChatCEA 的关键并不是简单调用 GPT-4,而是通过“领域知识库 + 检索增强 + 知识整合”约束大模型回答,使其更接近真实生产需求。
核心方法:用设施农业知识库约束大模型生成,用 RAG 降低幻觉,用知识整合提升定量问答能力。
05|知识库与基准数据集
文章构建了一个面向设施农业的双来源知识库。知识来源包括 276 份管理手册和 300 篇期刊论文。其中,管理手册更偏向实际生产操作,如温室配置、营养液管理、光照设计和环境控制;期刊论文则更多覆盖环境调控、病虫害管理和先进技术研究。
作者将知识库内容划分为环境控制、植物管理、病虫害、土壤与水培、水肥管理、综合流程管理和其他主题,以便模型在不同生产环节中进行针对性检索。
同时,文章构建了首个 CEA 专用问答基准数据集,共包含 1025 个问答对,并区分为定性问题和定量问题。定量问题涉及温度、湿度、营养液浓度、灌溉量、光照强度等具体数值,是检验模型能否真正服务设施农业生产的重要环节。
核心设计:知识库解决“专业知识来源”问题,CEA Benchmark 解决“系统评估标准”问题。
06|主要结果
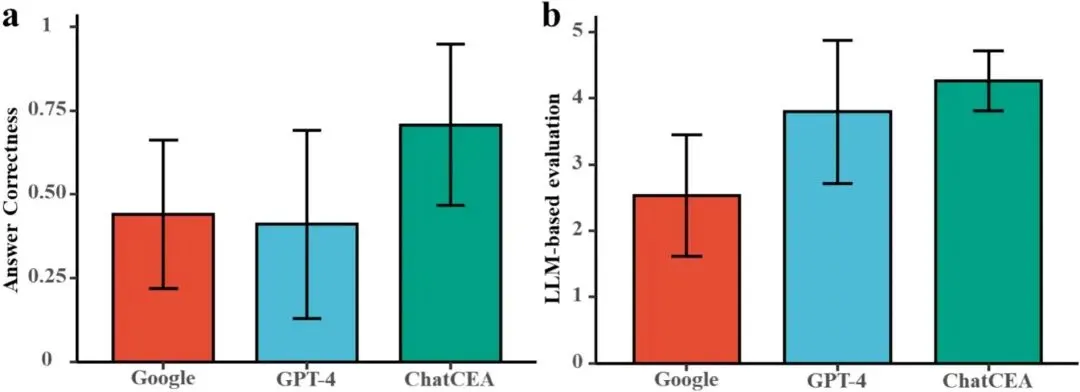
结果 1:ChatCEA 明显优于搜索引擎和通用 GPT-4
在随机抽取的 15 个问答样本中,ChatCEA 的答案正确率达到 0.71,高于 GPT-4 的 0.41 和 Google Search 的 0.44;LLM 评价分数达到 4.3,也高于 GPT-4 的 3.8 和 Google Search 的 2.5。说明领域知识增强后,大模型在设施农业专业问答中的准确性和可用性明显提升。
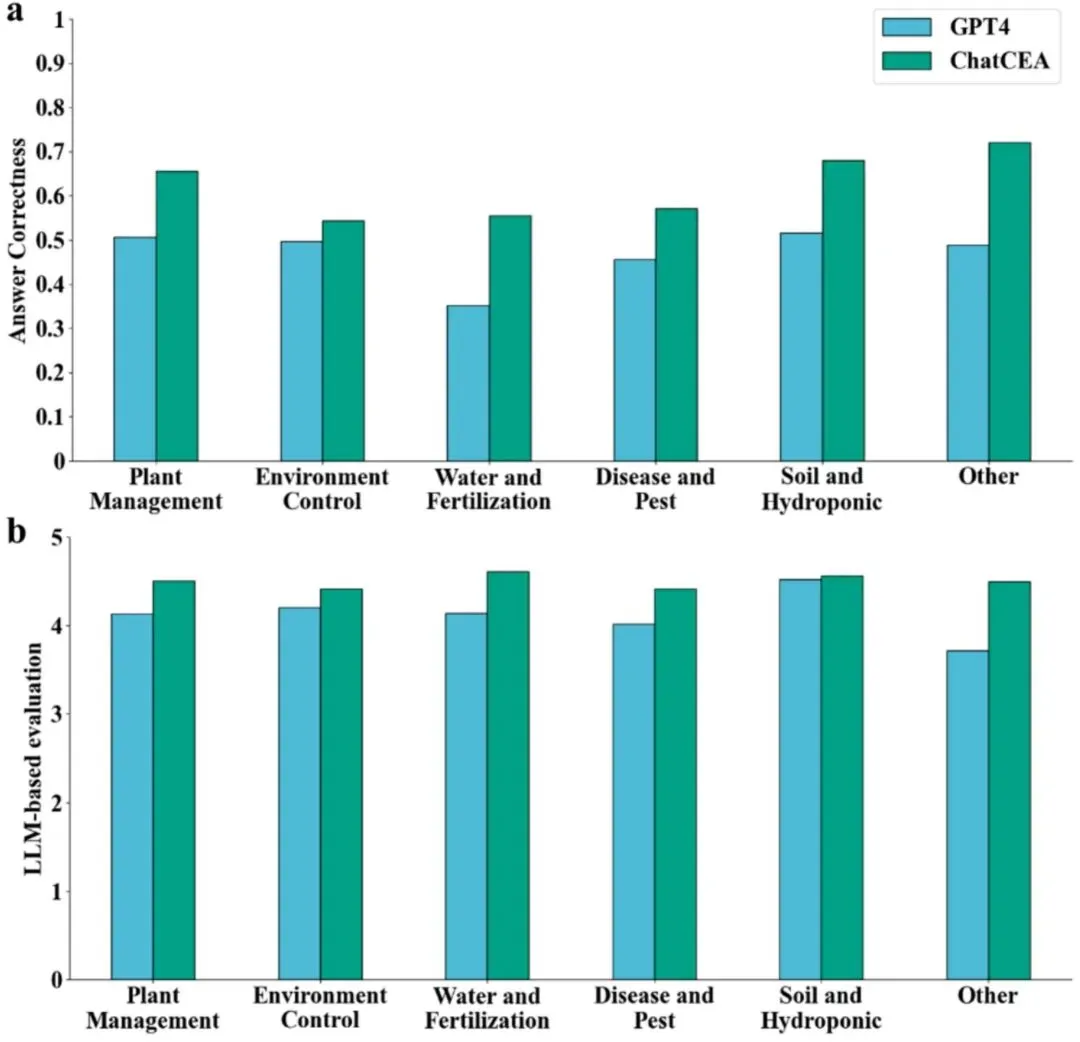
结果 2:领域知识库提升所有主题下的回答表现
在植物管理、水肥管理、土壤与水培、病虫害和环境控制等主题中,ChatCEA 均优于 GPT-4。其中,水肥管理和植物管理提升最明显,说明通用大模型在专业参数和具体操作建议方面仍存在不足,领域知识库能够有效补齐这一短板。
结果 3:知识整合模块强化定量问答能力
面对定量问题时,GPT-4 容易缺少关键数值信息,传统 RAG 又可能检索不到最相关内容。ChatCEA 通过非结构化数据处理、混合检索和重排序,能够更好地从文本和表格中提取温度、湿度等数值信息,并将其放入正确语境中。其定量任务 LLM 评价分数达到 4.47,定性任务为 4.42,表现较为稳定。
结果 4:管理手册对实用问答贡献突出
去除管理手册后,ChatCEA 在所有主题中的表现均下降,尤其是植物管理类别下降最明显。这说明设施农业智能问答不能只依赖论文知识,还需要大量操作型、经验型和生产型知识支撑。
07|研究启发
这篇文章的启发在于,它把农业大模型应用的重点从“能不能回答”推进到“能不能基于可靠知识回答”。
对于设施农业这类高度专业化、参数化和场景化的生产系统,通用大模型的语言能力并不等同于生产决策能力。真正有价值的智能服务代理,需要同时具备三个基础:高质量领域知识库、可靠检索机制和对定量信息的精准处理能力。
同时,文章也提示我们,农业智能体建设不能只关注模型本身,还要关注知识来源、知识结构、检索质量和评估基准。尤其是在农业生产管理中,一个错误的温度、湿度或营养液参数,可能直接影响作物生长和经济收益。
08|一句话总结
这篇文章构建了面向受控环境农业的知识驱动智能服务代理 ChatCEA,通过领域知识库、RAG 和知识整合模块,显著提升了设施农业专业问答的准确性、定量参数提取能力和生产管理实用性。
09|关键图表
图 1|ChatCEA 技术框架
展示 ChatCEA 的整体结构,包括知识库模块、检索模块、知识整合模块和 CEA Benchmark,是理解全文方法设计的核心图。
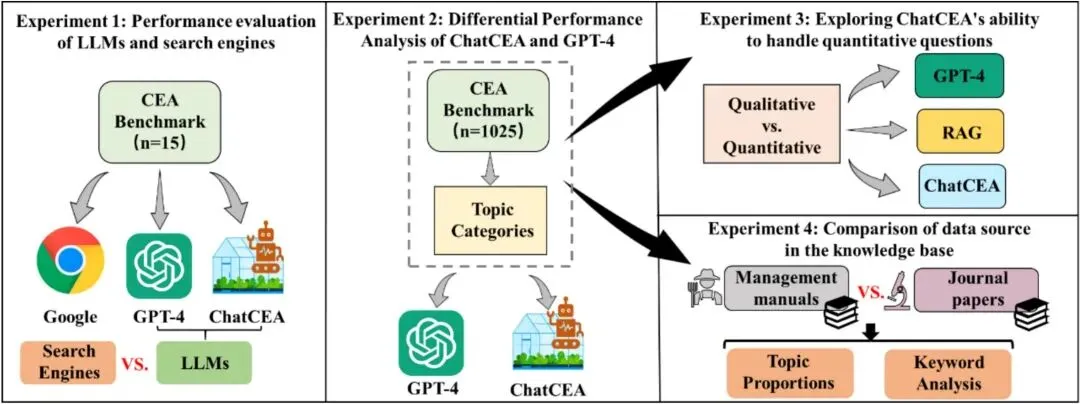
图 3|实验设计流程
概括 Google Search、GPT-4、传统 RAG 和 ChatCEA 的对比实验设计,展示文章如何从模型性能、知识来源和知识整合模块三个层面验证系统效果。
图 4|ChatCEA 与 Google、GPT-4 性能对比
比较三类系统在答案正确率和 LLM 评价分数上的表现,直观体现 ChatCEA 相比搜索引擎和通用大模型的优势。
图 5|不同 CEA 主题下的模型表现
展示 ChatCEA 和 GPT-4 在植物管理、环境控制、水肥管理、病虫害、土壤与水培等主题中的表现差异,说明领域知识库的增益具有普遍性。
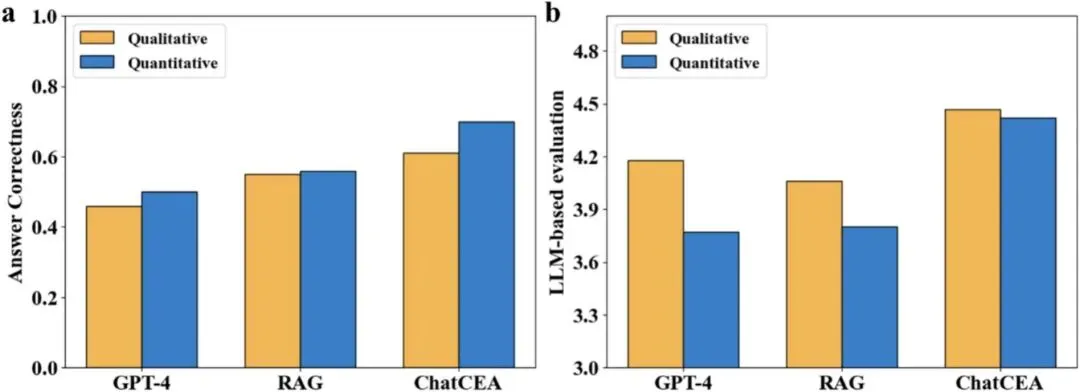
图 7|定性与定量问题表现对比
比较 ChatCEA、GPT-4 和传统 RAG 在定性、定量任务中的表现,突出 ChatCEA 对数值型生产问题的处理能力。
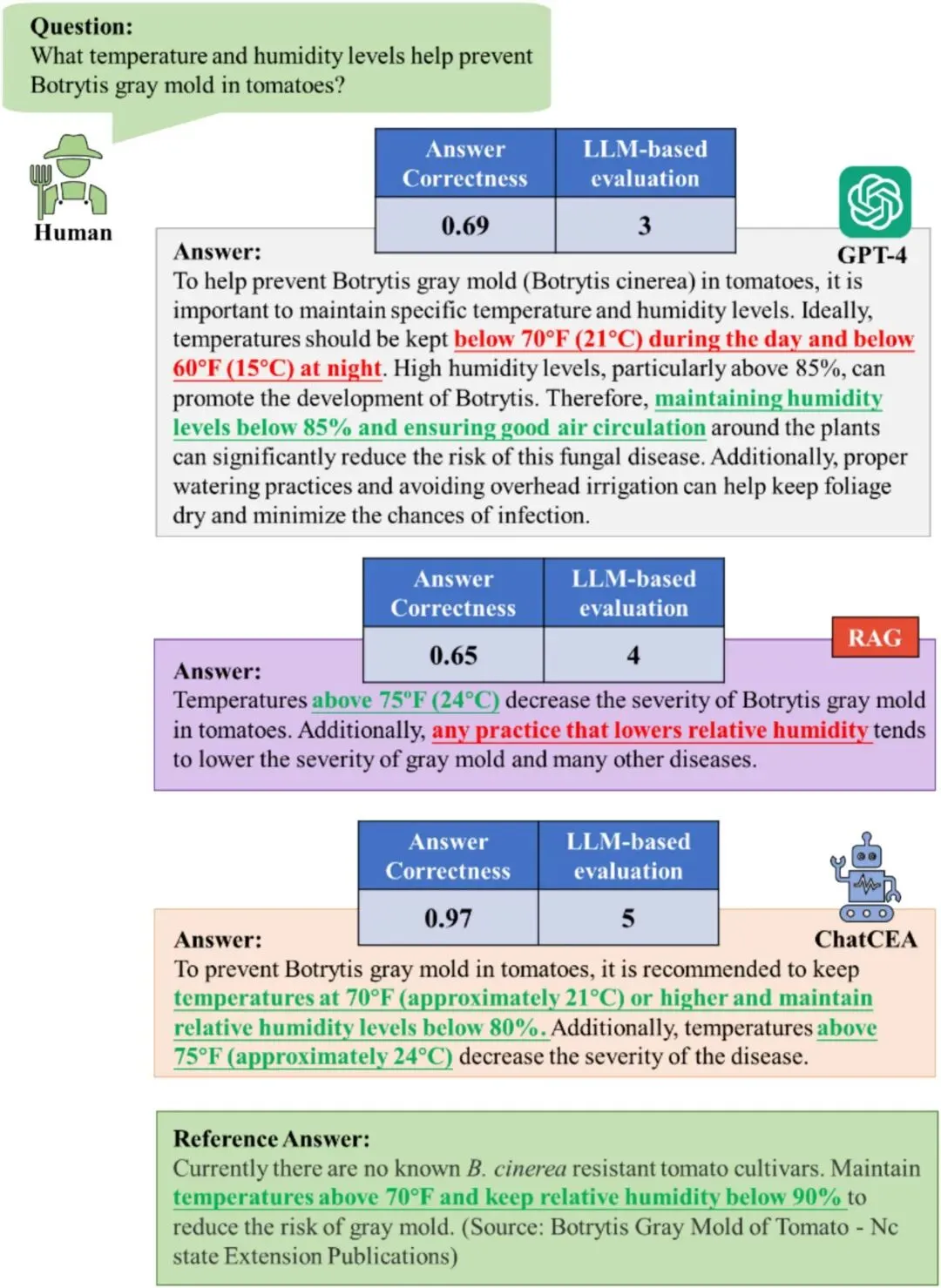
图 8|定量问答案例对比
通过番茄灰霉病温湿度管理问题,展示 GPT-4、传统 RAG 和 ChatCEA 在关键数值、语义准确性和答案可用性方面的差异。
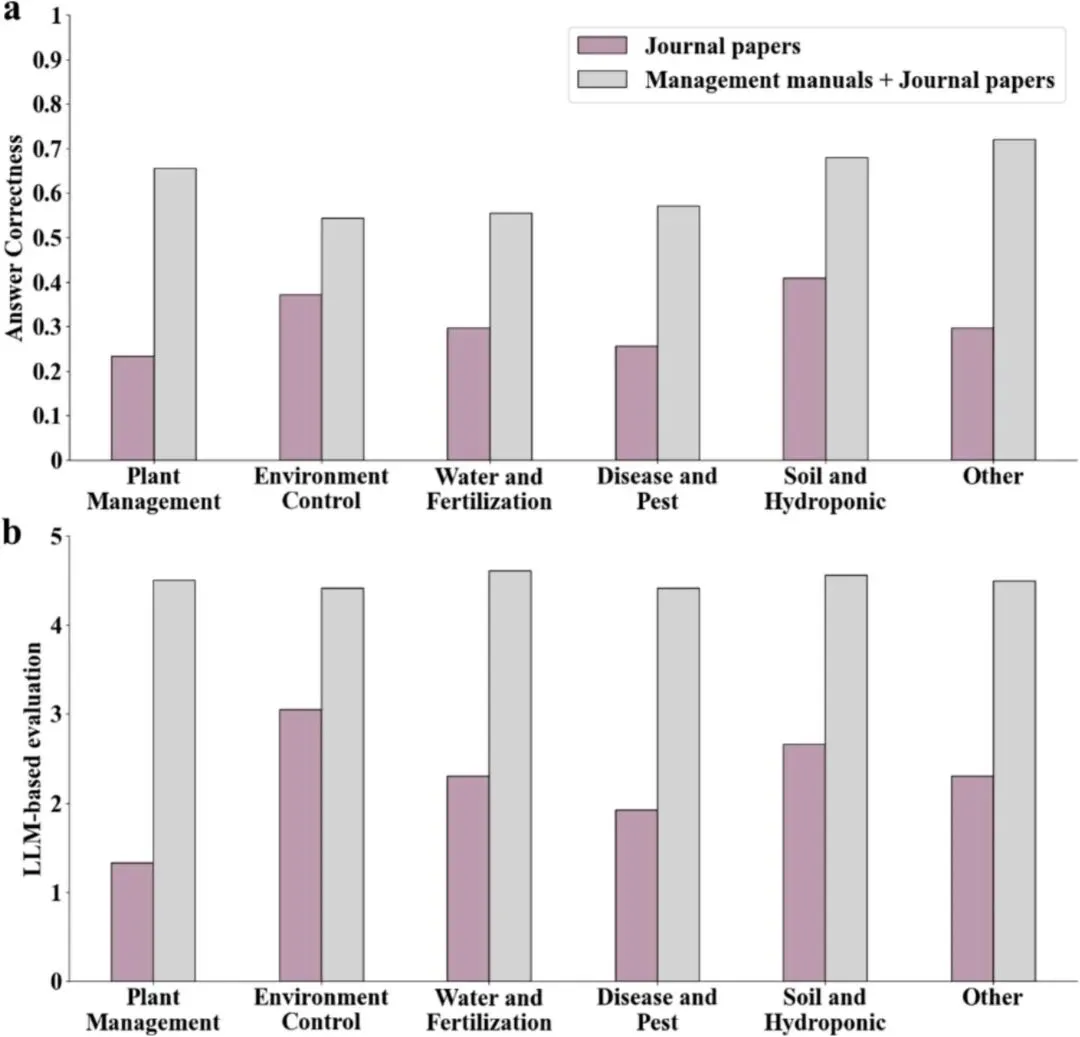
图 10|知识来源贡献分析
展示管理手册和期刊论文共同构建知识库后对 ChatCEA 性能的提升,说明生产管理类知识在设施农业智能问答中的重要作用。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
