农业AI的“ImageNet”来了!63万张图,1167种植物,超强公开数据集发布!
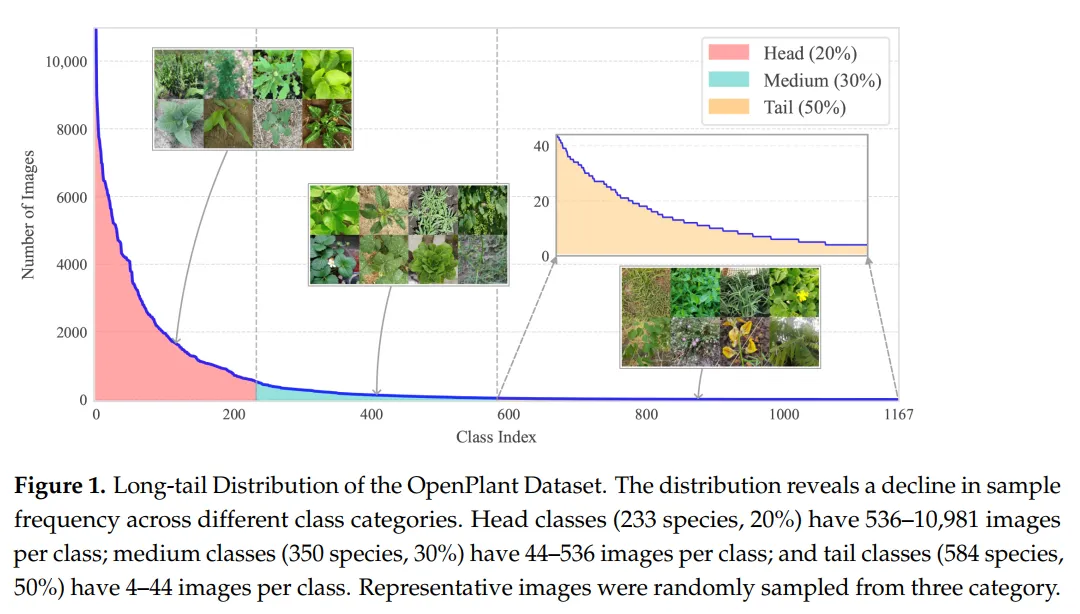
当AI遇上农业,识别杂草、监测作物却总被“小数据”卡脖子?现在,这个瓶颈被彻底打破了!👇随着人工智能和深度学习技术的飞速发展,精准农业正迈向数据驱动的新阶段。植物分类——利用深度学习从图像中识别植物物种——已成为杂草管理、入侵物种防控和作物监测等任务的关键技术。然而,现有农业图像数据集普遍存在物种类别少、环境多样性低、数据难以整合三大局限,导致训练的模型“水土不服”,难以在真实复杂的农田中发挥作用。这严重制约了农业AI的落地与推广。为此,一项研究带来了一个革命性的解决方案。这项研究构建了名为OpenPlant的大型公开数据集,并在此基础上对当前主流的深度学习模型进行了一次“全面体检”,为农业植物分类建立了全新的性能基准。数据集规模:OpenPlant 包含635,176张RGB图像,涵盖1,167个植物物种,数据整合自41个开源仓库,是已知规模最大、物种最丰富的公开农业植物数据集之一。数据呈现真实“长尾分布”:数据并非均匀分布,而是真实反映了自然界物种的常见与稀有程度。模型基准全面建立:研究系统评估了10个卷积神经网络(CNNs)、6个视觉变换器(ViTs)和12个视觉-语言模型(VLMs),共计28个模型,提供了清晰的性能对比。OpenPlant 不仅提供了海量数据,其包含的多样生长阶段、植物结构和环境条件,更是确保AI模型能在真实农田中“活学活用”的关键。【图1:OpenPlant数据集的长尾分布图】 该分布揭示了不同类别样本频率的下降趋势。头部类别(233个物种,占20%)每类拥有536–10,981张图像;中部类别(350个物种,占30%)每类拥有44–536张图像;尾部类别(584个物种,占50%)每类仅拥有4–44张图像。下图展示了从三类中随机采样的代表性图像。这个分布意味着,数据集中有大量(584种)植物只有很少的图片样本。这要求分类模型必须具备强大的“小样本学习”能力,而不仅仅是识别常见物种。OpenPlant 为智慧农业解决方案提供商提供了标准化训练资源。植保无人机、智能除草机器人公司可以直接利用该数据集,大幅提升其核心识别模型的准确性与鲁棒性。填补了农业计算机视觉领域大规模基准数据集的空白。研究完成了对CNN、ViT、VLM三大技术路线共28个模型的统一基准测试,为学术界提供了公平、可靠的算法性能“标尺”,明确了不同模型架构在复杂农业场景下的适配性与优劣,引导后续研究聚焦于核心算法创新。数据收集与整合:从41个公开数据源系统性地收集了超过63万张植物图像,并按照统一的分类学框架进行整理,覆盖1167个物种。数据清洗与标注验证:对所有图像的类别标注进行人工仔细核查与修正,确保数据质量,并记录了植物的生长阶段、结构等多元信息。基准测试框架建立:选取了10个经典CNN模型(如ResNet系列)、6个主流ViT模型及12个前沿VLM模型(如CLIP系列),在OpenPlant上使用相同的训练-验证-测试划分进行公平评估。性能分析与洞察:详细对比了各类模型的分类准确率等指标,并深入分析了模型性能与物种分类学特征、数据样本量之间的关系。👥作者:Kaiqi Liu, Wei Sun, Guanping Wang, Quan Feng, Hui Li🔗DOI:10.3390/plants15050727
不学 AI 搞农业,再努力也被淘汰!
如果觉得这项“夯实地基”的研究有意义,点个「在看」或「转发」到朋友圈,让更多关注农业未来的朋友看到吧!👇


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
