1
数据探索与可视化
1.1 读数据表
本数据集来源于智能农业生产优化场景,包含2200条土壤和气候观测记录,用于推荐最适宜的作物。数据字段包括:N(土壤氮含量)、P(土壤磷含量)、K(土壤钾含量)、temperature(温度,摄氏度)、humidity(相对湿度,百分比)、ph(土壤酸碱度)、rainfall(降雨量,毫米)以及目标字段label(推荐作物名称)。作物种类涵盖水稻、玉米、鹰嘴豆、绿豆、黑豆、扁豆、石榴、香蕉、芒果等22种。通过分析土壤养分与气候条件,可帮助农户精准选择作物,提高产量。
氮元素(N)至关重要,它是叶绿素的主要组成成分。植物依靠叶绿素,利用光能将水和二氧化碳合成糖类,也就是光合作用。氮也是氨基酸的核心成分,而氨基酸是构成蛋白质的基础。植物一旦缺乏蛋白质,就会枯萎死亡。
因此,磷元素(P)对细胞分裂与新生组织发育起着关键作用,同时参与植物体内复杂的能量转化过程。在有效磷含量不足的土壤中施加磷肥,能够促进根系生长、提升植株抗寒能力、促进分蘖,并加快作物成熟。
钾元素(K)是植物从土壤与肥料中摄取的关键营养元素,可增强植株抗病性、促使茎秆直立健壮、提升耐旱能力,帮助作物安全越冬。
适宜生物活动的平均土壤温度范围(temperature)为 50 至 75 华氏度。该温度区间利于土壤生物正常生理活动,可保障有机质充分分解、加快氮素矿化、促进可溶性养分吸收与植物新陈代谢。
5.5–6.5 的酸碱度(ph)区间最适宜植物生长,此范围内各类养分的有效性达到最佳。
除病害外,降雨量(rainfall)也会影响农作物从播种到成熟的生长速度,决定收获时间。降水均衡搭配合理灌溉,能加快作物生长,缩短发芽周期,减少播种至采收的间隔时长。
数据预览显示前10条均为水稻(rice)记录,其N含量在60-94之间,P含量35-58,K含量38-44,temperature约20-26°C,humidity约80-83%,ph值5.7-7.8,rainfall约202-271毫米。这些数值反映了水稻生长的典型环境,为后续分析提供了基础。
1.2 氮含量分布直方图
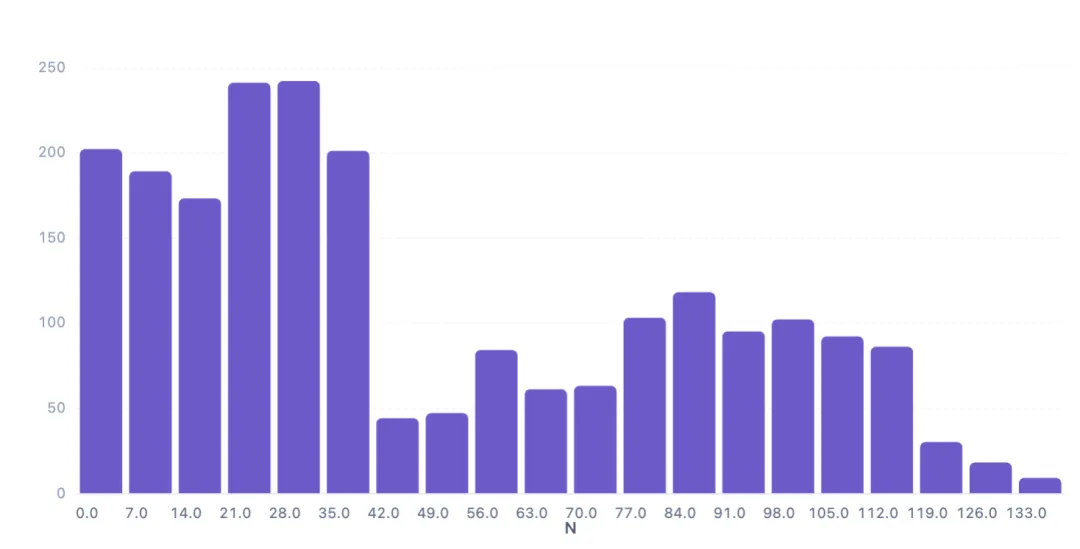
为了解土壤氮含量(N)的分布特征,绘制了含20个区间的直方图。通过观察分布形态,可以判断数据是否平衡,为后续建模提供参考。
直方图显示,N值在0-140范围内分布,主要集中在0-42区间(约1007条)和63-105区间(约562条),呈现双峰分布。峰值出现在21-28和28-35区间,分别有241和242条记录。高氮(>133)样本较少,仅9条。这表明土壤氮含量在不同作物间差异较大,有助于模型区分作物类型。
1.3 磷含量分布直方图
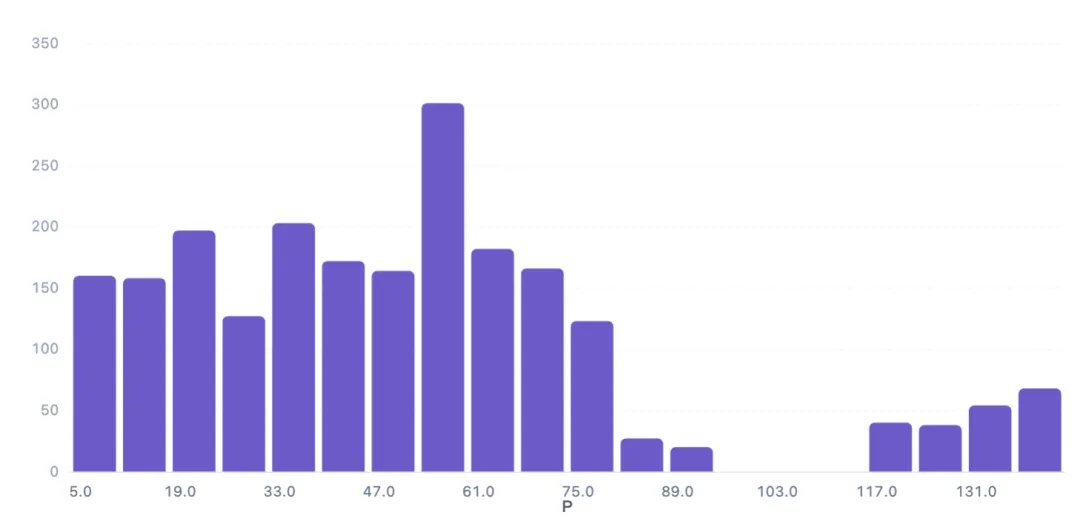
分析土壤磷含量(P)的分布,为后续特征工程提供依据。同样采用20个区间直方图,观察数据集中趋势与异常值。
P值分布范围约5-145,主要集中在5-82区间。其中54-61区间样本最多(301条),其次为33-40区间(203条)和19-26区间(197条)。值得注意的是,96-110区间无样本,而138以上有68条,呈现右侧长尾。这表明磷含量在不同作物间存在差异,部分作物可能需要高磷土壤。
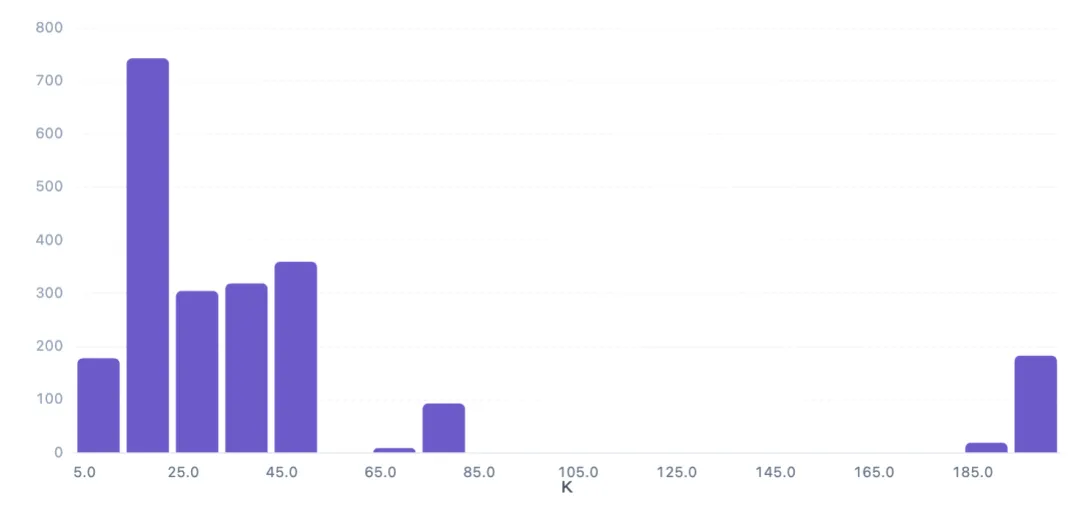
1.4 钾含量分布直方图
钾含量(K)是作物生长的关键养分,通过直方图探究其分布规律,为模型特征选择提供参考。
K值分布极不均匀:15-25区间样本最多(742条),占总数33.7%;其次为45-55区间(359条)和35-45区间(318条)。而55-65、85-115等区间样本为0,但195以上有182条,形成明显右尾。这种分布特征有助于模型识别不同作物对钾的需求差异。
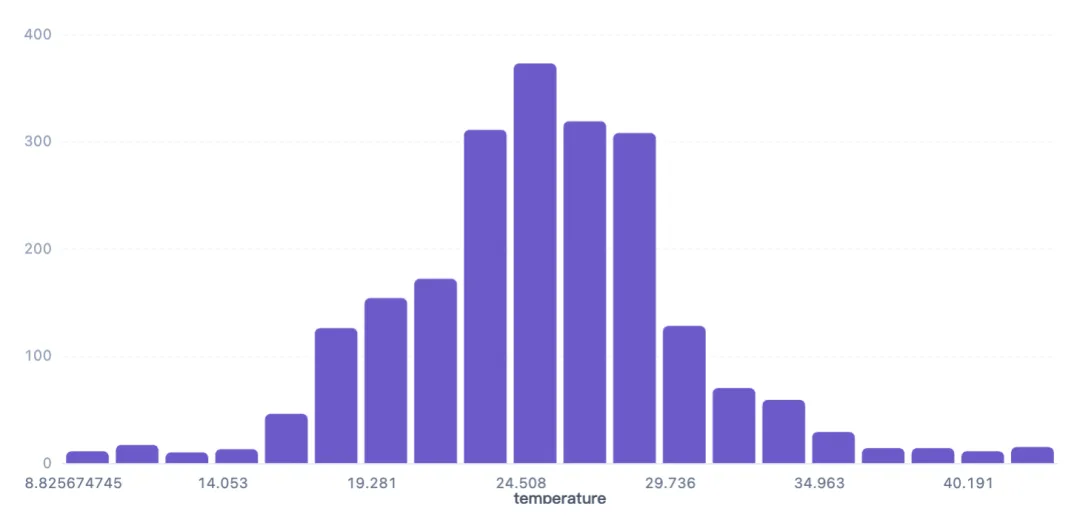
1.5 温度分布直方图
温度(temperature)是影响作物生长的重要气候因素,通过直方图观察其整体分布,了解数据覆盖的温度范围。
温度范围约8.8-44°C,主要集中在19-30°C,其中24.5-26.3°C区间样本最多(373条),其次为26.3-28.0°C(319条)和22.8-24.5°C(311条)。低温(<15°C)和高温(>35°C)样本较少,符合多数作物的生长温度范围。
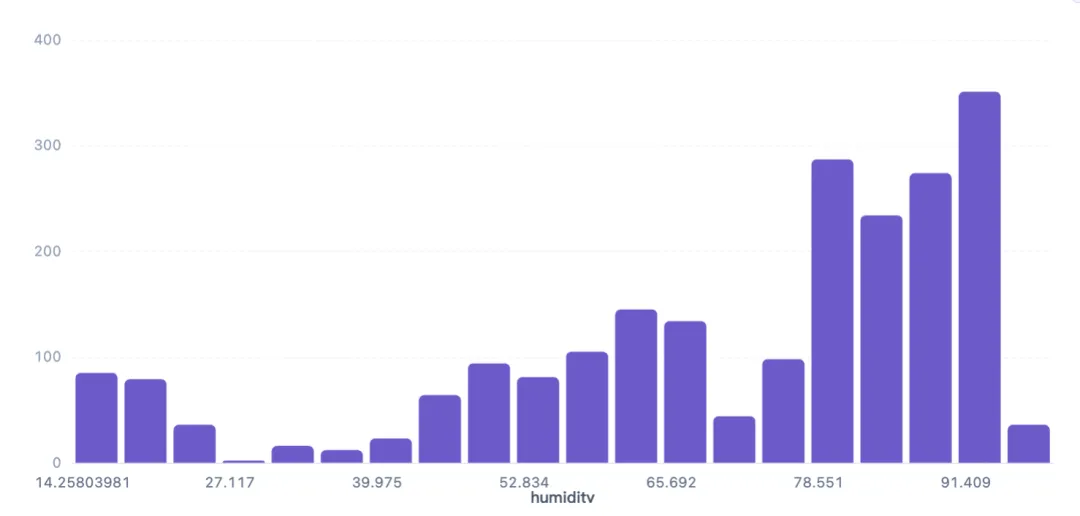
1.6 湿度分布直方图
湿度(humidity)对作物蒸腾和病害发生有重要影响,绘制直方图以了解其分布特征。
湿度范围约14-100%,分布呈多峰:高湿度区间(82-96%)样本密集,其中91-96%区间最多(351条),82-87%区间287条,87-91%区间274条。低湿度(<35%)样本较少,仅约200条。这表明多数作物偏好高湿环境,但部分作物可能适应干燥条件。
1.7 降雨量分布直方图
降雨量(rainfall)是决定作物灌溉需求的关键因素,通过直方图分析其分布,为后续建模提供特征理解。
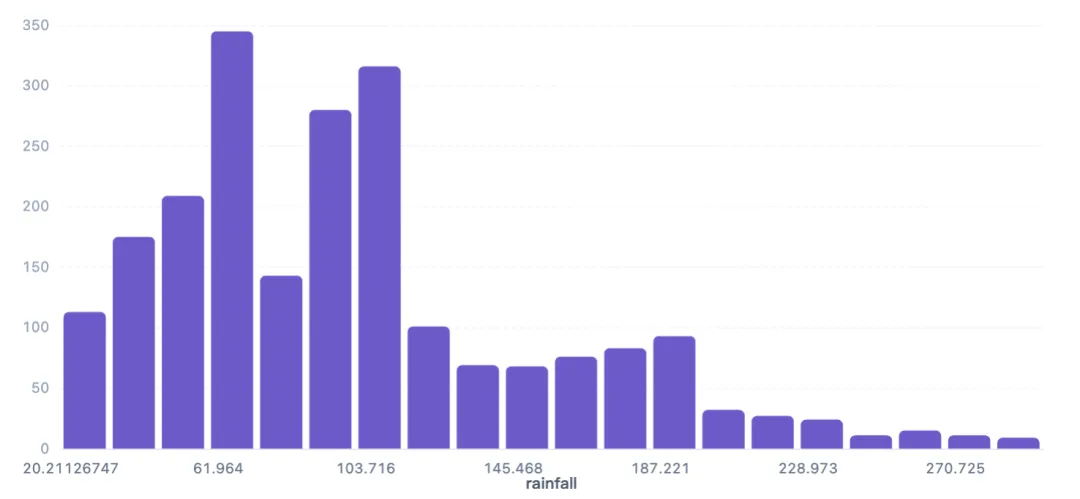
降雨量范围约20-300毫米,分布呈左偏:主要集中在48-118毫米区间,其中61-76毫米区间样本最多(345条),其次为103-118毫米(316条)和89-103毫米(280条)。高降雨量(>200毫米)样本较少,仅约200条。这反映了不同作物对水分的需求差异。
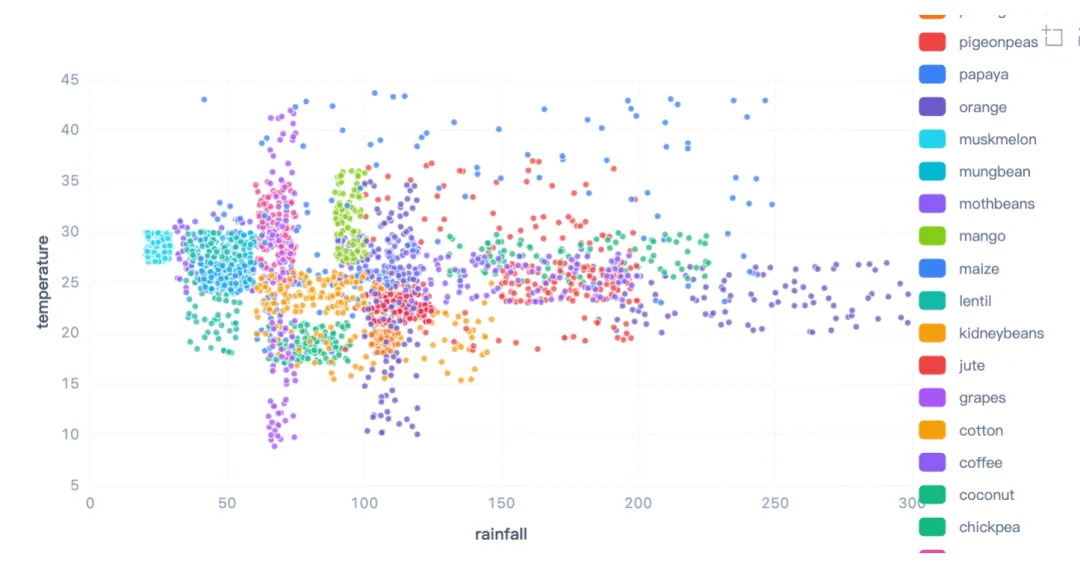
1.8
降雨量-温度散点图
前置说明
通过散点图探索降雨量(rainfall)与温度(temperature)的关系,并用作物标签(label)着色,观察不同作物在气候空间中的分布模式。
散点图显示,不同作物在降雨量-温度空间中有明显聚类。例如,水稻(rice)集中在高温高降雨区域(温度20-26°C,降雨200-270毫米),而鹰嘴豆(chickpea)可能分布在较低温区域。这种分离表明温度和降雨量是区分作物的重要特征。
2
数据预处理与建模
2.1 标签数字编码
将作物标签(label)进行数值编码,以便机器学习模型处理。编码映射:apple=0, banana=1, blackgram=2, chickpea=3, coconut=4, coffee=5, cotton=6, grapes=7, jute=8, kidneybeans=9, lentil=10, maize=11, mango=12, mothbeans=13, mungbean=14, muskmelon=15, orange=16, papaya=17, pigeonpeas=18, pomegranate=19, rice=20, watermelon=21。
| | | | | | | |
|---|
| | | | | | | |
| 90 | 42 | 43 | 20.87974371 | 82.00274423 | 6.502985292 | 202.9355362 | 20 |
| 85 | 58 | 41 | 21.77046169 | 80.31964408 | 7.038096361 | 226.6555374 | 20 |
| 60 | 55 | 44 | 23.00445915 | 82.3207629 | 7.840207144 | 263.9642476 | 20 |
| 74 | 35 | 40 | 26.49109635 | 80.15836264 | 6.980400905 | 242.8640342 | 20 |
| 78 | 42 | 42 | 20.13017482 | 81.60487287 | 7.628472891 | 262.7173405 | 20 |
label
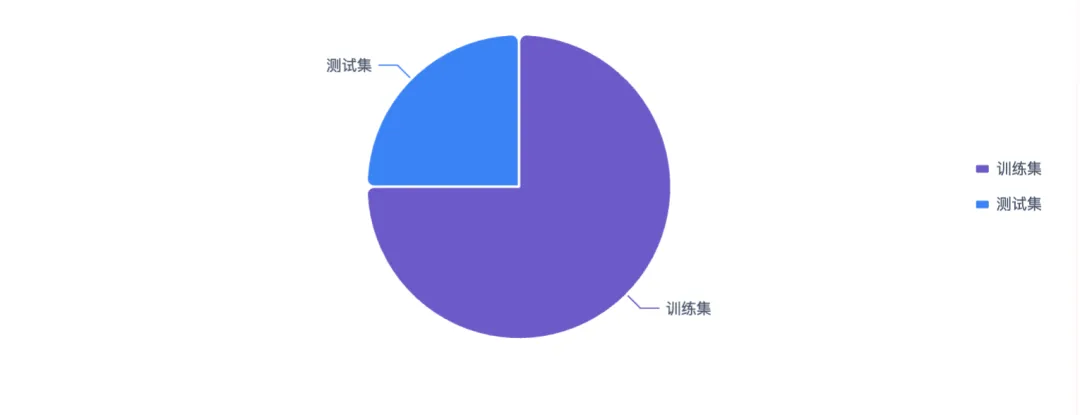
2.2 训练测试集划分
将数据集按75%训练集、25%测试集随机划分,用于后续模型训练与评估。目标列(label)不进行分层抽样,随机种子设为0以保证结果可复现。
划分结果:训练集1650条,测试集550条,比例符合预期。
2.3 随机森林分类(目标:label)
采用随机森林分类器进行建模,特征为N、P、K、temperature、humidity、ph、rainfall,目标为编码后的label。参数设置:弱模型数量10,分裂标准基尼系数,最大深度不限,节点最小样本数2,叶节点最小样本数1。
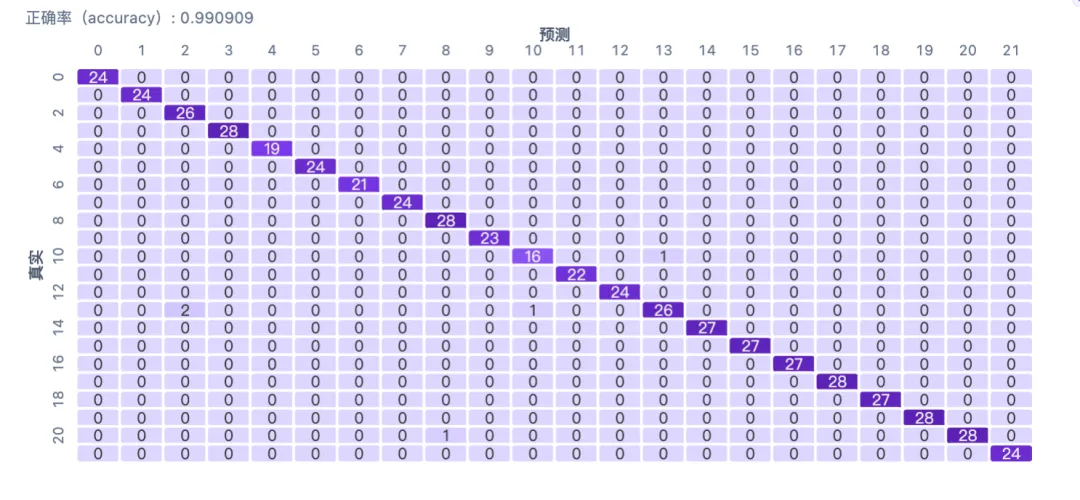
训练集分类报告
训练集准确率: 0.9988
训练时间: 0.04s
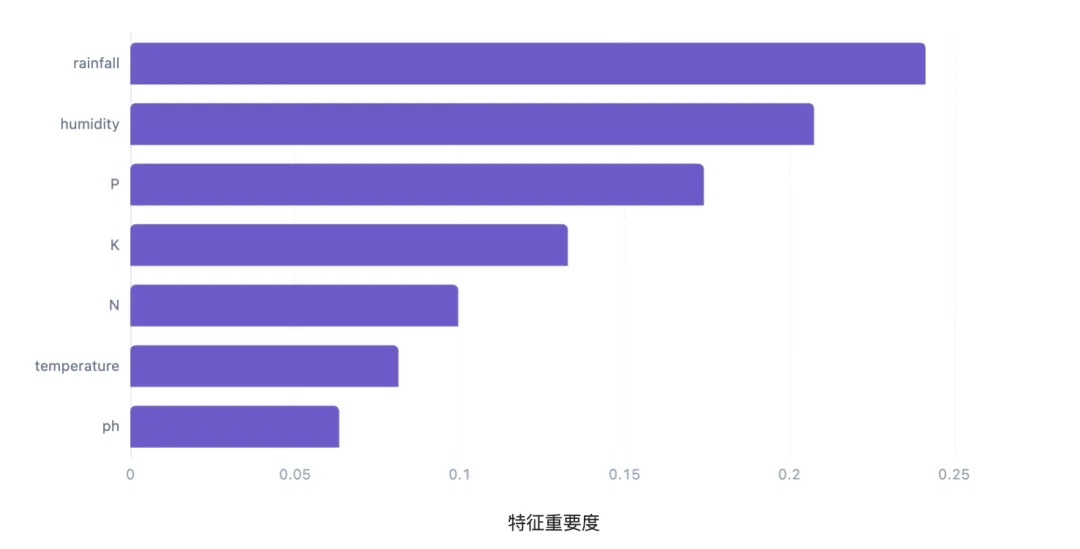
模型训练准确率达0.9988。特征重要性排序:rainfall(0.241)、humidity(0.208)、P(0.174)、K(0.133)、N(0.100)、temperature(0.081)、ph(0.063)。降雨量和湿度是最重要的特征,表明水分条件对作物推荐影响最大。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
