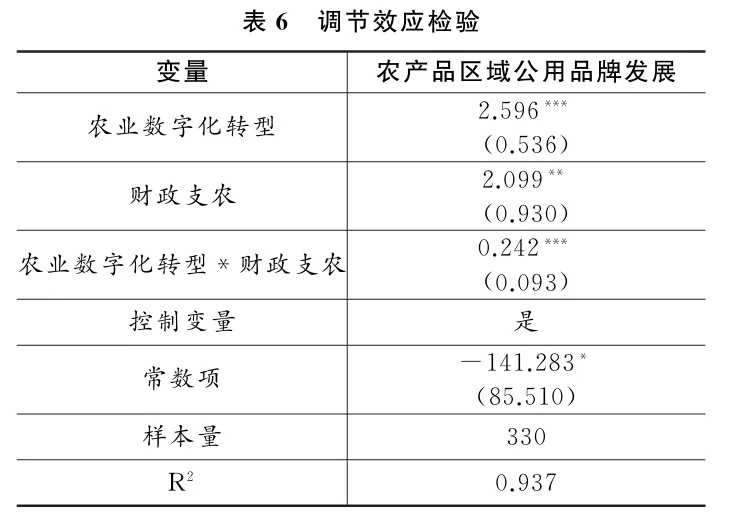
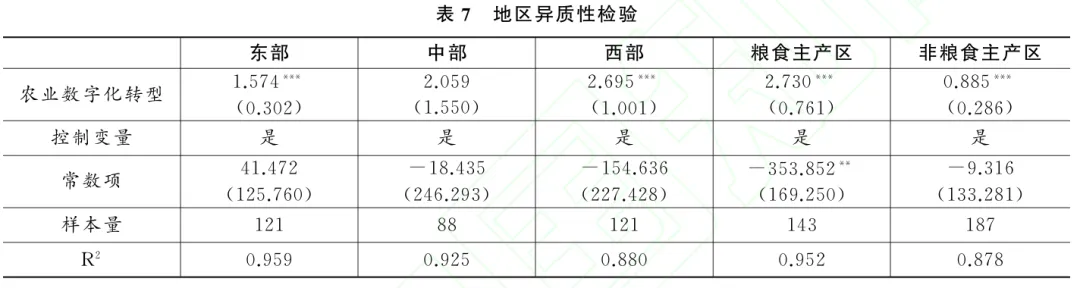
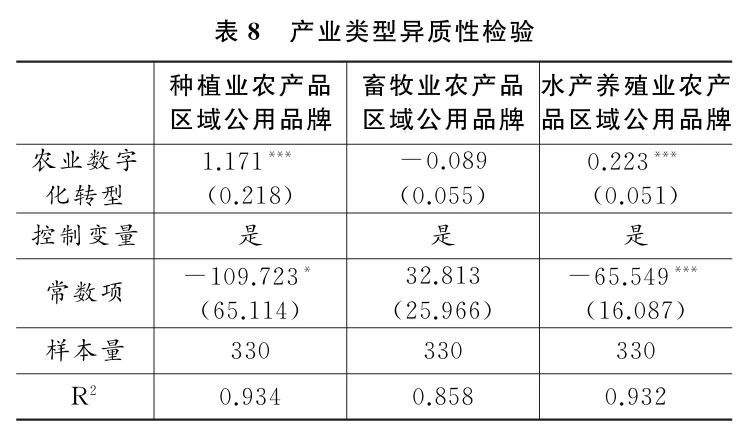
(二)稳健性检验
为了检验基准回归结果的稳健性,本文采用以下方法:(1)对样本数据进行1%水平的缩尾处理,以消除极端值影响;(2)采用熵权Topsis法对农业数字化转型重新测度;(3)将解释变量滞后一期,以考虑滞后效应;(4)剔除直辖市样本,以排除行政层级差异可能导致的回归偏误;(5)鉴于传统线性回归模型的局限性,采用双重机器学习模型(DML)对基准回归结果进行再估计,以保证因果识别的有效性.具体而言,本文设定1∶4的样本分割比,采用随机森林算法对主回归和辅助回归进行预测求解,并取均值作为估计结果。
此外,为控制其他相关政策对研究结果的潜在干扰,本文采取以下措施:(1)国家于2016年分两批在10个省份设立“国家级大数据综合试验区”试点。该政策可能对区域数字化进程产生影响,故在模型 中引入“国家级大数据综合试验区”的虚拟变量,以控制该政策的干扰。(2)农业农村部自2011年起实施“一村一品”认定政策.各地区“一村一品”认证数量可反映乡村特色产业的发展水平,间接影响区域公用品牌建设。为此,本文将各省“一村一品”的认证数量纳入控制变量,以排除该政策的影响。(3)2019年《数字乡村发展战略纲要》的出台标志着我国数字乡村建设进入加速发展阶段,可能对农业数字化转型产生制度性推动。为此,本文剔除2019年以后的样本进行回归。
在上述稳健性检验中,农业数字化转型对农产品区域公用品牌发展仍具有显著的积极影响,进一步表明本文实证结论的稳健性。














 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
