农业 GIS 数据源包括:地块文本档案、卫星 / 无人机影像、土壤墒情传感器数据、GIS 矢量 / 栅格数据、农业种植知识库等;最终输出为智能问答、相似地块推荐、墒情分析建议等。二、第一步:Embedding 模型选择(农业 GIS 定制化)
核心原则:优先选开源、适配农业领域、支持多模态(文本 + 空间特征)的模型,避免闭源模型的成本和隐私问题。
1. 文本类 Embedding(农业 GIS 文档 / 问答)
| | | |
|---|
| Sentence-BERT(all-MiniLM-L6-v2) | | |
| 文心一言农业版 Embedding / 智谱 AI 农业 Embedding | | |
| | 支持地理空间术语(经纬度、地块 ID、栅格分辨率) | 带空间属性的文本(如 “东经 114° 北纬 34° 小麦地块墒情”) |
部署方式:
- 轻量部署:用
Hugging Face Transformers加载模型,本地 / 服务器运行(推荐 GPU:NVIDIA T4/A10)。
from sentence_transformers import SentenceTransformerimport torch# 加载模型(农业微调版Sentence-BERT,可替换为GeoBERT)model = SentenceTransformer('all-MiniLM-L6-v2')# 若有农业领域微调权重,加载:model.load_state_dict(torch.load("agri_gis_embedding.pth"))# 农业GIS文本示例:带空间属性的地块描述agri_texts = [ "东经114.32°北纬34.56°郑州小麦地块,土壤墒情15%,海拔85米", "2025年黄河流域玉米种植区卫星影像,分辨率10米,土壤有机质含量2.8%"]# 生成向量(输出为768维稠密向量,符合向量数据库输入要求)embeddings = model.encode(agri_texts, convert_to_tensor=False)print(f"向量维度:{embeddings.shape}") # 输出 (2, 768)print(f"第一条文本向量:{embeddings[0][:5]}") # 打印前5维,验证生成结果
2. 多模态 Embedding(卫星影像 / 栅格数据 + 文本)
农业 GIS 核心需求是 “文找图、图找图”(如用文字找对应卫星影像),推荐以下模型:
代码示例(卫星影像 Embedding):
from PIL import Imageimport clipimport torch# 加载CLIP模型(农业微调版替换为agri_clip.pt)device = "cuda" if torch.cuda.is_available() else "cpu"model, preprocess = clip.load("ViT-B/32", device=device)# 农业卫星影像预处理(模拟加载黄河流域小麦地块影像)image = preprocess(Image.open("wheat_field_satellite.jpg")).unsqueeze(0).to(device)# 文本查询(如“黄河流域干旱小麦地块”)text = clip.tokenize(["黄河流域干旱小麦地块"]).to(device)# 生成影像和文本的向量with torch.no_grad(): image_features = model.encode_image(image) # 影像向量 text_features = model.encode_text(text) # 文本向量 # 归一化(向量数据库检索前必须做) image_features /= image_features.norm(dim=-1, keepdim=True) text_features /= text_features.norm(dim=-1, keepdim=True)# 计算相似度(验证跨模态匹配效果)similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)print(f"文图匹配相似度:{similarity.item():.2f}")
3. 空间特征 Embedding(GIS 矢量 / 栅格数据)
针对 GIS 原生数据(如 Shapefile 矢量地块、TIFF 栅格墒情图),需先提取空间特征再生成向量:
- 特征提取工具:GDAL(栅格 / 矢量解析)、PyQGIS(GIS 特征计算)、GeoPandas(空间属性处理)。
- 用 GDAL 读取栅格数据,提取波段值、分辨率、空间范围;
- 用 GeoPandas 读取矢量地块,提取面积、周长、经纬度中心、土壤类型编码;
- 将空间特征拼接为一维数组,输入
MLP或Sentence-BERT生成向量。
三、第二步:向量数据库部署(农业 GIS 适配版)
农业 GIS 场景需兼顾空间属性过滤 + 向量相似性检索,优先选支持 GIS 扩展的向量数据库,以下是落地级部署方案:
1. 推荐数据库选型(按场景匹配)
2. 落地部署步骤(以 PGVector+PostGIS 为例,最易上手)
步骤 1:环境部署(Docker 一键启动)
# 拉取包含PGVector+PostGIS的镜像docker pull ankane/pgvector:pg16-postgis3# 启动容器(设置密码、端口,映射数据卷)docker run -d \ --name agri_gis_vector_db \ -p 5432:5432 \ -e POSTGRES_PASSWORD=agri123456 \ -e POSTGRES_DB=agri_gis_db \ -v /data/agri_vector:/var/lib/postgresql/data \ ankane/pgvector:pg16-postgis3
-- 连接数据库后执行-- 启用PostGIS(空间处理)和PGVector(向量处理)CREATE EXTENSION IF NOT EXISTS postgis;CREATE EXTENSION IF NOT EXISTS vector;-- 创建农业GIS向量表(存储地块向量+空间属性)CREATE TABLE agri_plot_vectors ( plot_id SERIAL PRIMARY KEY, -- 地块唯一ID plot_name VARCHAR(100), -- 地块名称 geom GEOMETRY(Point, 4326), -- 地块中心点(WGS84坐标系) embedding vector(768), -- 768维Embedding向量 soil_moisture FLOAT, -- 土壤墒情(%) crop_type VARCHAR(50) -- 作物类型);-- 创建向量索引(加速相似性检索)CREATE INDEX ON agri_plot_vectors USING hnsw (embedding vector_cosine_ops);-- 创建空间索引(加速地理范围过滤)CREATE INDEX ON agri_plot_vectors USING gist (geom);
步骤 3:Python 接入数据库(插入 / 检索向量)import psycopg2from psycopg2.extras import RealDictCursorimport numpy as npfrom sentence_transformers import SentenceTransformer# 1. 初始化模型和数据库连接model = SentenceTransformer('all-MiniLM-L6-v2')conn = psycopg2.connect( dbname="agri_gis_db", user="postgres", password="agri123456", host="localhost", port="5432")cursor = conn.cursor(cursor_factory=RealDictCursor)# 2. 插入农业地块向量数据def insert_plot_vector(plot_name, lon, lat, soil_moisture, crop_type, text_desc): # 生成向量 embedding = model.encode(text_desc).tolist() # 插入SQL(包含空间点和向量) sql = """ INSERT INTO agri_plot_vectors (plot_name, geom, soil_moisture, crop_type, embedding) VALUES (%s, ST_SetSRID(ST_MakePoint(%s, %s), 4326), %s, %s, %s) """ cursor.execute(sql, (plot_name, lon, lat, soil_moisture, crop_type, embedding)) conn.commit()# 插入示例数据(郑州小麦地块)insert_plot_vector( plot_name="郑州中牟小麦地块1号", lon=114.32, lat=34.56, soil_moisture=15.2, crop_type="小麦", text_desc="郑州中牟1号小麦地块,东经114.32°北纬34.56°,土壤墒情15.2%,海拔85米,2025年种植冬小麦")# 3. 相似性检索(带地理范围过滤)def search_similar_plots(query_text, lon, lat, radius_km=10, top_k=5): # 生成查询向量 query_embedding = model.encode(query_text).tolist() # SQL:先过滤10km范围内的地块,再按余弦相似度检索 sql = """ SELECT plot_name, soil_moisture, crop_type, ST_Distance(geom, ST_SetSRID(ST_MakePoint(%s, %s), 4326))/1000 as distance_km, 1 - (embedding <=> %s) as similarity -- 余弦相似度(<=>是PGVector的余弦距离算子) FROM agri_plot_vectors WHERE ST_DWithin(geom, ST_SetSRID(ST_MakePoint(%s, %s), 4326), %s * 1000) ORDER BY similarity DESC LIMIT %s """ cursor.execute(sql, (lon, lat, query_embedding, lon, lat, radius_km, top_k)) return cursor.fetchall()# 检索示例:找“郑州10km内干旱小麦地块”results = search_similar_plots( query_text="干旱小麦地块,土壤墒情低于20%", lon=114.32, lat=34.56, radius_km=10, top_k=5)print("相似地块检索结果:")for res in results: print(f"地块名称:{res['plot_name']},相似度:{res['similarity']:.2f},距离:{res['distance_km']:.2f}km")# 关闭连接cursor.close()conn.close()
四、第三步:RAG 集成步骤(农业 GIS 智能问答)
RAG 是农业 GIS 落地的核心场景(如 “查询郑州中牟 10km 内干旱小麦地块的灌溉建议”),以下是端到端集成步骤:
步骤 1:数据准备与向量入库
- 收集农业 GIS 知识库:包括灌溉手册、墒情分析报告、地块档案、GIS 操作文档;
- 预处理:将长文档切分为 500 字左右的片段(避免向量丢失细节),给每个片段添加空间标签(如 “郑州 / 小麦 / 墒情”);
- 生成向量:用农业版 Embedding 模型生成每个片段的向量;
- 入库:将 “文本片段 + 向量 + 空间标签” 存入 PGVector+PostGIS(参考第二步的插入代码)。
步骤 2:构建 RAG 检索模块
核心逻辑:用户查询→解析空间条件→生成查询向量→空间过滤 + 向量相似检索→返回 Top-N 相关片段。
def rag_retrieval(query, lon=None, lat=None, radius_km=None, top_k=3): """ 农业GIS RAG检索模块 :param query: 用户自然语言查询(如“郑州中牟干旱小麦地块灌溉建议”) :param lon/lat: 查询中心点经纬度(解析自用户查询) :param radius_km: 地理范围 :param top_k: 返回相似片段数 :return: 拼接后的上下文文本 """ # 1. 解析用户查询中的空间条件(可结合LLM提取,如用ChatGLM提取经纬度/作物类型) # (简化版:手动指定,实际项目用LLM解析) if not (lon and lat): lon, lat = 114.32, 34.56 # 默认郑州中牟 # 2. 生成查询向量 query_embedding = model.encode(query).tolist() # 3. 带空间过滤的向量检索 sql = """ SELECT text_segment, 1 - (embedding <=> %s) as similarity FROM agri_gis_knowledge WHERE ST_DWithin(geom, ST_SetSRID(ST_MakePoint(%s, %s), 4326), %s * 1000) ORDER BY similarity DESC LIMIT %s """ cursor.execute(sql, (query_embedding, lon, lat, radius_km or 10, top_k)) results = cursor.fetchall() # 4. 拼接上下文 context = "\n".join([res['text_segment'] for res in results]) return context
步骤 3:集成大模型生成答案
选择适配农业的大模型(如文心一言农业版、ChatGLM-4 农业微调版),将检索到的上下文传入模型生成答案:
from openai import OpenAI # 若用开源模型,替换为transformers加载ChatGLM等# 初始化大模型客户端(以OpenAI兼容接口为例,开源模型可本地部署)client = OpenAI( base_url="https://api.agri-llm.com/v1", # 农业大模型接口 api_key="your_api_key")def agri_gis_rag_qa(query, lon=None, lat=None, radius_km=None): """ 农业GIS RAG智能问答主函数 """ # 1. 检索相关上下文 context = rag_retrieval(query, lon, lat, radius_km) # 2. 构建提示词(适配农业GIS场景) prompt = f""" 你是农业GIS智能助手,需基于以下上下文回答用户问题,仅使用上下文信息,不要编造。 上下文:{context} 用户问题:{query} 回答要求:1. 结合地理空间信息;2. 给出具体的农业建议;3. 语言通俗易懂。 """ # 3. 调用大模型生成答案 response = client.chat.completions.create( model="agri-gpt-4", messages=[{"role": "user", "content": prompt}], temperature=0.1 # 降低随机性,保证答案精准 ) return response.choices[0].message.content# 测试:查询郑州中牟10km内干旱小麦地块的灌溉建议answer = agri_gis_rag_qa( query="郑州中牟10km内干旱小麦地块的灌溉建议", lon=114.32, lat=34.56, radius_km=10)print("智能回答:", answer)
步骤 4:部署与优化
- 向量索引优化:PGVector 用
hnsw索引(效率高于ivfflat),Milvus 调整索引参数(如M=16, efConstruction=64); - 缓存:对高频查询的向量和检索结果做缓存(如 Redis),减少重复计算;
- 轻量部署:FastAPI 封装 RAG 接口 + Docker 部署;
- 生产部署:K8s 集群部署,搭配 Nginx 反向代理、监控(Prometheus);
- 模型微调:用农业 GIS 语料微调 Embedding 模型,提升术语匹配精度;
- 检索增强:加入 “重排序”(如 Cross-BERT),优化 Top-N 结果的相关性。
总结
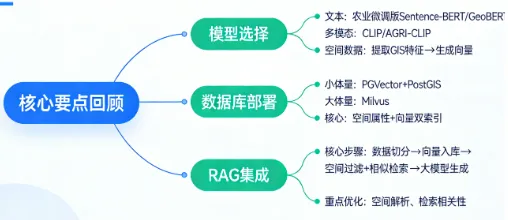
核心要点回顾
- 模型选择文本用农业微调版 Sentence-BERT/GeoBERT,多模态用 CLIP/AGRI-CLIP,空间数据先提取 GIS 特征再生成向量;
- 数据库部署小体量选 PGVector+PostGIS(易上手、支持空间过滤),大体量选 Milvus;核心是 “空间属性 + 向量” 双索引;
- RAG 集成核心步骤为 “数据切分→向量入库→空间过滤 + 相似检索→大模型生成”,重点优化空间解析和检索相关性。
落地关键
- 从小体量场景(如单一区域的地块检索)起步,验证效果后再扩容;

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
