在农业遥感监测领域,卫星图像时间序列(SITS)堪称“神器”——能捕捉作物完整的物候周期,帮我们精准提取耕地、分类作物。但现实总是骨感:全球月均云覆盖率高达66.5%,云污染导致的时序数据缺失,会让模型性能“断崖式”下跌。传统方法要么强行补全缺失数据(容易引入噪声),要么模拟缺失场景做数据增强(泛化性差),都没解决核心问题。最近一篇发表在TGRS 2025的论文,提出了一套超实用的联合学习框架,专治不完整SITS的农业语义分割难题,还能适配多种模型、传感器和任务,简直是农业遥感的“全能选手”!
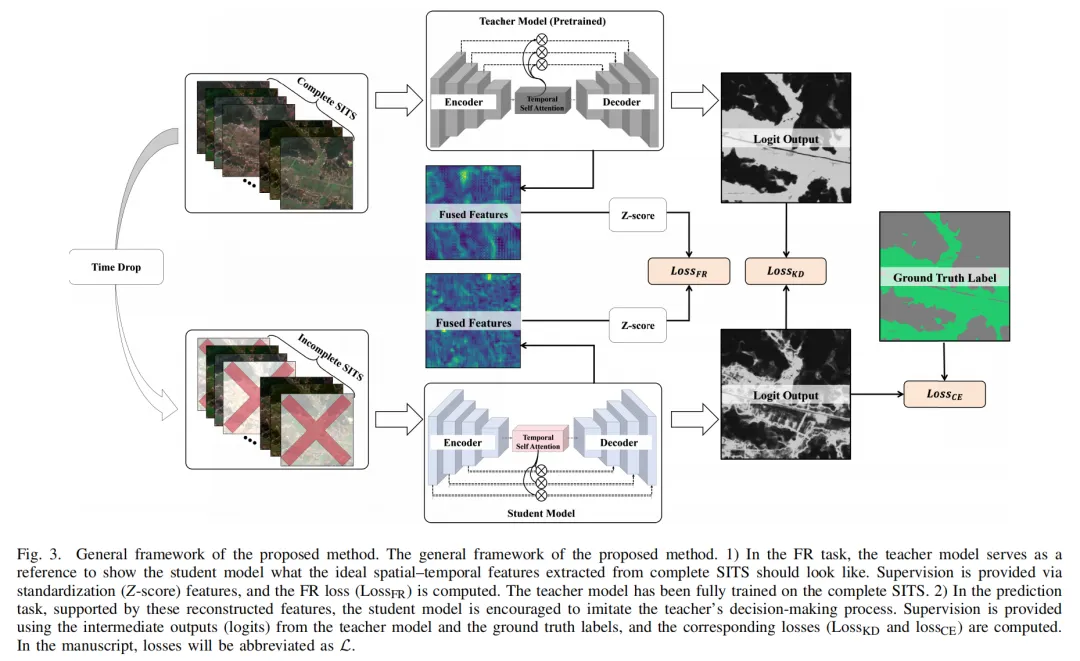 先来看这张核心框架图!整个方法的精髓,就是把“特征重建(FR)”和“预测任务”绑在一起学,还拉上了“教师模型”当“裁判”——教师模型先用完整的SITS练好本领,再指导学生模型从缺斤少两的时序数据里,只重建对预测有用的关键特征,彻底告别“盲目补全”的坑。
先来看这张核心框架图!整个方法的精髓,就是把“特征重建(FR)”和“预测任务”绑在一起学,还拉上了“教师模型”当“裁判”——教师模型先用完整的SITS练好本领,再指导学生模型从缺斤少两的时序数据里,只重建对预测有用的关键特征,彻底告别“盲目补全”的坑。
我整理了“农业遥感+农业语义分割”方向10篇相关论文,帮助大家了解学习“农业遥感+农业语义分割”方向,选题,挖创新点。
论文信息
题目: Joint Learning for Feature Reconstruction and Prediction in Agricultural Semantic Segmentation From Incomplete Satellite Image Time Series
基于不完整卫星图像时间序列的农业语义分割特征重建与预测联合学习
作者:Yuze Wang, Mariana Belgiu, Haiyang Wu, Dandan Zhong, Yangyang Cao, Haifeng Li, Chao Tao
为啥传统方法不好用?
先聊聊痛点:云污染导致SITS出现时间间隙,不仅破坏了作物物候的时间依赖关系,还会让数据分布跑偏。
- 数据重建法(DR):要么用插值、要么用深度学习补全整个时序,但很容易引入噪声,还做了很多无用功——毕竟模型只需要关键物候特征,不是完整序列;
- 数据增强法(DA):比如随机删时间步、切时间窗口,虽然能练模型的抗造能力,但容易让模型学“偷懒”(走捷径推理),还可能忘了解决完整SITS的问题。
这篇论文的思路就特别清奇:不补全图像,只重建对预测有价值的特征;不盲目增强数据,让教师模型带着学生模型学“正确的推理逻辑”。
这个联合学习框架到底咋玩?
第一步:先找个“好老师”
先用完整、无云的SITS训练一个“教师模型”,把它的参数冻结,相当于让它记住“完整时序该有的特征长啥样”。然后给学生模型喂“残缺版”SITS——通过随机屏蔽25%-75%的时间步,模拟真实的云污染缺失场景。
第二步:特征重建只抓“关键信息”
学生模型从残缺数据里提取特征,教师模型从完整数据里提取“标准答案特征”。这里有个超贴心的设计:给特征做Z-score标准化(看下图),让学生模型别死抠数值细节,重点学全局的时序变化规律,避免被局部噪声带偏。
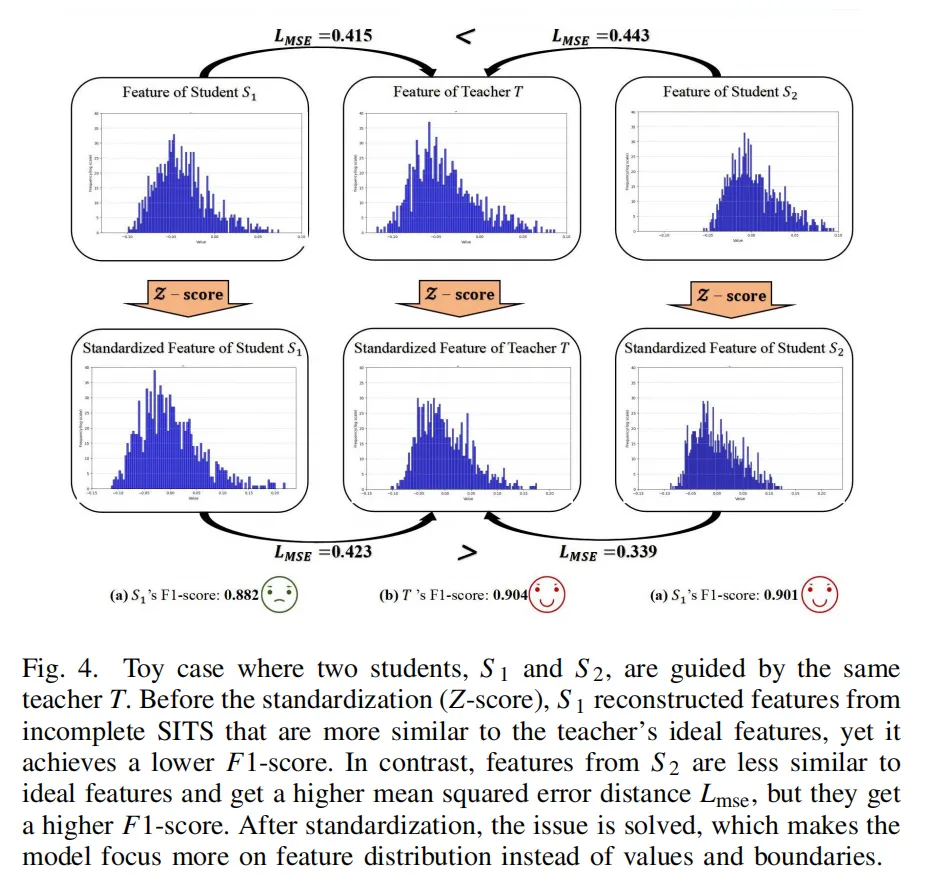 而且重建不是“照猫画虎”,还要结合真实标签监督——只重建对耕地提取、作物分类有用的特征,没用的信息直接放弃,既省计算又避噪声。
而且重建不是“照猫画虎”,还要结合真实标签监督——只重建对耕地提取、作物分类有用的特征,没用的信息直接放弃,既省计算又避噪声。
第三步:预测任务学“老师的推理逻辑”
学生模型不仅要输出正确的分割结果(用真实标签监督),还要模仿教师模型的“思考过程”——通过知识蒸馏,让学生模型的输出逻辑和教师模型对齐。这样一来,学生模型不会因为数据缺失就瞎推理,而是学会基于长期时序依赖做判断,再也不搞“捷径操作”。
整个过程就是:特征重建帮模型抓准核心时序信息,预测任务帮模型练出靠谱的推理能力,两者互相约束,既不冗余也不跑偏。
实测效果:多场景吊打传统方法!
作者做了超多实验验证,覆盖不同任务、传感器、区域,结果都超亮眼:
1. 耕地提取:不管是Sentinel-2还是PlanetScope都好用
- 数据集:湖南的Sentinel-2(10米分辨率)和PlanetScope(3.7米高分辨率)耕地数据,既有模拟缺失场景,也有真实云污染数据;
- 对比结果:传统DR方法甚至比基线还差,DA方法略有提升,但论文方法在模拟实验中耕地F1分数超基线5.42%,真实场景中直接超了49.28%!
看下图就能直观感受到差距:论文方法能精准捕捉细碎、狭长的耕地,边界更完整,细节也更到位。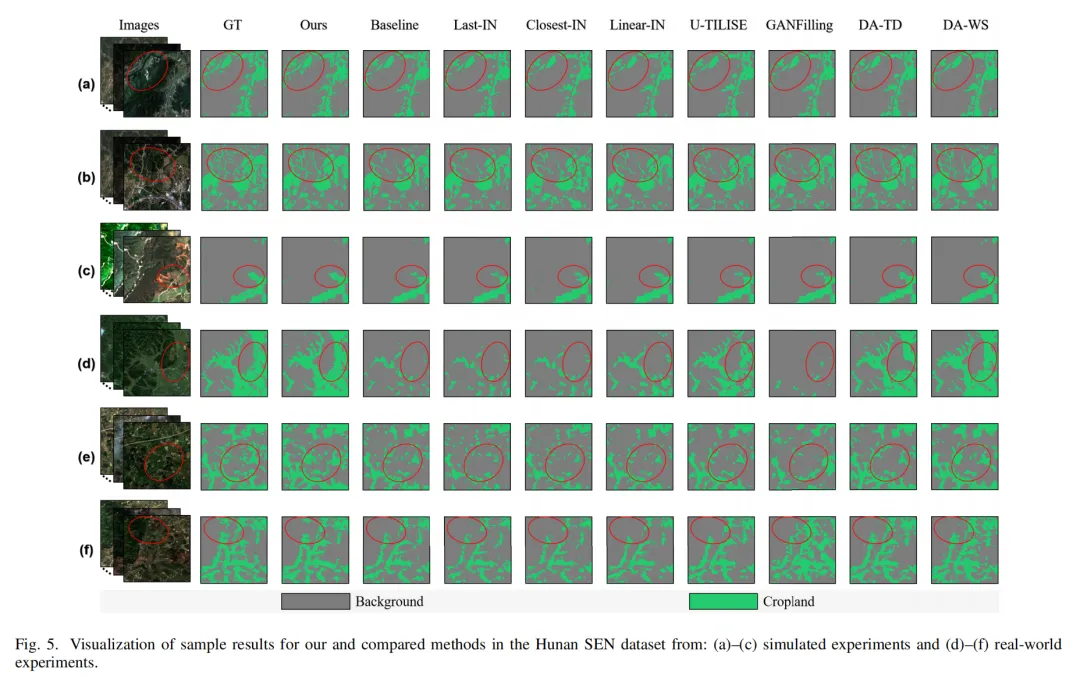
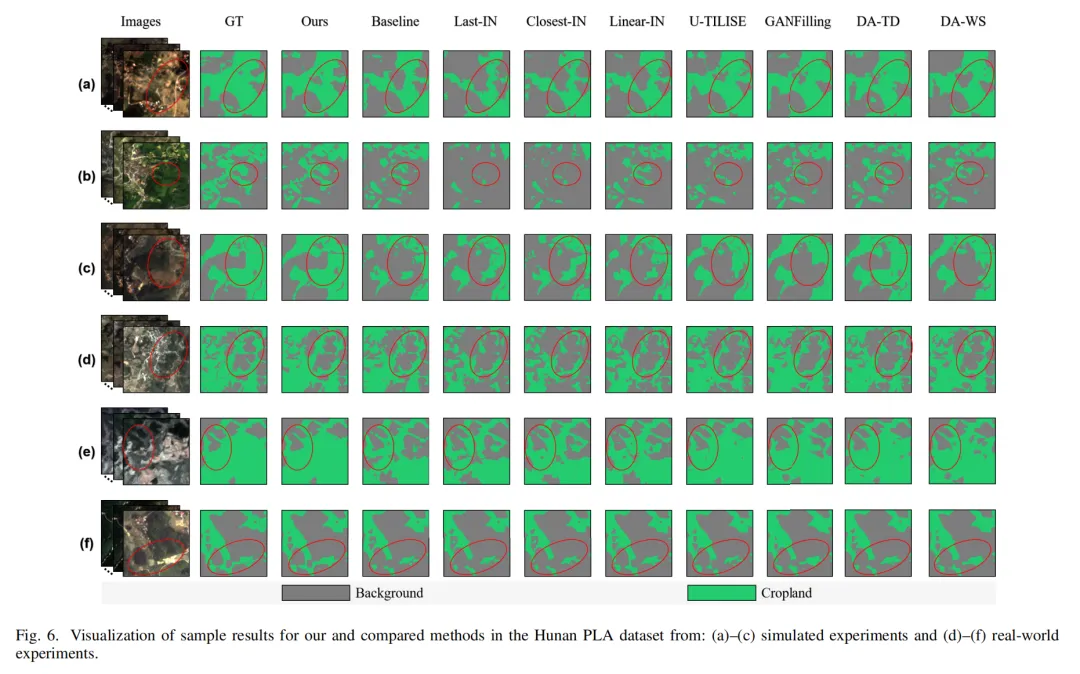
2. 作物分类:复杂场景也能稳得住
用法国西部、加泰罗尼亚的Sentinel-2数据做8类作物分类,传统方法在复杂物候作物(比如块根作物、豆类)上拉胯,而论文方法的平均F1分数在模拟场景超基线10.35%,真实场景也超了3.83%。
从下图能看到,论文方法能准确区分混作场景里的不同作物,边界描绘更精准,就算是物候特征不明显的蔬果类,也比其他方法表现好。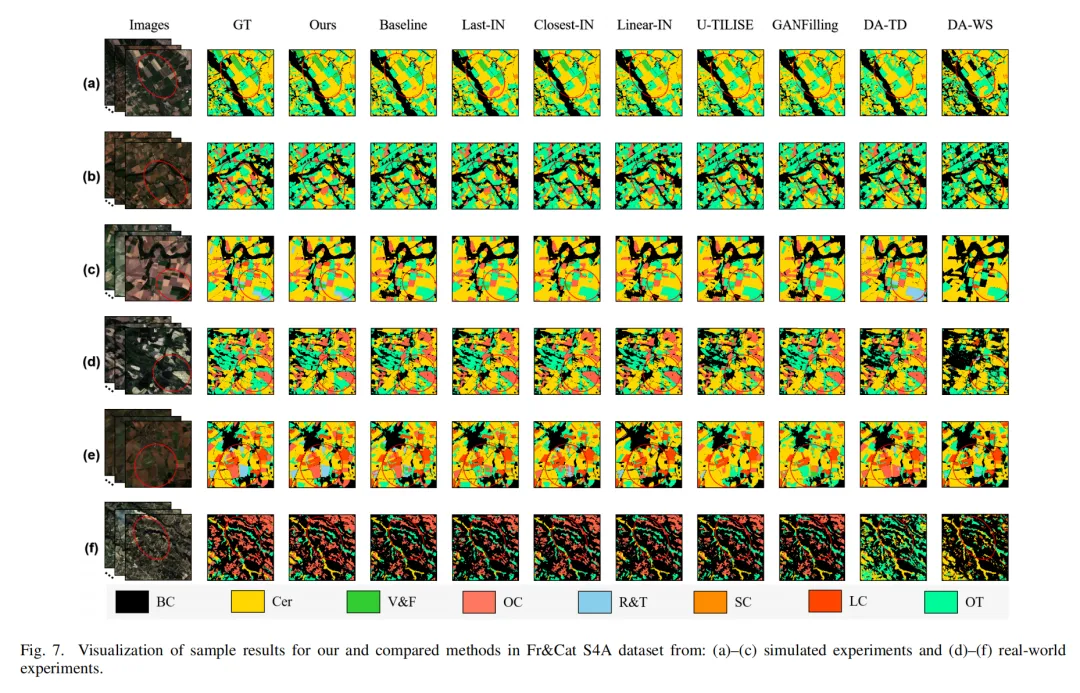
3. 泛化性拉满:适配7种骨干网络
不管是RNN、3D CNN还是自注意力模型(比如U-TAE),这个框架都能无缝衔接,而且在25%-75%的缺失率下都能保持高性能,真正做到“模型无关”,直接集成到现有农业监测系统里就行。
4. 成本可控:训练稍加成本,推理零额外开销
虽然训练时比基线多了一点计算和时间成本,但远低于深度学习类的DR方法;推理阶段完全不增加开销,在多云地区的农业监测中,性价比直接拉满。
总结:不止解决问题,更适配实际应用
这篇论文最牛的地方,不是单纯提了一个新模型,而是切中了农业遥感的实际痛点:云污染导致的时序数据缺失是常态,与其强行“补数据”,不如让模型学会“抓重点、学逻辑”。
这个联合学习框架既避免了冗余重建的噪声,又防止了模型学偷懒,还能适配不同传感器、任务和模型架构,不管是耕地提取还是作物分类,不管是Sentinel-2还是PlanetScope数据,都能稳得住。
目前代码已经开源,对于做农业遥感、语义分割的同学来说,绝对是值得一试的实用方法!毕竟在真实场景中,能解决“云污染”这个老大难问题,才是真的能落地的好研究~



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
