做实证研究的同学都知道,传统计量方法做多了容易陷入瓶颈。
线性回归、固定效应、DID这些套路审稿人已经看腻了,想要突围就得在方法上有所创新。但机器学习又常被诟病"黑箱""不可解释",在经济学领域接受度有限。
今天介绍的这篇论文,来自刘媛等发表在《中国农村经济》的研究,展示了一种"可解释机器学习"的折中路径——既保留了机器学习的预测优势,又通过SHAP方法实现了结果的可解释,最终成功登顶顶刊。
这篇论文研究的是农民工进城落户意愿的影响因素。这个问题看似简单,实则复杂:
第一,影响因素太多。 个体特征、家庭情况、社会融入、公共服务、农村权益、地区差距……涉及4个维度37个变量,传统Logit模型很难处理这种高维数据。
第二,关系可能是非线性的。 年龄与落户意愿的关系可能是倒U型的,收入的影响可能存在门槛效应,传统线性设定容易遗漏这些复杂关系。
第三,异质性难以捕捉。 不同城镇规模、不同居留阶段的农民工,影响机制可能完全不同,传统交互项的做法既繁琐又容易过拟合。
第四,变量重要性难以比较。 传统回归的系数大小受量纲影响,无法直接回答"哪个因素最重要"这个问题,而这对政策制定恰恰很关键。
基于这些局限,作者选择了机器学习+SHAP可解释性的组合拳。
1. 模型选择:XGBoost
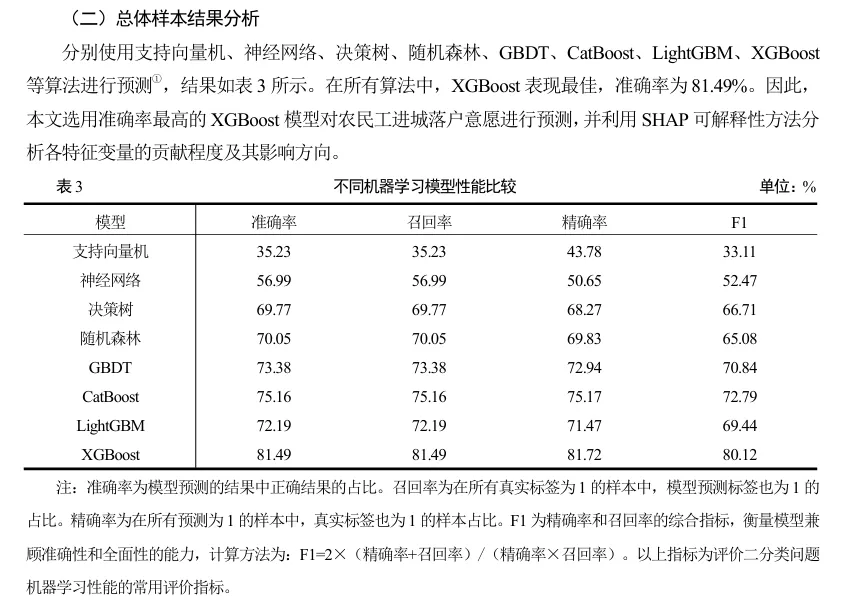
作者对比了8种机器学习算法:支持向量机、神经网络、决策树、随机森林、GBDT、CatBoost、LightGBM、XGBoost。最终选择XGBoost作为基准模型,原因很实在:
XGBoost的核心优势在于:通过梯度提升框架自动捕捉变量间的非线性关系和交互效应,不需要研究者预设函数形式;同时通过正则化控制过拟合,泛化能力强。
2. 可解释性:SHAP方法
机器学习模型准确率高,但"黑箱"问题是硬伤。审稿人经常会问:模型预测对了,但我们怎么知道为什么对?哪个因素起了决定性作用?
这篇论文引入了SHAP(SHapley Additive exPlanation)方法,这是2017年Lundberg和Lee提出的一种博弈论解释框架。核心思想是:把每个特征变量看作"参与者",模型预测结果看作"收益",通过计算每个参与者的边际贡献(Shapley值),来量化其对预测结果的贡献度。
SHAP值的计算公式:
这个公式的含义是:遍历所有可能的特征子集,计算加入第j个特征后模型预测值的变化,再按子集大小加权平均。最终得到的Shapley值满足四个重要性质:有效性、对称性、虚拟性和可加性,具有坚实的理论基础。
通过SHAP,作者实现了两个目标:
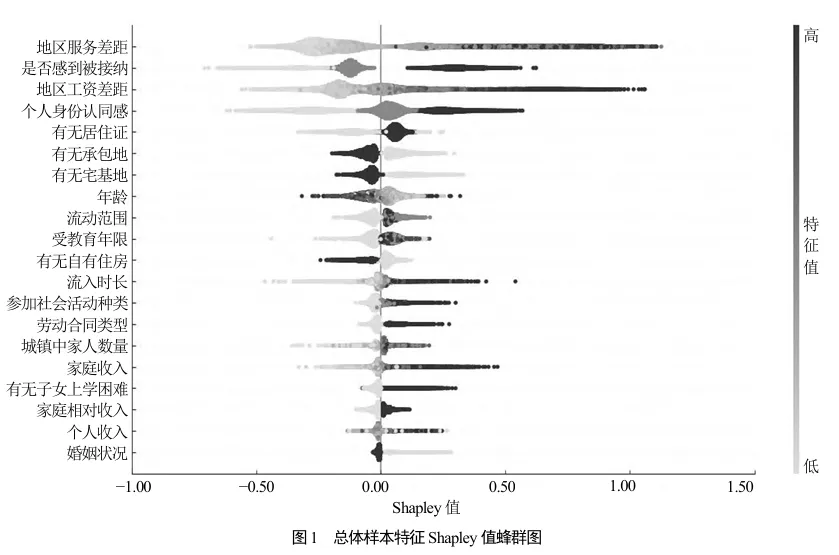
全局解释:计算每个特征变量的平均绝对Shapley值,得到重要性排序
局部解释:针对单个样本,看特定取值如何影响其落户意愿
这篇论文的实证部分设计得非常完整,从总体到异质、从静态到动态,形成了严密的证据链条。
1. 总体样本分析:识别核心影响因素
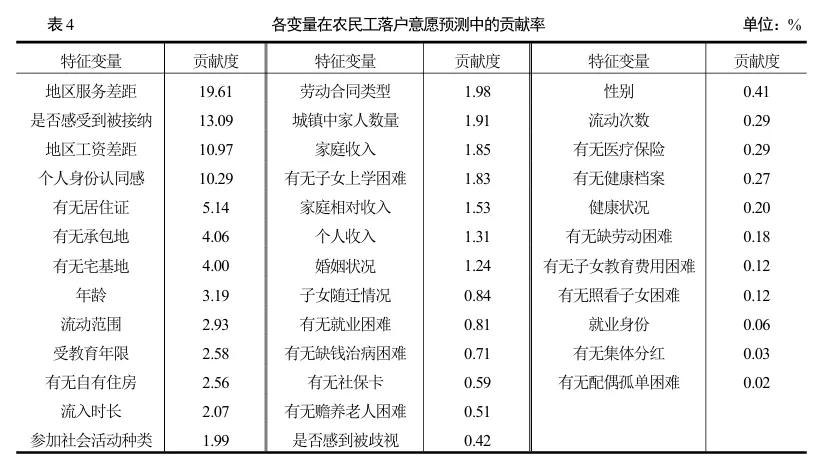
基于94,723个农民工样本,XGBoost模型达到81.49%的准确率。SHAP分析揭示了几个关键发现:
因素重要性排序(贡献率):
地区服务差距(19.61%):城乡公共服务差距越大,落户意愿越强
是否感到被接纳(13.09%):社会融入感是核心心理因素
地区工资差距(10.97%):经济因素重要,但不如公共服务
个人身份认同感(10.29%):心理认同是关键
有无居住证(5.14%):制度性障碍的体现
这个结果很有政策含义:农民工"不愿落户"不是因为农村权益太有吸引力(拉力只有8%),而是因为在城镇的社会融入困难(中间阻碍40%)和城镇公共服务吸引力不足(拉力中服务差距最重要)。
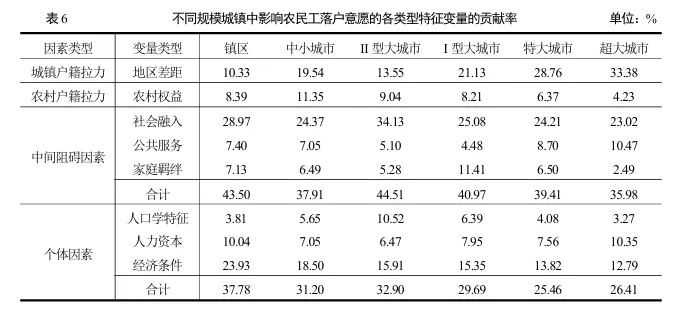
2. 分城镇规模异质性:因地制宜的证据
作者将城镇分为六类:镇区、中小城市、II型大城市、I型大城市、特大城市、超大城市,分别训练XGBoost模型(准确率均超87%)。发现规律性的趋势:
城镇户籍拉力:随城镇规模上升而增强(镇区10.33% → 超大城市33.38%)
农村户籍拉力:随城镇规模上升而下降(镇区8.39% → 超大城市4.23%)
中间阻碍因素:始终是最重要因素,但结构变化
这个异质性分析为分类施策提供了依据:小城市要重点促融入,大城市要重点降门槛。
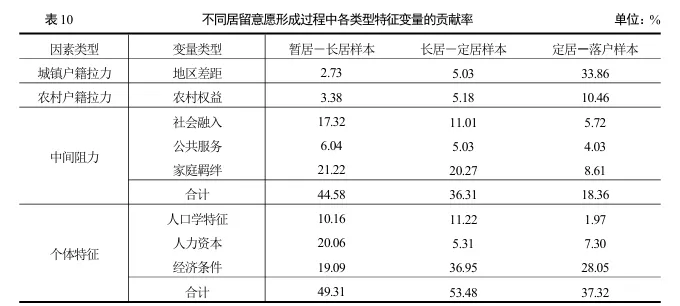
3. 渐进形成机制:从暂居到落户的动态过程
这是论文最精彩的部分。作者不满足于静态分析,而是把落户意愿看作渐进形成的过程:暂居 → 长居 → 定居 → 落户。
通过构建三组对比样本(暂居-长居、长居-定居、定居-落户),分别训练模型,识别不同阶段的转化因素:
关键发现: 城镇户籍拉力的影响呈阶梯式上升——在暂居-长居阶段仅2.73%,到定居-落户阶段跃升至33.86%。这说明公共服务差距是临门一脚的因素,决定了有定居意愿的人是否愿意真正落户。
这篇论文的成功,给想用机器学习发顶刊的同学几点启示:
第一,理论框架不能丢。 作者用推拉理论统领全篇,37个变量被组织成"城镇拉力-农村拉力-中间阻碍-个体因素"的四维框架,机器学习只是工具,理论逻辑才是灵魂。
第二,可解释性是关键。 纯黑箱的神经网络准确率可能更高,但SHAP的可视化(蜂群图、瀑布图)让审稿人能直观理解结果,这是被经济学界接受的前提。
第三,与传统方法对话。 论文在引言和文献综述中详细讨论了传统Logit模型的局限,说明为什么必须用机器学习,这种"比较优势"的论证很重要。
第四,政策含义要清晰。 机器学习的优势在于识别非线性关系和异质性,论文充分利用这一点,提出了分城镇规模、分居留阶段的差异化政策建议,体现了研究的现实价值。
刘媛等的这篇论文展示了一条方法论创新的可行路径:不抛弃经济学理论,但拥抱机器学习工具;不放弃可解释性要求,但借助SHAP实现透明化。在农业经济领域,这种方法特别适合分析个体决策行为(落户、消费、技术采纳等),既有顶刊发表的成功案例,又有广阔的应用空间。
方法论的窗口期往往很短,等大家都用烂了,审稿人又会回归传统。现在正是尝试的好时机。
参考文献: 刘媛,熊柴,蔡继明.农民工进城落户的意愿为什么不高?——基于可解释机器学习方法的分析[J].中国农村经济,2025(4):20-41.





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
