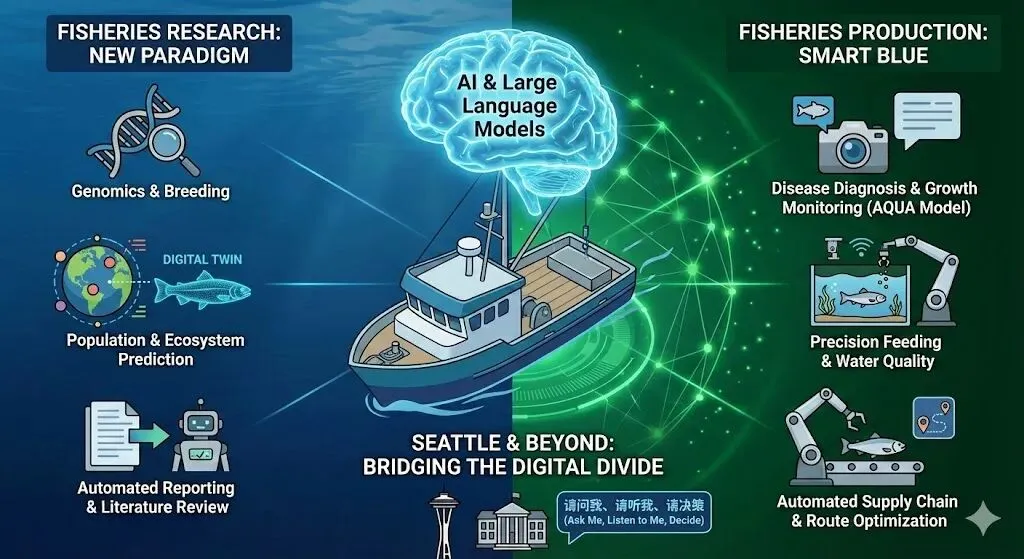
人工智能与大语言模型重塑渔业研究与生产的未来图景
1. 产业大变局:全球渔业的生存挑战与“渔业4.0”的全面觉醒
在过去的一个半世纪中,全球水产品供应支撑了数十亿人的蛋白质摄入与生计。然而,随着世界人口预计将从2025年的82亿增长至2050年的97亿,全球对高质量动物蛋白质的需求正呈指数级上升 。在这一宏观背景下,传统的渔业生态系统正面临着史无前例的重压。气候变化导致的海洋异常升温与酸化、长期的过度捕捞、水体污染以及沿海栖息地的不可逆破坏,已将众多野生鱼类种群推向崩溃的边缘 。海洋作为曾经被视为“取之不尽”的资源宝库,如今已显现出明确的生态极限 。
作为应对这一生存危机的核心方案,水产养殖业(Aquaculture)的战略地位被空前拔高。当前,水产养殖已不仅是野生捕捞的替代品,它正在成为未来全球海产品供应的绝对主体 。然而,水产养殖业自身的扩张同样步履维艰。在发达国家与地区,劳动力成本已占到总生产成本的40%至50%;同时,密集的养殖模式导致疾病频发、投喂效率低下、水质极难控制(特别是封闭的孵化场环境),这些结构性与操作性痛点严重制约了产业的规模化与可持续性 。
正是在这种供需矛盾与生态危机的双重倒逼下,基于人工智能(AI)、物联网(IoT)、大数据分析与自动化机器人的“渔业4.0”时代正式拉开帷幕。市场数据印证了这一技术转移的迅猛势头:全球可持续渔业与水产养殖人工智能市场规模在2024年约为6.29亿至6.39亿美元,预计在2032至2035年间,将以10.72%至15.4%的高复合年增长率(CAGR)飙升至14.2亿至20.7亿美元 。这一资本与技术的高密度融合,标志着AI在渔业领域的应用已经跨越了早期单一的“图像计数”与“统计预测”阶段。
特别是近年来,大语言模型(Large Language Models, LLMs)与多模态视觉-语言模型(VLMs)的爆发式演进,赋予了机器前所未有的语境理解与逻辑推理能力。当前的AI系统不仅能够进行深度的跨语种科学文献挖掘,还能与实时海洋传感器网络进行动态交互,甚至演化出“具身智能”(Embodied AI),直接将自然语言指令转化为水下机器人的控制代码 。本报告将全景式地深度剖析人工智能,尤其是大语言模型,如何重构渔业科学研究、精密水产养殖、捕捞生态管理以及供应链合规的底层逻辑,并揭示其技术演进轨迹与未来产业图景。
2. 渔业认知革命:大语言模型(LLMs)作为“领域大脑”与决策引擎
通用大语言模型(如GPT-4)在处理日常对话时表现优异,但面对海洋科学与渔业领域庞大、复杂且高度专业化的多维数据时,往往暴露出严重的局限性。这些局限性主要体现在:对垂直领域知识的颗粒度理解不足、容易在科学事实中产生“幻觉”(Hallucination),以及缺乏与实时环境观测数据交互的接口 。为了跨越这一鸿沟,全球顶尖科研机构正加速研发专属于海洋与渔业的垂直领域大模型。
2.1 垂直领域大模型的知识重构:从AQUA到范蠡1.0
在水产养殖领域,通用模型往往无法提供具备可操作性的具体指导。为此,研究人员开发了 「AQUA」,这是全球首个专为水产养殖与渔业量身定制的大语言模型,旨在为养殖户、研究人员、孵化场管理者及政策制定者提供智能咨询与运营决策支持 。
AQUA 的技术壁垒在于其独创的 「AQUADAPT(水产数据获取、处理与微调)」 代理框架。该框架摒弃了低效的人工标注,采用多智能体(Multi-agent)协同架构来生成和提炼高质量的合成数据 。具体而言,数据代理(Data Agent)利用先进工具从55,105份开源文献和网络资源中提取文本,并使用BM25算法进行深度清洗与相关性过滤;随后,专家代理(Expert Agent)主导构建了覆盖11个大类(包括生产系统与基础设施、遗传与育种生物技术、幼鱼与孵化场管理、营养与饲料技术、水质与环境控制、健康与疾病管理等)及60多个子类的水产知识分类体系 。在这一框架下,AQUA 模型能够精确回答如何优化投饵转化率(FCR)、如何制定针对性的疫苗接种协议,以及如何在循环水养殖系统(RAS)中调整溶解氧阈值等高度专业化的问题,其表现显著优于通用基座模型 。
与此同时,中国农业大学团队针对中国庞大的水产养殖市场,发布了首个渔业大模型——「“范蠡大模型1.0”」 。该模型不仅整合了中国27种主要水产养殖品种(涵盖鱼、虾、蟹、贝)的专业语料库,更实现了多模态数据(文本、图像、音视频)的深度融合 。范蠡大模型划分为“请问我”、“请听我”、“请看我”、“请决策”四个交互模块,不仅能回答养殖知识,还能直接对接物联网(IoT)设备进行水质调控决策,为中国水产养殖业向“无人化”、“数字化”的渔业4.0转型提供了核心基础设施 。
此外,考虑到偏远水产农场往往缺乏稳定的网络连接,算力向边缘端下沉成为必然趋势。「AQUA-1B」 作为一个仅有10亿参数的轻量级小型语言模型(SLM),专门针对树莓派(Raspberry Pi)和边缘TPU等低功耗设备进行了优化。它能够在完全离线的环境下,实时解析来自水质传感器的多维数据(如温度、pH值、浊度),并自主触发自动投喂程序或发出水质恶化预警 。
| 「模型名称」 | 「参数量级别」 | 「核心研发/发布机构」 | 「架构特征与核心技术创新」 | 「核心应用场景与解决的痛点」 |
|---|
| 「OceanGPT」 | | | 引入DoInstruct多智能体协同演化框架,整合机器控制代码 | 海洋学文献分析、放射性核素评估、水下ROV自主路径规划 |
| 「AQUA-7B」 | | | 基于AQUADAPT代理框架,结构化11大水产类目语料 | 孵化场精细化管理、FCR饲料优化分析、复杂疾病诊疗协议生成 |
| 「AQUA-1B」 | | | | 偏远农场离线水质预警、自主投喂系统触发、传感器数据逻辑推理 |
| 「范蠡 1.0」 | | | 深度融合文本与视觉多模态,内置中国本土27种水产生物语料 | 语音/视频交互诊断、基于视觉特征的非接触式鱼类体重高精度估算 |
| 「OceanAI」 | | | API函数调用(Function-calling)机制,无缝对接权威监测流 | 实时潮汐、海温动态解析、自动化海洋图表生成,根除AI知识幻觉 |
2.2 海洋科学探索与具身智能(Embodied AI)的交汇
大语言模型的潜力远不止于知识问答,其强大的逻辑推理能力正在被拓展至物理世界的控制中。「OceanGPT」 是海洋科学领域首个展现出极高专业认知与初步“具身智能”的大模型 。
面对海洋数据收集极其困难、专业语料稀缺的现状,OceanGPT 采用了一种名为 「DoInstruct」 的创新框架。在这个框架内,多个AI智能体(Agents)被设定为不同领域的专家(如海洋生物学家、气象学家、工程师),通过相互协作与辩论,自动生成海量、高质量的海洋科学指令数据,从而极大地降低了人工标注的成本 。在实际应用中,OceanGPT 展现出了惊人的学术素养,例如在分析海洋放射性核素污染时,能够输出涵盖实验设计、数据分析、风险评估到处置指南的系统性报告 。
更为深远的突破在于,研究人员将水下机器人(ROV)的机器指令代码整合到了 OceanGPT 的训练集中。这赋予了模型直接将自然语言转化为操作指令的能力 。科学家只需输入自然语言需求,OceanGPT 便能生成精准的控制台命令和导航代码(例如控制ROV在海底执行双螺旋扫描路径),这标志着大模型在海洋工程领域的应用迈出了从“数字空间”到“物理执行”的关键一步 。
2.3 终结“AI幻觉”:OceanAI与动态数据的无缝桥接
在渔业环境监测与气候研究中,数据的绝对准确性是不可逾越的红线。传统的对话式AI由于其知识库的静态属性,往往会生成过时的甚至虚构的数据支撑,这在严肃的科学研究中是灾难性的 。
为彻底解决这一问题,美国国家海洋和大气管理局(NOAA)联合研究团队推出了 「OceanAI」 对话平台 。与传统的静态权重模型不同,OceanAI 内置了强大的**函数调用(Function-calling)**与模块化数据管道钩子 。当用户提出复杂的时空查询(例如“比较2022年波士顿与弗吉尼亚礁的平均海平面变化率”)时,OceanAI 不会依赖其内部记忆进行猜测,而是将查询动态解析为后端API调用指令,直接从NOAA的高频传感器网络(如CO-OPS潮汐计网络、CORA再分析数据集)中提取实时的NetCDF、JSON或CSV数据 。随后,模型会在云端对这些复杂数据进行即时计算,并生成带有完整元数据、时间戳、数据处理步骤说明以及高分辨率可视化图表的响应 。这种架构不仅消除了AI幻觉,确保了科学结论的可重复性与透明度,还极大地降低了非专业用户获取和分析复杂海洋环境数据的技术门槛 。
2.4 文献挖掘与跨语言政策合规的自动化
渔业科学不仅涉及自然科学,还深嵌于复杂的社会经济与政策管理框架中。在这一维度,大语言模型展现出了卓越的文本挖掘与合规核查能力。
在全球视野下,海洋研究成果散落于多种语言的文献中。通过应用检索增强生成(RAG)和跨语言抽象摘要技术,先进的LLM能够突破高资源语言(如英语)与低资源语言之间的壁垒,自动梳理和生成跨语言的海洋环境科学综述,从而大大加速了全球科研成果的同步与知识转移 。
在渔业政策合规与社区管理(CBFM)层面,监管机构常常需要处理大量来自小型渔民的非结构化、口语化的叙述报告。一项基于 Merak-7B 模型的实证研究表明,经过领域微调的LLM能够以91%的极高准确率,从这些模糊的渔民日记和访谈中自动提取结构化核心指标(包括捕获日期、具体经纬度、鱼类品种、重量、售价及买家信息) 。
此外,随着“监管科技”(RegTech)的兴起,LLM被部署于连续的合规检查中。系统能够自动读取远洋渔船的日志、轨迹以及供应链采购合同,并与所在海域的法律法规、海洋保护区(MPA)政策进行实时对比,敏锐地识别出是否存在“挂靠避税旗舰”、非法抛弃兼捕物或劳工违规等行为。这种智能审计不仅大幅降低了管理当局的执法成本,更是防范非法、未报告和无管制(IUU)捕捞的核心利器 。
3. 跨越水下感知的物理极限:计算机视觉(CV)与多模态大模型的演进
如果大语言模型是现代渔业的“中枢大脑”,那么计算机视觉与多模态模型则是深入水底的“全天候神经网络”。
3.1 突破环境噪音的鱼类检测与轻量化架构
在水下执行视觉感知任务,面临着陆地环境中难以想象的物理挑战。光线在水中的指数级衰减导致了严重的颜色失真与对比度下降;水体浑浊、悬浮物(如残饵和粪便)的遮挡以及鱼群在高密度状态下的相互重叠,使得传统的视觉算法几乎完全失效 。
为了攻克这些难题,深度学习架构正在进行深刻的重构。例如,「DeepFishNET+」 提出了一种混合解决方案,首先通过水下图像增强模块进行物理畸变校正,随后并行使用全局CNN特征流(ResNet50)和局部Transformer流进行交叉注意力特征融合,最终在极度复杂的背景下实现了高达98.28%的物种分类精度和92.74%的目标检测精度 。
然而,高精度的庞大模型往往难以部署在算力有限、依靠电池供电的水下巡检无人机或边缘浮标上。针对鱼类在游动过程中身体不断发生非刚性形变的特性,研究人员设计了 「DeformableFishNet」 。该架构创造性地引入了可变形卷积网络(Deformable Convolutions)和高效的全局坐标注意力模块(EGCA)。在保持96.3%平均精度(mAP)的前提下,将模型参数量急剧压缩至170万,这使得计算机视觉技术能够真正走向低成本、广覆盖的商业化部署 。
在更为密集的循环水养殖系统(RAS)中,由于水质极度浑浊且鱼群密集,获取高质量的人工标注训练数据极其昂贵且带有主观偏差。学术界为此开辟了“虚拟数据融合”的新路径:通过计算机引擎模拟逼真的3D鱼群行为,生成大量自动标注的虚拟图像,并以90:10的比例与真实水下图像混合训练模型。这种创新的训练范式不仅使平均精度跃升至91.8%,更将模型训练的资金与时间成本缩减了七倍之多,为养殖场快速定制专属识别模型铺平了道路 。
3.2 疾病智能诊断与非接触式测量
在水产养殖中,鱼类病害(如白斑病、鳃霉病、寄生虫感染等)一旦爆发,往往会导致毁灭性的经济损失。传统的病理学诊断依赖人工取样、组织解剖和显微镜观察,这种滞后的流程不仅对鱼体造成巨大压力,也使得干预措施往往错失最佳时机 。
如今,计算机视觉正在将疾病诊断前置到“日常游动”中。高清摄像头与AI算法相结合,能够非侵入式地实时捕捉鱼体表面的细微变色、溃疡斑块或是异常的游动轨迹(如擦边游动、螺旋翻滚等应激行为) 。在结合近红外光谱成像等技术后,系统甚至能在弱光、高浊度水体中,穿透表面检测鱼类皮下的组织损伤与寄生虫寄生情况 。
此外,非接触式的生理指标测量正成为标准配置。范蠡大模型通过提取二维图像中的形状、轮廓和纹理等多维度特征,能够实时、精准地推算出池塘内鱼群的整体重量分布 。这种无压力的数据采集,为养殖户提供了极其精确的生长曲线,是进行后续投饵量计算和水质环境控制的核心数据支撑 。
3.3 迈向零样本学习:多模态基础模型(VLM)与 AquaticCLIP
传统的计算机视觉模型是“封闭词汇”(Closed-vocabulary)的,即模型在训练阶段见过多少种鱼或疾病,在应用时就只能识别这几种。一旦引入新物种或遇到未知病变,模型必须重新收集数据并进行漫长的重新训练 。
**视觉-语言模型(VLMs / MLLMs)的引入,彻底打破了这一桎梏。以 「AquaticCLIP」 为代表的多模态基础模型,利用自然语言处理与视觉识别的对齐技术(Contrastive Language-Image Pretraining),在超过200万对水下图像与丰富的文本描述(广泛采集于Netflix、国家地理及各种海洋纪录片)中进行了无监督学习 。这使得模型具备了强大的零样本(Zero-shot)**推理能力:即使面对从未标注过的新型海洋生物,只要人类用自然语言描述其特征,模型就能在图像中精准地将其分割、分类并计数 。
为了进一步测试并提升大模型在海洋生物学领域的精细推理能力,研究人员构建了 「FishNet++」 等大规模多模态基准数据集。该数据集包含了对数十万个鱼体关键部位(如眼睛、各个背鳍、嘴、尾鳍分叉等)的精准形态学注释及长文本描述 。在这一数据的滋养下,未来的多模态大模型将不再仅仅是框出一个“鱼”的边界框,而是能像一位从业三十年的顶级海洋生物学家一样,通过视觉识别出鱼类尾鳍的微小分叉变化,结合自身内置的文本知识库,推断出该物种的迁徙路线、当前年龄段以及对特定病原体的易感性,从而提供具有深度因果逻辑的分析报告 。
4. 智慧水产养殖(Aquaculture):从“靠天吃饭”到数据驱动的工业化生态
面对野生渔业资源的枯竭,水产养殖是全球蛋白质供给的绝对主力。然而,在这个高度依赖经验的行业中,人工决策的局限性正导致巨大的资源浪费与环境负荷。AI技术的全面渗透,正在将传统的鱼塘转化为由算法调度的精密生化工厂 。
4.4 算法驱动的精密投喂控制系统
在商业水产养殖中,饲料成本占据了总运营支出的60%至70% 。这形成了一个棘手的两难境地:投喂不足会导致鱼群生长停滞、相互残杀;而过度投喂不仅浪费了由昂贵鱼粉制成的饲料,更致命的是,未被食用的残饵和代谢粪便会在水底大量腐败,消耗溶解氧并释放高毒性的氨氮,进而引发病害的爆发与鱼群的规模性死亡 。
2026年,结合物联网与AI的智能投喂系统已经成为行业的标配。这些系统彻底摒弃了定时定量的僵化模式,转向基于鱼群实时生理与行为状态的“按需投喂”。除了使用计算机视觉分析鱼群在水面抢食时的“沸腾度”(Feeding Frenzy)外,更为前沿的技术开始引入「水下声学传感」。例如,以色列国家海水养殖中心的研究发现,海洋环境并非寂静无声,鱼类在咀嚼特定饲料时会发出独特的声学信号 。通过部署水下麦克风并利用深度学习算法破译这些“进食声谱”,系统能够极其灵敏地判断鱼群当前的饥饿程度、饱腹状态以及可能的健康应激反应 。一旦算法判定鱼群进食意愿下降或已达到饱腹阈值,物联网终端会瞬间切断自动投料机(如Umitron Cell等设备) 。据统计,这种智能闭环系统能够将饲料转化率(FCR)优化至极限,不仅将生长周期内的投喂效率提升15%至22%,更从源头上截断了水体污染的恶性循环 。
4.5 数字孪生与循环水养殖系统(RAS)的自动化预判
循环水养殖系统(Recirculating Aquaculture Systems, RAS)被公认为现代水产养殖的未来终极形态。它通过物理过滤与生物反应器在室内实现水资源的无限循环利用,摆脱了对自然水域的依赖。然而,RAS是一个极其脆弱的动态平衡系统,任何水质参数(如pH值、硝酸盐、溶解氧)的微小偏离,都可能在数小时内导致全军覆没。
如今,人工智能正在为RAS构建精确的**数字孪生(Digital Twin)**模型 。AI利用强化学习(Reinforcement Learning)和长短期记忆网络(LSTM),实时吸收传感器传回的海量物理化学数据,并结合当前的投喂量和鱼群总生物量模型,前瞻性地模拟系统在未来几个小时甚至几天的运转状态 。当预测模型侦测到潜在的环境危机(如预测夜间可能出现溶解氧低谷)时,系统不再仅仅发出警报,而是直接过渡到指令干预层面:自主调节制氧机的曝气率、启动水泵加速循环,或自动投放碳酸氢盐等化学药剂以稳定pH值 。这种将预测与控制闭环相连的智能架构,极大地降低了人工管理的风险,预计可将RAS系统的综合生产效率提升40%至55% 。
4.6 基因组学革命:AI重塑高价值物种的选育路径
水产养殖的成功在很大程度上取决于种质资源的优劣。在过去,培育一种具备抗病性或耐极端温度的新品系,需要耗费数年甚至十数年的时间进行漫长且不确定的表型筛选。
当前,**基于AI的基因组选择(Genomic Selection, GS)**技术与CRISPR基因编辑的结合,正在掀起一场“定制化生命”的革命 。通过高通量测序技术,科学家能够获取数百万计的单核苷酸多态性(SNPs)及多组学数据(转录组学、蛋白质组学) 。面对这种超高维度、存在复杂非线性上位效应的数据,传统的统计模型无能为力。而先进的机器学习与深度学习模型能够迅速解码基因标记与复杂经济性状(如生长率、特定病原体抗性)之间的内在密码 。
在一项针对全球重要经济物种牡蛎的前沿研究中,研究人员利用AI模型精准识别了控制牡蛎耐寒性与抗病性的核心SNP标记组。通过AI引导的标记辅助选择(MAS),研究人员完全绕过了漫长的实地繁育观察,直接在分子层面预测出后代的生存概率。在对照试验中,经由机器学习模型筛选出的牡蛎品系,在面临冬季严寒应激时,其死亡率大幅下降了30%,同时整体生长速率提升了25% 。AI模型甚至在预测个体的生长与存活特征方面达到了惊人的92.4%准确率 。这种数据驱动的分子级精准育种,不仅为应对气候变化(海水升温、酸化)提供了强大的技术武器,更将水产育种带入了一个高效、定向的工业化设计时代。
5. 捕捞渔业与宏观海洋生态:在数据迷雾中寻找可持续的平衡点
尽管水产养殖发展迅猛,但全球野生捕捞渔业依然是维系海洋文化与生计的基石。在资源日益枯竭的今天,如何利用AI技术在浩瀚无垠且变幻莫测的海洋中实施精准捕捞与生态保护,成为了宏观资源管理的核心命题。
5.1 种群动态的深度预测与微生境时空测绘
野生鱼类的迁徙模式和种群丰度受到洋流、温度、盐度及厄尔尼诺等复杂宏观气象因素的综合影响。传统的资源评估往往依赖有限的拖网抽样和简单的线性回归,导致捕捞配额(TAC)的制定充满滞后性与不确定性。
为了提供更精确的决策支持,复杂的时空深度学习模型开始大显身手。例如,一项针对冰岛复杂水域的创新应用,开发了名为CATCH的卷积长短期记忆网络(ConvLSTM)模型 。该模型将冰岛远洋船队的海量历史捕获数据,与多维度的海洋学底层参数(包括水深、底层水温、盐度、溶解氧浓度)进行高频融合,能够高精度地预测未来一段时间内鳕鱼、黑线鳕及格陵兰大比目鱼等高价值物种的概率密度分布。这不仅为船队规划提供了导航,更让政府机构能够基于实时的资源预测进行灵活的配额干预,从根本上杜绝盲目的过度捕捞 。
在近岸和内陆淡水生态系统(如濒危物种的恢复)中,人工智能的宏观观测能力同样不可或缺。「微软公司(Microsoft)与NOAA西北水产科学中心」展开了一项极具前瞻性的合作项目 。微软通过其“AI for Good”实验室投入了价值500万美元的Azure云计算资源,联合开发了一款专门针对哥伦比亚河流域(Columbia River Basin)的人工智能栖息地映射模型 。利用海量的超高分辨率卫星图像,AI能够并行处理以往需要耗费大量人工实地勘测数月才能完成的地理分析,精确预测随季节和气候变化的河流流量,将如何扩大或缩小沿岸的濒危鲑鱼(Salmon)繁殖微生境 。这项技术使得水资源管理者能够首次精确量化“购买额外水权以增加水流”究竟能为鲑鱼挽回多少平方公里的生存空间,从而确保每一分生态保护资金都能获得最大的“投资回报率”(ROI),实现了生态恢复与经济支出的最佳平衡 。
5.2 航线寻优、降本增效与捕捞作业的自动化革新
商业捕捞是一项极度消耗化石能源的高风险产业。长距离的航行与搜寻不仅产生了巨额的燃油成本,也加剧了海洋行业的碳足迹。
目前,**基于AI的航路优化与决策支持系统(FRODSS)**正在改变这一现状 。这些系统综合卫星遥感数据、洋流速度、风向及叶绿素分布,结合AI对鱼群聚集趋势的预测,为拖网或围网渔船规划出收益最大化且最省油的航行轨迹。实测数据显示,配备AI优化路线的船只不仅大幅提升了捕获率,还能有效降低15%至25%的燃油消耗,在应对国际海事组织(IMO)日益严格的净零排放合规要求方面展现出极大的商业价值 。
在渔获物的处理端,初创公司正利用计算机视觉和工业机器人推动甲板上的自动化革命。例如位于西雅图等科技枢纽的企业 Shinkei Systems,推出了一套完全自动化的渔获处理平台。众所周知,野生鱼类在被捕捞出水后,如果经历长时间的挣扎与窒息,其体内会大量积聚乳酸及应激激素,这不仅会导致肉质酸度上升、加速细菌滋生,更会极大缩短海鲜的保质期 。Shinkei系统的AI摄像头能在鱼类离开水面的瞬间精准扫描其骨骼与大脑结构,机械臂在随后的6秒内自动实施源自日本工匠的高级“活缔”(Ike Jime)技术——瞬间破坏鱼的大脑并完成放血 。这一工业化流程避免了鱼类的应激反应,从生化源头上锁住了能量与鲜度,不仅将产品的保质期延长了三倍,更让普通的商业渔获达到了米其林餐厅级别的顶级食材标准,极大提升了全产业链的附加值 。
5.3 电子监控系统(EM)与濒危物种的智能保护网
对于高度管制的捕捞业而言,合规与监管是核心难题。为了防止非法丢弃兼捕物(如不小心捕获的海龟或非目标鱼种),政府通常要求派遣人类观察员随船出海,但这面临着极高的人工成本与有限的覆盖率(通常低于10%) 。
基于计算机视觉的**电子监控系统(Electronic Monitoring, EM)**提供了一种完美的替代方案。一艘远洋渔船在一个航次中可能会产生超过2TB的高清监控视频,依靠人工审核这些录像既昂贵又容易疲劳 。得益于NOAA的SBIR计划资助,像Ai.Fish这样的企业开发了名为Catchvision的机器学习平台。该系统能够以前所未有的速度自动扫描海量视频,精准计数捕获的鱼类,并识别出视频帧中一闪而过的受保护物种,为人类审查员节省了高达80%的时间成本,使得以极低成本实现100%的船队合规监控成为可能 。
在广袤的海洋上保护濒危巨兽方面,AI同样大有可为。NOAA的科学家正利用基于卫星图像的视觉AI(如GAIA系统)在茫茫极地海冰中自动搜寻和统计海豹及北极熊的分布 。在声学监测领域,NOAA与科技公司BLUEiQ合作,在深海部署了搭载边缘计算芯片的超低功耗声学传感器(OpenEar) 。这些设备摒弃了对云端网络连接的依赖,直接在海底本地利用AI算法过滤掉海浪与船舶的工业噪音,精准捕捉极度濒危的北大西洋露脊鲸(现存不到380头)的微弱叫声。这一技术让资源管理者能够以极低的成本实时掌握濒危鲸类的游动轨迹,为商船发布实时的避撞预警,或动态划定临时禁渔区 。
6. 重塑渔业供应链:大语言模型驱动的透明度与信任机制
渔业是全球化程度最深、供应链最为绵长且脆弱的产业之一。一条在北欧捕捞的三文鱼,可能需要在亚洲进行切片加工,最终端上北美的餐桌。在这一漫长的冷链运输中,任何一环的延误或温度失控都会导致海产品变质腐败;同时,复杂的跨国海关文书与环保认证,往往耗费极高的人力成本 。
「大语言模型与合规AI正成为打破这一物流壁垒的关键。」 包括Certivo、Fishtail AI在内的一批新兴科技企业,正致力于利用LLM与数据分析重构供应链信任 。一方面,LLM能够瞬间解析多达数百页的跨国采购合同与海关进口政策(如应对NOAA的海鲜进口监测计划SIMP),自动提取合规条款并校验供货商的资质,彻底取代繁琐的人工核对,从源头封堵非法、未报告和无管制(IUU)渔获物流入合法市场的可能 。 另一方面,结合区块链的不可篡改特性,AI能够将渔获的捕捞GPS定位、渔船引擎的碳排放数据、冷链货车的实时温度传感器记录无缝整合。Fishtail AI等平台更是利用这些经过AI审计的低碳足迹与透明合规数据,为符合可持续发展标准的捕捞企业提供快速的供应链融资(Supply Chain Financing)奖励。这种“数据+金融”的闭环激励机制,正实质性地推动整个产业向绿色、透明化方向转型 。
7. 迈向深蓝:挑战、治理与技术展望
尽管AI、LLM与CV为渔业科学与生产勾勒出了无比广阔的蓝图,但从实验室的理想模型走向复杂多变的真实海洋环境中,依然横亘着诸多挑战。
首先是「严峻的“数据孤岛”与跨区域的“环境漂移(Domain Shift)”问题」 。海洋数据高度分散在各国的研究机构与私营企业手中,缺乏统一的数据共享协议。此外,一个在清澈的挪威峡湾训练出来的高精度视觉检测模型,一旦部署到水质浑浊、光照条件不同的亚洲近海网箱,往往会遭遇精度断崖式下跌的问题 。因此,建立如FathomNet这样的全球开源、标准化、包含稀有物种注释的多模态图像数据库,以及研发具备更强领域自适应能力的算法,是突破技术瓶颈的核心基础设施工程 。
其次是「模型不确定性与政策决策的博弈」。尽管AI预测模型(如栖息地评估、种群推演)表现优异,但自然生态系统具有混沌的非线性特征。若管理者未能科学评估模型输出的“置信度(Uncertainty)”区间便贸然制定配额,可能引发不可逆的生态灾难 。因此,可解释性AI(XAI)的研发,以及将AI与传统机械生态动力学模型深度融合,才是未来科学决策的正途。
最后是「技术采用的“数字鸿沟”与结构性不平等」 。动辄耗资数百万美元的算力集群与深海高端传感器,几乎被全球性的农业寡头与发达国家垄断。对于支撑着全球过半产能、却资金匮乏的发展中国家小农户与小型个体渔民而言,他们极易在这场“渔业4.0”的技术革命中被彻底边缘化 。为此,全球的研究机构与公益组织正致力于“AI下沉”。例如,世界渔业中心(WorldFish)推出的SmartCatch项目荣获了联合国的嘉奖,该项目旨在利用普通的低端智能手机,在无网络连接的偏远水域,通过轻量级AI帮助手工渔民快速识别渔获物种并估算重量 。唯有推动诸如AQUA-1B边缘大模型与SmartCatch这类的低门槛、普惠性技术方案,才能确保科技进步真正惠及全人类。
8. 结语
在人工智能与大语言模型突飞猛进的今天,AI已不再仅仅是提升工作效率的边缘工具,它正在确立为开启人类认知海洋、重塑生物生产全链条的核心“基础设施”。
从计算中心里通过多组学基因模型推演出的抗寒抗病超级牡蛎,到循环水养殖池中通过敏锐聆听鱼类咀嚼声而实现毫秒级响应的无人化投喂;从深海利用大语言模型自动生成复杂指令并指挥无人潜航器执行探索,到万米高空中利用计算机视觉分析卫星图像以守护哥伦比亚河流域的鲑鱼栖息地——智能化的浪潮正在席卷渔业生产与生态保护的每一个细微切面。
对于身处这一伟大变革时代的科研人员、企业管理者与政策制定者而言,这既是一场充满商业机遇的技术狂欢,更是一场关乎如何平衡人类生存发展需求与地球海洋生态底线的宏大博弈。未来的渔业图景必将依赖深度交叉学科的融合:将计算机科学家的底层算法逻辑、水产专家的生物学积淀以及政策学者的可持续视野,共同汇聚到如 OceanGPT 或 AQUA 这类具有高度上下文理解能力的超级智能体中。在这个由算力、数据与智能共振驱动的“新大航海时代”,谁能够率先构建出安全、可信且普惠的“智慧渔业生态系统”,谁就能在守护蓝色海洋的纯净与生机的同时,稳稳端住全球的“海鲜饭碗”。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
