在开展县域农业适宜性评价时,规范给出的限制因子分级(如坡度大于25度、海拔高于2000米)往往过于宽泛,难以精准刻画复杂地形下小尺度的生态本底特征。
如何让评价指标真正“本地化”?如何证明我们的分级标准是科学的,而不是“拍脑袋”决定的?
今天,我们将分享一种“让数据开口说话”的方法——基于现状土地利用格局的地形因子箱线图反推法。确保农业适宜性评价科学严谨的。
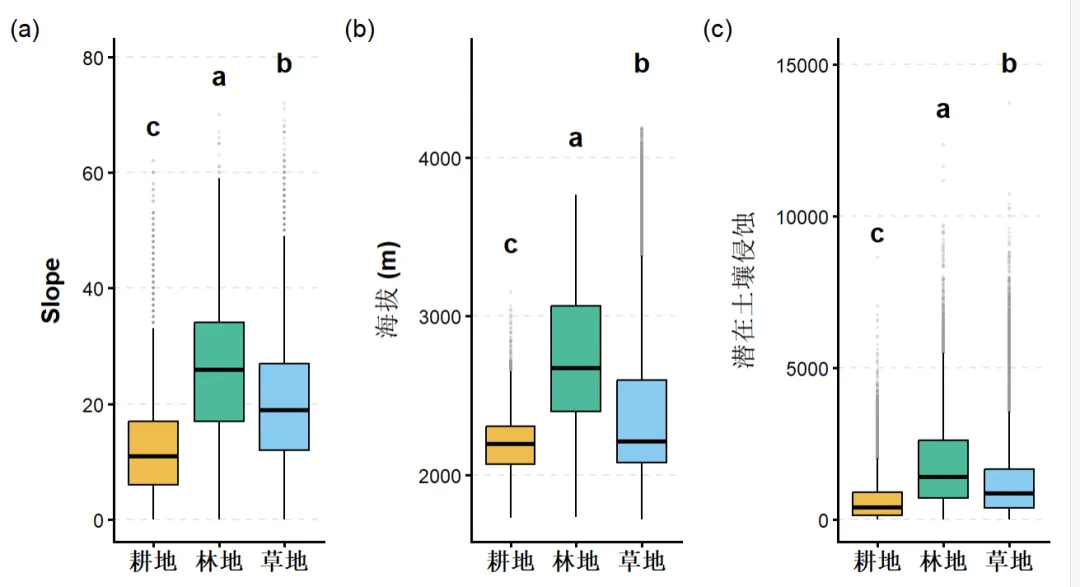
不同地区的农业生产有着其独特的自然禀赋和历史选择。通过箱线图,我们可以极其直观地看到:
耕地的“核心区”在哪? 比如,图中显示绝大多数耕地高度集中在 6° 以下的平缓地带或特定海拔区间(通常是箱体的 25%-75% 核心分布区)。这直接为我们划定“高度适宜区(1级)”提供了坚实的数据支撑。
生态的“红线”在哪? 林地在箱线图中呈现出明显的“高海拔、大坡度”分布特征,其下四分位数精准地指示了人类高强度农耕活动的生态退让边界(如坡度 25°)。这个数值就不再是盲目的套用,而是本区域真实的自然选择。
通过统计学非参数检验(图中显著性字母a, b, c),我们能够科学地确立各评价指标在本地的最优分界阈值。
逻辑是:“存在即有其合理性”。 历史上长期沉淀下来的土地利用现状(只要不是严重破坏生态的盲目开垦),本身就是大自然和人类千百年来“双向奔赴”的适宜性结果。
正向推导:我们从现状土地利用分布特征中提取出本地化的分级阈值,输入到模型中进行适宜性空间演算。
反向验证:最终的农业高度适宜区,必然(且必须)与箱线图揭示的现状优质耕地核心分布区高度重合。如果不重合,说明我们的指标权重或阈值存在偏差,需要迭代调整。

# 终极版通用绘图函数# 终极版通用绘图函数 (已修复 NA 报错)# 不进行对数转换的绘图函数plot_academic_box_linear <- function(data, y_var, y_label) { clean_data <- data %>% filter(!is.na(.data[[y_var]]) & !is.na(Landuse)) sig_data <- get_sig_letters(clean_data, y_var) ggplot(clean_data, aes(x = Landuse, y = .data[[y_var]], fill = Landuse)) + geom_boxplot(alpha = 0.7, outlier.size = 0.5, outlier.alpha = 0.2, outlier.color = "grey60", linewidth = 0.6, color = "black") + scale_fill_manual(values = my_colors) + # 删除了 scale_y_log10() 模块,恢复默认线性坐标轴 # 注意:因为没有了 log10 的压缩,显著性字母的 Y 轴高度位置需要略微调低 # 这里从乘以 1.5 改为乘以 1.1,避免字母飞得太高 geom_text(data = sig_data, aes(x = Landuse, y = Max_Value * 1.1, label = Letter), size = 5, fontface = "bold", color = "black", inherit.aes = FALSE) + labs(x = NULL, y = y_label) + theme_classic() + theme( legend.position = "none", axis.text.x = element_text(size = 12, face = "bold", color = "black"), axis.text.y = element_text(size = 10, color = "black"), axis.title.y = element_text(size = 13, face = "bold", margin = margin(r = 10)), axis.line = element_line(linewidth = 0.8, color = "black"), axis.ticks = element_line(linewidth = 0.8, color = "black"), panel.grid.major.y = element_line(color = "grey90", linetype = "dashed") )}# 使用新函数出图p1_linear <- plot_academic_box_linear(df_ready, "Slope", "Slope")p2_linear <- plot_academic_box_linear(df_ready, "Elevation", "海拔 (m)")p3_linear <- plot_academic_box_linear(df_ready, "Qsep", "潜在土壤侵蚀")# 纯粹合并并添加默认标签,不强行嵌套 theme 修改combined_plot_linear <- (p1_linear | p2_linear | p3_linear) + plot_annotation( tag_levels = 'a', tag_prefix = '(', tag_suffix = ')' )# 打印查看(此时控制台会干干净净)print(combined_plot_linear)
推文若对各位有帮助记得点赞、关注、转发!
小编能力有限,在努力学习中...
希望投稿&合作请联系小编