引言:从“绿色革命”到“算法霸权”的权力转移
回顾现代农业史,谁掌握了核心的生产要素,谁就制定了产业规则。
20世纪中叶的“绿色革命”,核心要素是化肥和高产杂交品种,主导者是掌握了化工和杂交技术的科研巨头;
20世纪末的“生物技术革命”,核心要素是转基因技术和专利,主导者是掌握了特定基因片段和农化产品的跨国生物公司;
今天,我们正在步入“AI智能农业革命”,而这一轮的核心要素,是海量的多模态农业科研数据与超算能力。
在这个新纪元,传统的农业科研范式正在失效。过去,农学家提出假设,通过田间试验去验证;现在,AI大模型通过吞噬海量数据,直接在亿万级的参数空间中“涌现”出最优的基因组合与种植方案(数据驱动的Predictive Biology)。
这带来了一个致命的权力错位:最懂农业的科研机构没有算力,而拥有最强算力的AI公司不种地。 这种错位,为数据的非对等掠夺撕开了一道巨大的裂口。
第一章:解剖数据——为什么农业科研数据是AI时代的“液态黄金”?
要理解数据主权的丧失,必须先理解为什么科技巨头和资本对农业数据如此饥渴。农业数据具有极高的壁垒,它无法像互联网用户行为数据那样在短期内低成本生成。
1. 基因组的“数字孪生”:DSI(数字序列信息)
实体种子受物理限制,难以轻易转移。但在今天,通过高通量测序,一粒种子的所有奥秘被转化为几十GB的ATCG数字序列(DSI)。对于AI而言,这些序列就是代码。科技巨头可以通过算法,在海量的开源或半开源DSI数据中,挖掘出耐旱、抗病、高蛋白的“密码片段”。谁掌握了最多的DSI数据底座,谁就能训练出最精准的“数字育种器”。
2. 表型与环境的“高维矩阵”:G x E(基因与环境的互作)
农业科研最大的痛点在于“橘生淮南则为橘,生于淮北则为枳”。一个品种好不好,取决于基因(G)与环境(E)的复杂互作。 AI大模型要准确预测产量或指导种植,必须学习海量的多模态表型数据:这包括了某一块试验田连续20年的土壤重金属含量、微生物群落演替、逐小时的温湿度变化、作物的多光谱图像、根系发育的三维扫描等。这些数据是科研人员在极端恶劣的田间环境下,耗费数代人青春积累的“慢数据”。它们是AI公司在空调房里的服务器上永远无法凭空算出来的绝对壁垒。
3. 种植者经验的“算法化”
优秀的农场主和农技推广人员凭借经验判断病虫害和施肥时机。当他们使用各类“智慧农业APP”时,这些宝贵的隐性经验被转化为显性的数据标签(Data Labels),无偿喂养给了后端的AI视觉识别模型或决策大模型。
第二章:猎物与猎手——科研数据流失的“隐秘通道”
科研机构和产业链中下游企业的数据主权,并非在光天化日之下被直接抢走,而是通过一套极其精巧的商业模式和技术架构被悄然“虹吸”。
通道一:开源精神的“不对称套利”
基础科学界秉持“数据开源、造福全人类”的学术伦理。科研院所在发表顶级论文时,通常会被要求将底层基因组数据或大型表型数据集上传至公共数据库。 然而,AI时代打破了这种共享的平衡。拥有超级算力的商业机构,可以利用网络爬虫和API,瞬间将这些公共数据据为己有,用于训练自己的闭源商业模型。他们利用科研界无私奉献的“公地”,修筑起自己收费的“商业护城河”。 原始科研机构不仅得不到任何商业反哺,甚至在未来购买此类AI服务时,还要为自己的数据买单。
通道二:“特洛伊木马”式的软硬件下乡
某些科技公司以极低的价格,甚至免费向农业试验站、育种基地、大型农场提供智能气象站、无人机巡飞服务或SaaS农场管理软件。 这些工具的底层《用户许可协议》(EULA)往往极其冗长且晦涩,暗藏着“数据无偿让渡、永久使用、可转授权”的霸王条款。硬件只是采集器,真正的目的是将科研基地的核心微环境数据和品种表现数据,源源不断地抽水至科技公司的中央云服务器。
通道三:产学研合作中的“算力剥削”
在当前的农业AI交叉学科中,常见的合作模式是:农业科研院所提供几十年的育种积累数据,AI团队提供算法模型。 在缺乏严密主权界定的情况下,AI团队在合作结束后,往往带走了经过农业核心数据“喂养”后变得极其聪明的成熟大模型(甚至暗中保留了数据副本)。而农业科研团队得到的,仅仅是一个封装好的、针对特定任务的黑盒软件。农业专家出让了核心资产,却只换来了一个工具的使用权,彻底丧失了在算法层面的持续迭代能力。
第三章:丧失主权的代价——产业链底层的“内卷与悲歌”
农业科研数据主权的丧失,正在引发一系列深远的产业灾难。
1. 科研机构的“角色降级”与智力流失
如果最核心的数据要素被外部AI平台垄断,传统的农业科研院所将不可避免地被“管道化”和“空心化”。高薪的算法工程师在云端指点江山,而资深的农学家和育种专家将沦为替算法大厂收集数据、验证结果的“高级生物标注员”。这种学术地位和商业价值的双重贬损,将严重打击农业科研人才的积极性,导致基础研究团队的解体。
2. 知识产权(IP)的隐形被盗与壁垒倒置
在传统科研中,谁发现了抗病基因,谁就可以申请专利。但在AI时代,如果科研机构的原始数据流失到外部大模型中,AI可能比科研人员更早地“计算”出某个隐藏的优异基因通路,并由平台方抢先注册涵盖广泛的专利池(Patent Thickets)。 结果就是:科研人员用自己的数据,培养出了一个锁死自己未来研发路径的竞争对手。
3. 产业链利润的极度极化
在未来的智慧农业产业链中,利润将呈极端的“微笑曲线”。掌握数据和算法的云端平台将攫取90%以上的利润(通过提供精准育种服务、数字农资配方、产量期货预测);而承担着极高自然风险、投入重资产的育种基地、试验站和规模化农场,将只能赚取微薄的“苦力钱”。
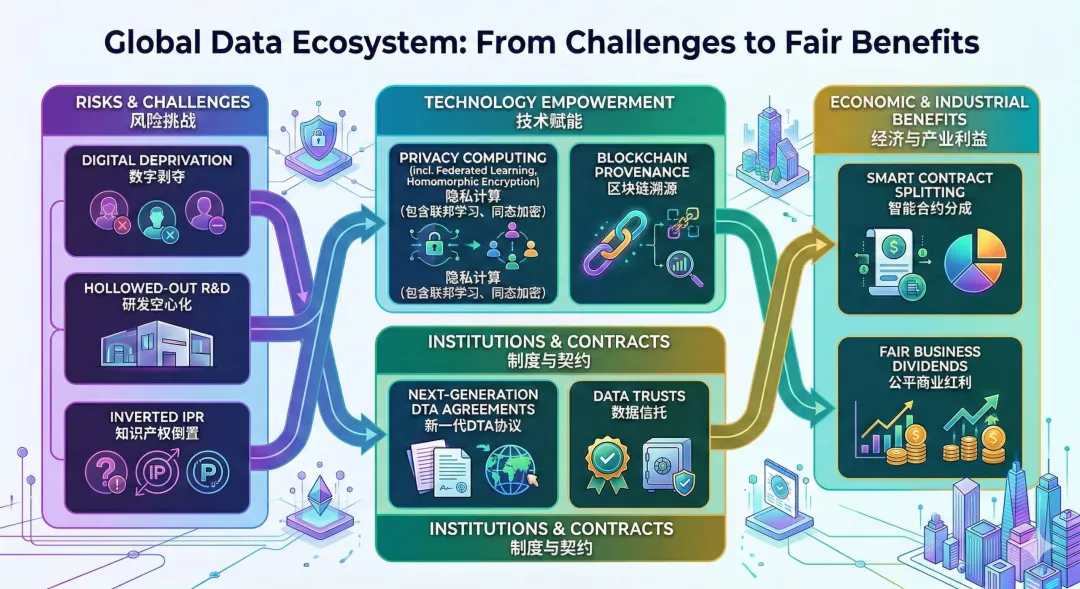
第四章:破局的基石——用“隐私计算”重塑技术护城河
面对算力霸权,仅仅依靠法律诉讼和拒绝合作是行不通的。必须用更先进的技术去对抗技术,用魔法打败魔法。核心理念是实现数据的“可用不可见,用途可控可计量”。
1. 联邦学习(Federated Learning):打破“数据孤岛”的终极武器
在多机构联合研发时,传统的做法是把数据归集到一起。而联邦学习允许各个试验站、育种公司将海量的表型数据和基因测序数据“留在本地服务器”。 AI模型作为一个“旅行者”,被派发到各个本地节点进行训练。模型在本地吸收了数据的规律后,只将“加密后的梯度参数(参数更新)”传回中心服务器进行汇总。意义: 这意味着科研机构可以在绝对不泄露一行原始基因代码和底稿数据的前提下,共同训练出一个极其强大的农业AI模型,真正做到“数据不出域,知识可共享”。
2. 多方安全计算(MPC)与同态加密(HE)
当科研团队需要利用外部的大型算力平台进行复杂的基因组关联分析(GWAS)时,可以采用同态加密技术。数据在上传前就被加密,算力平台只能在密文状态下进行计算,计算出的结果也是密文,只有掌握密钥的科研团队才能解密看到最终结果。这从物理底层彻底杜绝了平台方“偷窥”或留存原始数据的可能。
3. 区块链确权:为数据打上“数字指纹”
利用区块链技术,建立农业科研数据的分布式账本。每一份关键的种质资源测序结果、每一个突破性的表型数据集,在上云或共享前,都在区块链上进行哈希确权,生成唯一的数字指纹(NFT化)。一旦发现有商业模型非法使用了这些特征数据,即可通过逆向工程和区块链溯源进行精准追责,并在智能合约中设定未来的商业收益自动分配机制。
第五章:制度重构——构建AI时代的“数字农业契约”
技术的盾牌需要制度的城墙来支撑。科研院所和产业链参与者必须彻底更新陈旧的管理思维。
1. 缔结下一代“数据转移协议”(Next-Gen DTAs)
传统的《材料转移协议》(MTA)主要针对实体种子和样本。如今,必须建立针对数字序列(DSI)和大型数据集的《数据转移与计算协议》。 协议必须明确界定:
2. 建立“农业科研数据信托”(Ag-Data Trust)
单个科研团队面对科技巨头时,谈判地位极其脆弱。行业应当联合起来,建立由独立第三方(如学术委员会或行业联盟)运营的“数据信托”。 各个科研团队将数据“托管”给信托机构。信托机构作为数据集合的“受托人”,拥有极高的专业议价能力。由他们出面与AI企业谈判,用庞大的优质数据池换取最先进的算力支持、免费的SaaS服务,以及未来商业化后丰厚的算法分成。
3. 从“无条件开源”转向“有条件许可”
学术界应重新审视开源策略。对于关乎核心竞争力的本土特有种质资源数据和高精度环境表型数据,应采取类似“双轨制”的开源模式:对非盈利的纯学术研究免费开放;但对于任何将其用于商业AI模型训练的企业,必须强制实施“开源传染协议”(类似于GPL协议)——你用了我的数据,你的衍生模型也必须开源,或者向数据提供方支付“算法版税”。
结语:捍卫算法背后的“泥土权”
在AI狂飙突进的时代,农业科研的中心正在从试验田向超算中心转移。然而,再伟大的算法,也无法取代种子在土壤中经历风霜雨雪的真实生长;再庞大的算力,也必须建立在无数科研工作者扎实、艰辛的底层数据采集之上。
农业科研数据主权的保卫战,本质上是一场反抗技术霸权、捍卫劳动价值的产业重塑之战。
我们欢迎人工智能为农业带来效率的飞跃,但我们决不允许底层的数据贡献者在算法的黑盒中被剥削、被边缘化。唯有用最前沿的隐私计算筑起护城河,用最严密的制度协议重构利益分配机制,才能确保未来的智慧农业,不仅有云端的算法之光,更有属于科研机构和每一位耕耘者的尊严与回报。