Knowledge informed hybrid machine learning in agricultural yield prediction
通讯作者&第一作者:Malte von Bloh德国慕尼黑工业大学
🛰️🛩️🌱🌱🌱🌱🌱🌱🌱🌱🌱🧠💻
- 数据饥渴挑战:农业数据获取受限于生长周期(每年仅一收),导致ML模型在处理极端天气等分布外(OOD)数据时表现不佳。
- 范式融合需求:亟需结合基于过程的模型(PBM)的生物物理逻辑与机器学习(ML)的非线性拟合能力。
- 知识迁移验证:验证将DSSAT-Nwheat模型的领域知识迁移至神经网络(NN)能否提升田块尺度产量的预测精度。
- 分布空间扩展:探索利用未来气候预测数据增强模型在极端环境下的鲁棒性。
- 合成数据增强:利用2037-2099年未来气候预测(CP)生成合成样本,以覆盖历史数据中缺失的极端高温情景。
- 多任务损失约束:采用截断损失函数(Truncated Loss),强制NN在预测产量的同时学习126个动态作物生长参数。
- 跨品种泛化策略:仅对单一参考品种进行精细参数化,利用
主要发现:
- 分布优于数量:研究证实数据分布的覆盖范围(尤其是分布尾部的极端高温)比单纯增加样本量对模型提升更大。
- 架构表现差异:神经网络在整合物理知识方面显著优于随机森林,后者易过度拟合
- 关键驱动因子:高温条件下的合成数据是降低模型误差的核心,而降水增强的效果相对有限。
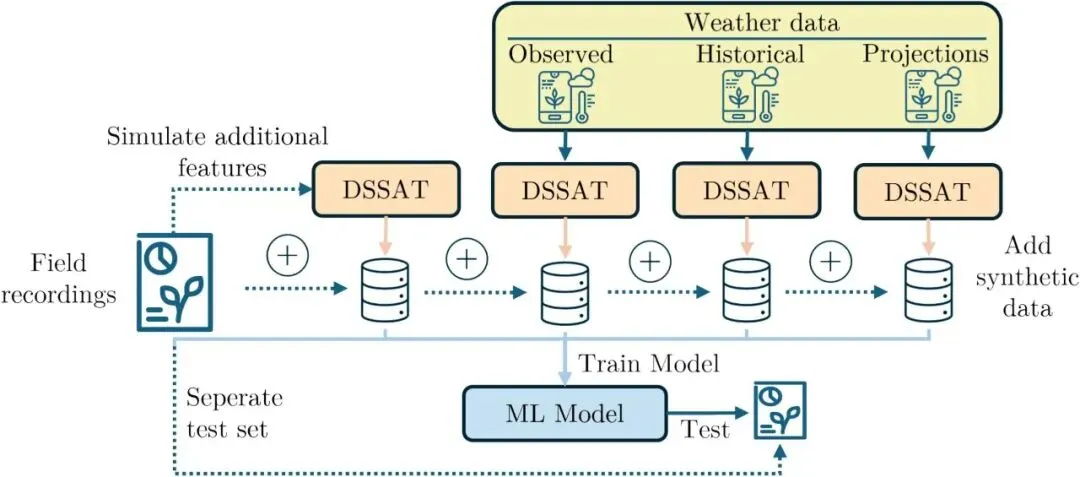
通过添加额外的特征或样本并扩展训练集的分布空间,生成了不同的数据集。这些训练集彼此连续补充。为了生成合成特征和样本,我们应用了农业技术转移决策支持系统框架(DSSAT-Nwheat)中的基于过程的作物模型 NWeath。DSSAT-Nwheat 模拟和扩展气候特征分布使用了历史数据(1986–2004 年)、观测数据(2005–2021 年)和未来天气预测数据(2037–2099 年)。为了进行测试,我们从记录的田间数据集中剔除了一年的数据。此过程在所有年份上迭代重复。
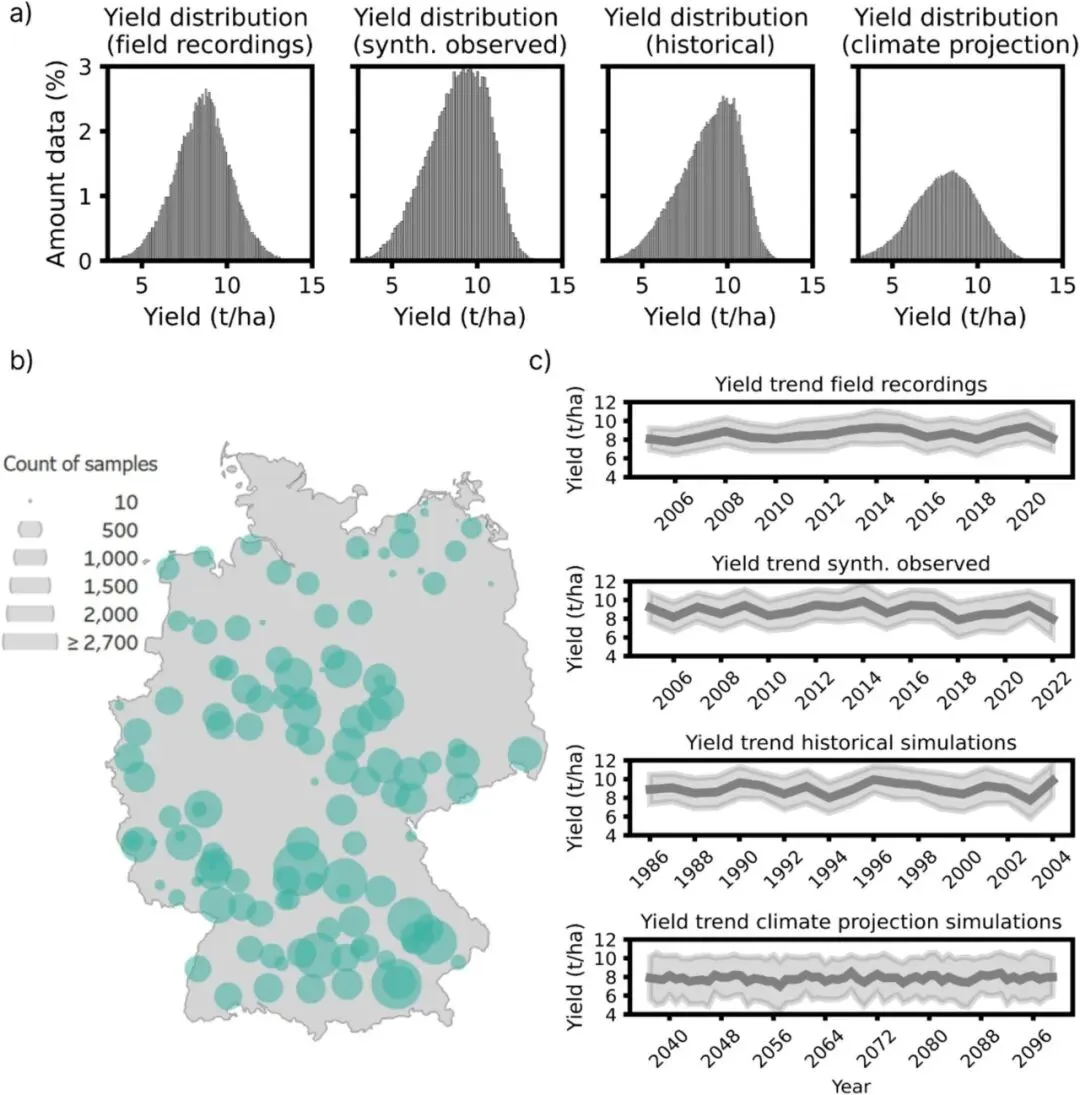
a ) 显示了真实数据集(实地记录)以及三个合成数据集的产量分布,这些合成数据集分别来自历史时期(1986–2004 年)、气候预测模拟(2037–2099 年)和基于观测时间段(2005–2021 年)气象数据的模拟。b) 显示了德国境内各站点的空间分布。气泡大小表示每个站点的数据集长度。c) 显示了数据集中各时间段产量变量的趋势线。
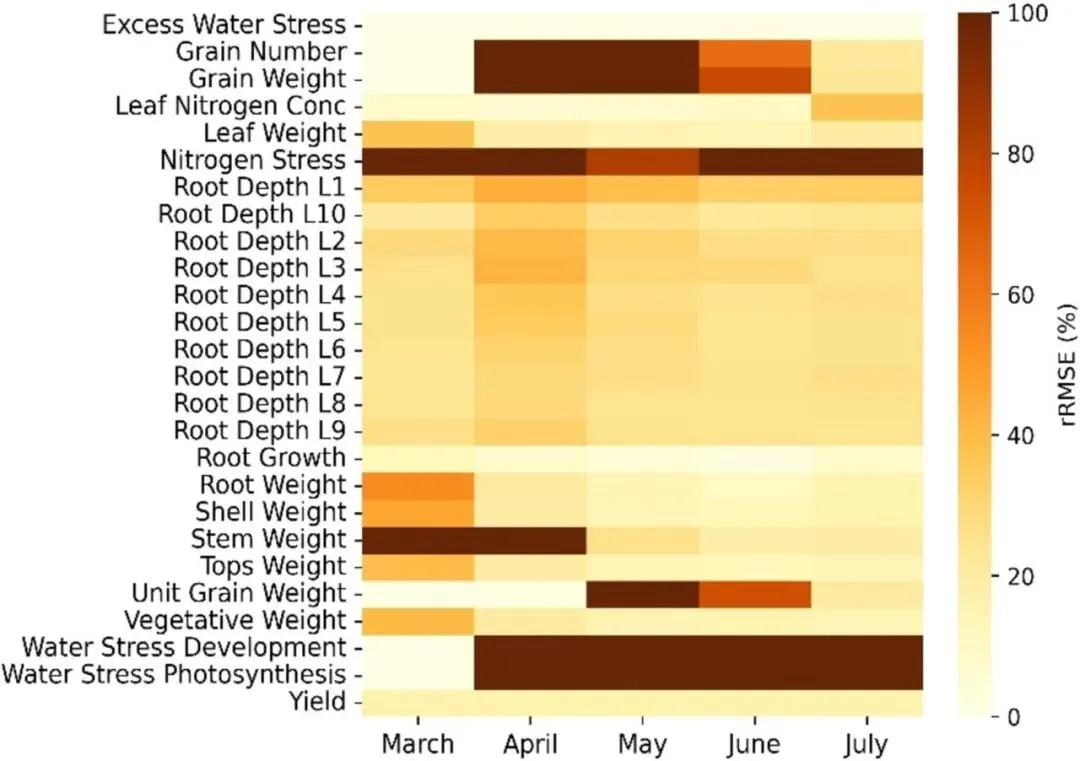
显示了目标时间段内作物特征的 rRMSE 损失(仅显示相对值,无单位,因为大多数特征的单位不同)。为了便于可视化,rRMSE 的阈值设置为 100%。损失峰值分别对应于水分胁迫发展(283%)、光合作用期间的水分胁迫(254%)和氮胁迫(241%)。每月 rRMSE 中位数的梯度表明,7 月份临近收获期的状态模拟效果更好。产量变量并非时间序列特征,始终与季末产量相关。
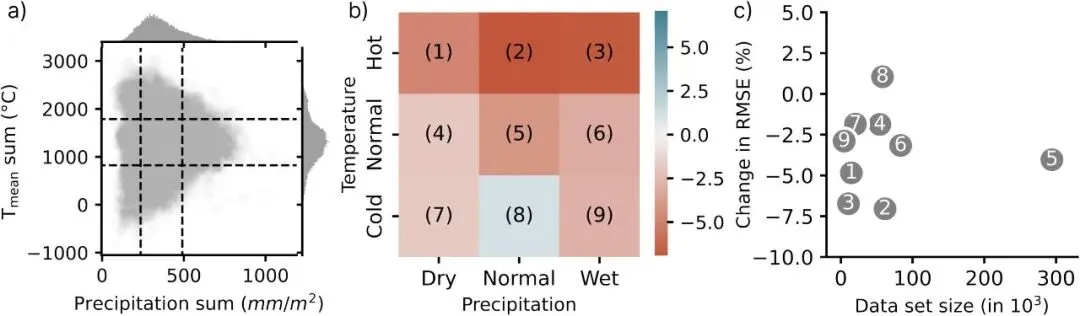
a ) 显示了基于 2 月至 6 月平均温度和降水量阈值定义的合成样本的二维分布。这决定了类别的划分,这些类别显示在 b) 中,并表示将一个类别与现场记录关联时均方根误差 (RMSE) 的变化。c) 表示每个类别的样本量与误差变化的关系。值得学习的细节:
前瞻性数据增强:利用2037-2099年的气候预测数据来“预演”极端环境,解决了当前观测数据中极端样本不足的痛点。
截断式多任务约束:通过截断损失函数实现了物理规律与统计特征的动态平衡,既保证了生长逻辑的合理性,又兼顾了产量预测的精度。
跨品种泛化:利用ML的泛化能力弥补了PBM参数化困难的缺陷,实现了“一处调参,多处受益”。
推荐指数:⭐⭐⭐⭐⭐
链接
—
https://doi.org/10.1016/j.compag.2024.109606
 【权责声明】
【权责声明】