科研、项目合作:panp6600 (注明来意,清北硕博团队专注于AI for Science自研大模型,接受天使轮投资,欢迎投资者咨询)
————————————
本文内容独家整理,盗用必究
来源:Lou et al., Plant Communications, 2026
2024年诺贝尔化学奖颁给了David Baker、Demis Hassabis与John M. Jumper,以表彰他们在蛋白质设计与结构预测领域的突破性贡献。这一奖项宣告了AI驱动的蛋白质工程时代的到来。然而,相较于生物医学领域已经大规模应用AI蛋白质设计的现状,植物科学领域的跟进明显滞后。
近期,中国农业大学农学与生物技术学院王向峰教授团队在《Plant Communications》发表了一篇系统性综述,全面梳理了AI大模型驱动蛋白质设计的核心原理、模型体系与工具链,并以玉米关键基因ZmGID1和ZmGA20ox3为案例,深入阐释了这些技术如何从假说生成到实验验证,落地于植物基础研究与作物育种。
蛋白质语言大模型:让序列"开口说话"
现代蛋白质设计的核心基础是蛋白质语言模型(Protein Language Models,PLMs)。PLMs本质上是在数亿条蛋白质序列上预训练的深度学习架构,通过学习氨基酸序列中的"语法规则",将蛋白质映射到连续向量空间,从而捕获生物物理与功能属性。
PLMs的预训练策略主要有三类:掩码语言建模(MLM)随机掩盖序列中的氨基酸残基,让模型预测被掩码位置;自回归建模逐步利用已生成信息预测下一个残基;扩散建模则通过学习逐步去噪过程,从噪声中生成蛋白质序列或结构。
根据输入模态的不同,PLMs可分为三大类:
- 序列单模态模型:如ProtTrans、ESM2、DPLM,仅依赖氨基酸序列学习上下文嵌入
- 结构单模态模型:如GearNet,以蛋白质3D结构的几何图为输入,通过自监督预测与对比学习建模空间构象
- 多模态模型:如SaProt、ESM3、DPLM-2,整合序列、结构与生物注释信息
Table 2(蛋白质语言模型及衍生工具汇总表) 详细列出了各类PLM及其衍生工具,涵盖从热稳定性预测(TemStaPro)、酶动力学预测(UniKP)到蛋白质溶解度预测(NetSolP)等应用。
结构预测大模型的技术原理
AlphaFold系列:从MSA到扩散架构
AlphaFold2(AF2) 的核心是Evoformer模块,该模块利用注意力网络动态权重化输入元素,从多序列比对(MSA)中高效提取保守信息。AlphaFold3(AF3) 则引入了基于扩散的架构,能够同时建模蛋白质、核酸、配体、金属离子及翻译后修饰残基等多类生物分子复合物。
论文详细介绍了扩散模型的数学原理。DDPM(去噪扩散概率模型)的前向扩散过程定义为:
其中 为 的条件概率分布, 为均值 、协方差 的正态分布, 为第 步的噪声水平, 为单位矩阵。模型的目标是学习逆过程 ,从噪声中逐步还原蛋白质结构。
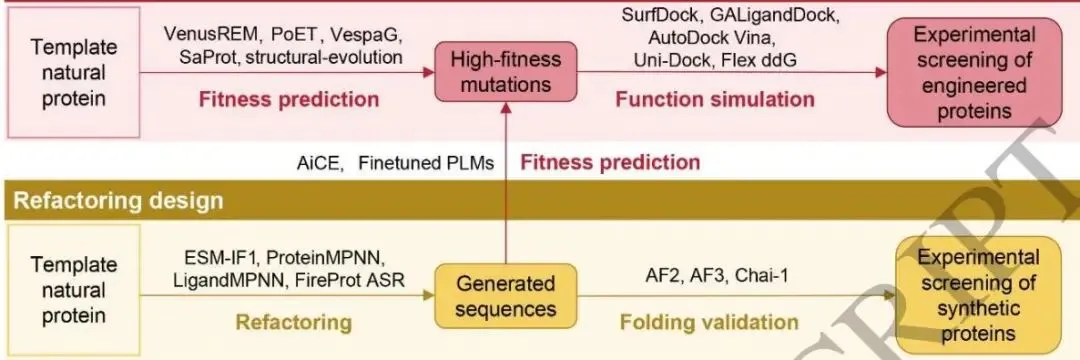
图1(论文Figure 1)给出了蛋白质理性/半理性设计(A)、重构设计(B)、从头设计(C)的通用工具与流程,以及DNA级语言模型(D)和植物中蛋白质设计的整体工作流程(E)。
FoldBench基准测试:AF3全面领先
论文援引最新发布的FoldBench基准,系统评估了AF3与其开源复现版本(Chai-1、Boltz-1、HelixFold3、Protenix)的性能。
Table 1(AF3类蛋白质结构预测模型在FoldBench上的对比) 数据如下:
AF3在整体精度上全面领先,但抗体-抗原复合物预测仍是所有方法的共同短板(成功率约20%量级),蛋白-配体对接对新型配体的泛化能力亦有限。
突变效应预测:理性设计的核心引擎
突变效应(Mutational Effect,ME)预测是理性设计与半理性设计的核心环节,即使单个氨基酸的改变也能剧烈影响蛋白质功能。
SaProt通过将蛋白质序列与预测结构统一纳入结构感知词汇表,将结构信息整合进PLM,从而提升突变效应预测精度。VenusREM在ProteinGym基准中同样名列前茅,其ProtREM模型利用序列同源性进行检索增强预测。EVOLVEpro则将ME预测与主动学习结合,在每轮优化周期中仅生成少量实验数据即可迭代精化模型,实现低数据成本下的蛋白质定向进化。
蛋白质生成:骨架设计与序列设计
反向折叠:从结构到序列
反向折叠(Inverse Folding)的核心问题是:给定目标蛋白质骨架结构 ,找到能正确折叠进入该骨架的氨基酸序列 。形式化表达为:
其中 为蛋白质骨架的固定3D坐标(如原子及主链原子位置), 为氨基酸序列。ProteinMPNN和ESM-IF1采用GNN编码器编码骨架几何特征,结合自回归解码器生成序列,相较传统能量函数方法(如Rosetta Packer、ABACUS)精度与速度均有大幅提升。
幻觉设计:梯度驱动的结合物创造
幻觉设计(Hallucination Design)通过对预训练结构预测网络(如AlphaFold-Multimer)反向传播梯度,迭代优化设计序列,使预测复合物满足预设的结构和界面标准。以BindCraft为代表,其核心数学表达为最小化多项损失之和:
其中 为结合物序列, 为固定目标蛋白; 衡量折叠结构的预测置信度; 促进结合物与靶标之间的有利分子间接触; 施加结构先验约束(如二级结构比例、旋转半径)。通过基于梯度的优化在序列表示(连续logits或概率)上进行迭代更新,从而"幻觉"出与靶标形成稳定复合物的全新结合物序列。
流匹配模型:扩散之外的高效替代
与扩散模型逐步去噪的迭代采样不同,流匹配(Flow Matching)直接学习从随机噪声映射到蛋白质数据的连续向量场,通过求解常微分方程:
其中 从噪声平滑流向数据,训练目标是优化 以匹配数据分布的概率流。这使得流匹配通常能以更少采样步骤、更低计算成本达到相当甚至更优的结构质量,代表性模型包括SE(3)-Stochastic Flow Matching和Framediff。
对比学习与自预测:蛋白质结构表示学习的两大范式
论文在Box 1中给出了结构模型GearNet所使用的两类预训练策略的严格数学表达。
自预测(Self-prediction) 令 为蛋白质残基图( 为节点集,每个节点代表一个 ; 为边集; 为边类型集), 为节点 的独热编码残基类型, 为被掩码节点集, 为隐去掩码节点残基类型特征的图。以模型参数 的训练损失为:
对比学习(Contrastive Learning) 令 为一种视角(如子序列截取或子空间截取生成的蛋白质子结构视角)的嵌入, 为其匹配视角(同一蛋白质另一子结构视角)的嵌入, 为不匹配视角(其他蛋白质子结构视角)的嵌入, 为相似度函数(通常为余弦相似度), 为温度参数。常用损失为:
玉米ZmGID1案例:AI如何驱动植物研究假说生成
论文以玉米赤霉素受体ZmGID1为例,展示了AI工具链如何从结构建模到功能验证的完整流程。
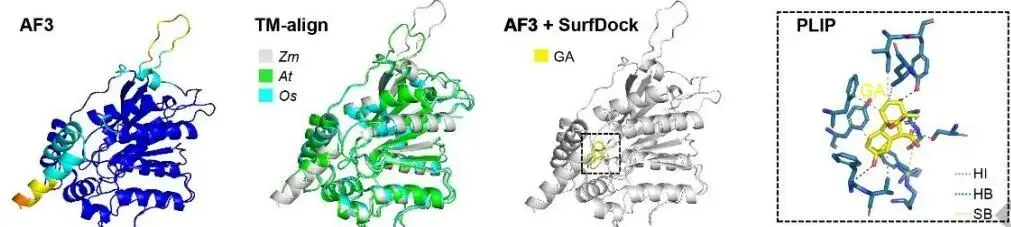
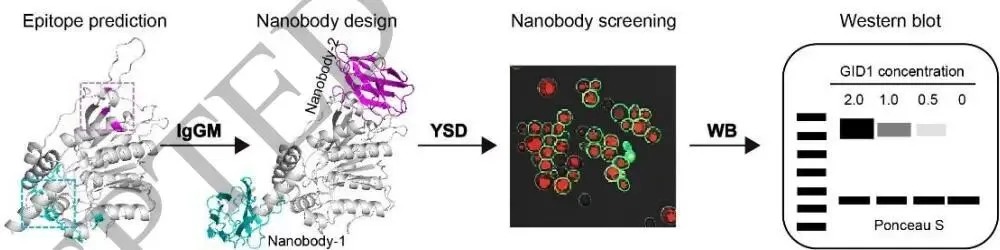
图2(论文Figure 2)详细展示了ZmGID1的结构建模、蛋白质-蛋白质相互作用预测、分子动力学模拟、纳米抗体设计及bioPROTAC靶向降解设计的全流程。
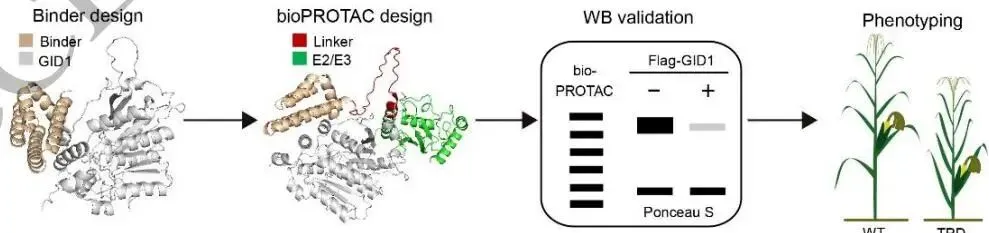
具体流程如下:
第一步,结构建模与配体对接。 由于ZmGID1目前没有实验解析的三维结构,团队首先用AF3预测ZmGID1的三维结构。值得注意的是,AF3预测结果在N端螺旋区域显示出较低的pLDDT置信度分值,暗示该区域存在构象柔性,这与拟南芥GID1同源区域报道的动态行为高度一致,表明AF3能捕捉蛋白质的内在折叠与动态特性,而非简单依赖同源模板。随后,用SurfDock将GA(赤霉素)对接至ZmGID1,PLIP工具识别出关键相互作用类型(疏水相互作用HI、氢键HB、盐桥SB)。
第二步,蛋白质复合物建模。 AF3建模GA–GID1–DELLA三元复合物,GPSite和PDBePISA识别界面残基,US-align进行跨物种比较,EnGens将残基3D坐标降维为二维可视化。
第三步,分子动力学模拟。 利用Amber捕捉ZmGID1 N端螺旋的构象转移,将GA对接至口袋后,GROMACS的ZmGID1–ZmDELLA–GA复合物分子动力学模拟表明复合物保持稳定,N端螺旋不再发生位移,重建了赤霉素信号在玉米中的可测试机制模型。
第四步,纳米抗体设计。 Surf2Spot预测ZmGID1上的两个表位表面及热点残基,IgGM设计靶向这些热点的纳米抗体,酵母展示(YSD)筛选功能性纳米抗体,实现蛋白质共免疫沉淀、亚细胞定位等分子研究。
第五步,bioPROTAC靶向降解。 BindCraft设计结合物,构建binder-linker-E3融合蛋白,AF3预测ZmGID1–bioPROTAC–E2–泛素复合物的三维结构,转基因表达后评估ZmGID1水平降低的表型效应,与基因组编辑方法形成互补验证。
玉米ZmGA20ox3案例:作物育种中的理性与半理性设计
图3(论文Figure 3)展示了针对玉米株高调控基因ZmGA20ox3的理性设计与半理性设计流程,包括突变效应预测、结构分析和EMS诱变位点的系统评估。
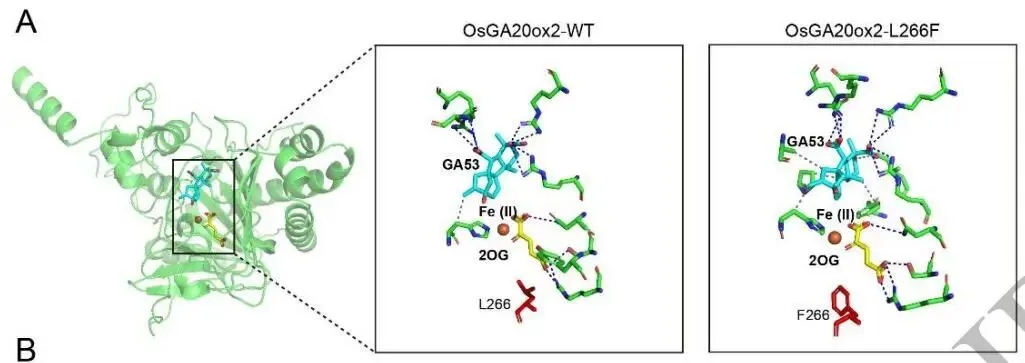
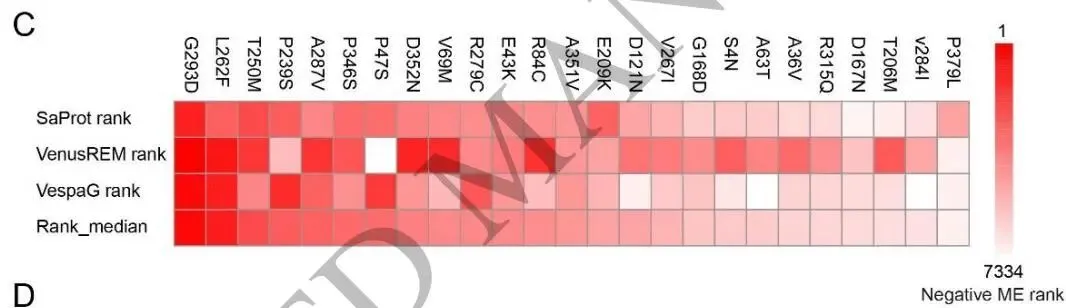
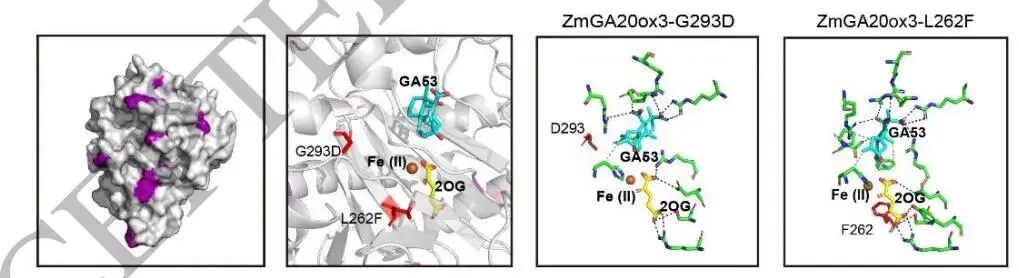
ZmGA20ox3是水稻"绿色革命"基因SD1(OsGA20ox2)的玉米直系同源基因。水稻中L266F突变(亮氨酸→苯丙氨酸)通过干扰GA生物合成导致矮化。TM-align结构比对表明,玉米ZmGA20ox3中的L270对应水稻L266,两者均位于结合口袋中且不与GA53直接接触。PLIP分析表明,OsL266F和ZmL270F突变均通过苯丙氨酸刚性苄基侧链的空间位阻,破坏GA53和2OG结合所涉及的键合相互作用模式,为通过碱基编辑或引导编辑精准引入ZmL270F突变提供了强有力的结构学依据。
进一步地,团队整合SaProt、VenusREM和VespaG三种突变效应预测工具,对ZmGA20ox3所有可能的单氨基酸替换进行系统评估,并聚焦于玉米错义突变效应预测数据库(https://maizemep.com/)中记录的25个EMS诱变非同义突变。G293D和L262F的负效应排名位于所有可能突变的前10%,与削弱GA生物合成、降低株高的目标高度一致,其构象变化分析显示两者均导致GA53在结合口袋内的构象改变及一系列相关键合作用的异常。
重构设计与从头设计:拓展作物育种的边界
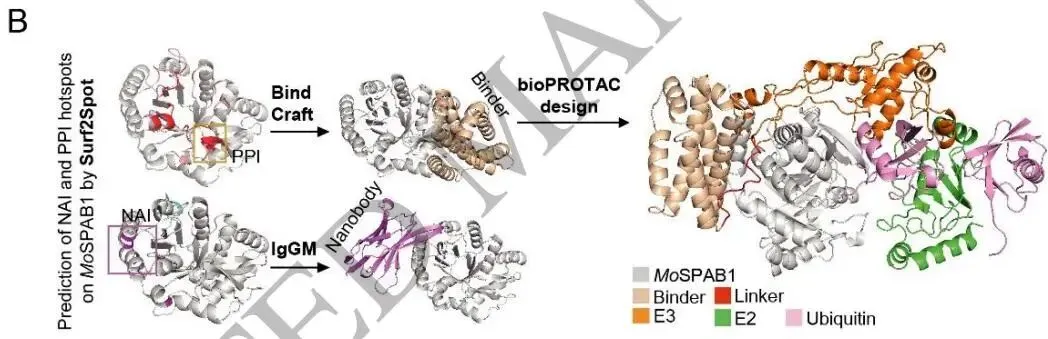
图4(论文Figure 4)展示了玉米Rubisco小亚基通过祖先序列重建进行重构设计(A)和稻瘟病菌MoSPAB1蛋白靶向纳米抗体与bioPROTAC设计(B)的方案。
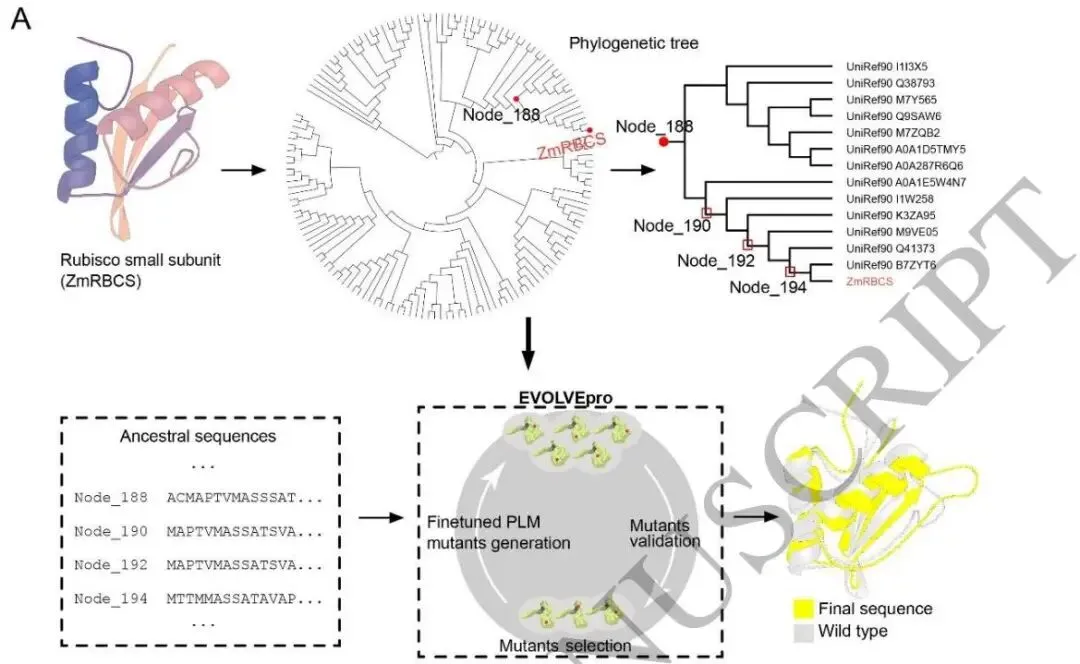
重构设计(Refactoring Design) 以玉米Rubisco小亚基(ZmRBCS)为例:利用FireProt ASR在系统发育树节点处重建祖先序列,将这些序列用于微调EVOLVEpro的蛋白质语言模型以增强突变效应预测,再以实验筛选出的优良祖先序列为起点,引入有益突变,迭代优化热稳定性与酶活性。研究表明,茄科Rubisco的复活祖先变体在催化效率和酶活性上显著优于现代版本。
从头设计(De Novo Design) 以稻瘟病菌分泌蛋白MoSPAB1为靶标,通过Surf2Spot预测纳米抗体-抗原相互作用(NAI)及蛋白质-蛋白质相互作用(PPI)位点的热点残基,分别用BindCraft和IgGM以这些热点为锚点设计结合物和纳米抗体,模拟复合物构象以确定最优结合物和连接子,构建bioPROTAC,在水稻中转基因表达以期赋予广谱抗稻瘟病性状。
蛋白质设计的通用流水线:从分子设计到田间验证
论文提出了一套覆盖理性/半理性设计、重构设计、从头设计的通用模块化流水线(Figure 1),并特别强调了DNA级语言模型在整个体系中的重要性。
设计好的蛋白质序列最终需要在基因组层面实现表达。CodonTransformer等基于预训练语言模型的密码子优化算法可针对宿主物种生成最优编码序列(CDS)。PDLLMs、Evo2、AgroNT等精调DNA语言模型可预测启动子强度与染色质可及性,指导高效启动子元件的选择或设计,以及稳定整合位点的识别。TATSI(转座酶辅助靶位点整合)等精准基因插入技术则实现转录单元在最优基因组位点的定向整合。
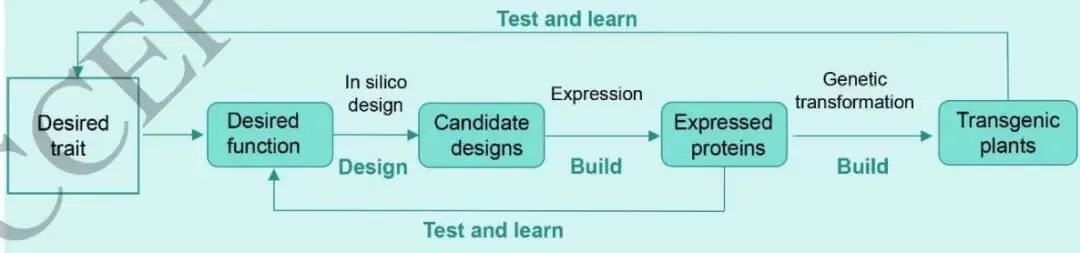
整个应用框架遵循**"设计-构建-测试-学习(Design-Build-Test-Learn)"迭代闭环**:实验室阶段完成蛋白质表达、功能筛选与模型优化;田间阶段进行转基因转化与表型选择,两个层面的数据均可反馈驱动下一轮设计优化。
面临的挑战与展望
尽管AI蛋白质设计前景广阔,论文也坦诚指出了植物领域特有的挑战:
首先,植物蛋白质实验结构数据严重匮乏。 与人类和酵母相比,植物蛋白质在PDB中的结构条目极为有限,加之植物蛋白质的物种多样性极高,限制了PLMs在植物领域的预测精度。如何利用物理化学表示原理与迁移学习开发专门针对植物生物学的大模型,是最迫切的科学问题之一。
其次,工具链门槛较高。 当前蛋白质设计需要较强的AI与编程专业知识,开发面向植物科学家的"AI4S智能体",将PLM预测与设计工具集成于友好界面,是下一步关键工程目标。
第三,合成蛋白质的生物安全问题。 在植物中表达合成蛋白质可能引入不可预见的生态与健康风险,需要在设计阶段即通过基于模型的预测来评估和规避潜在风险,并构建完善的监管框架。
第四,应用场景的拓展。 蛋白质设计在农艺性状改良之外,在植物合成生物学与生物制造方面同样大有可为,包括生物纳米材料、生物传感器、抗菌肽和治疗性蛋白的设计。
结语
AI驱动的蛋白质设计正在将植物研究范式从"发现与理解性状"向"设计与合成性状"推进。 这一转变不会孤立发生,其成功部署依赖与高通量实验筛选、基因组编辑技术和大规模田间试验的深度整合。中国农业大学王向峰教授团队这篇系统性综述为领域研究者提供了一张清晰的技术路线图,既勾勒出可落地的应用场景,也诚实地标出了前方的科学挑战。
项目相关工具:
- 玉米错义突变效应预测数据库:https://maizemep.com/
- Surf2Spot工具:https://github.com/AnwZhao/Surf2Spot
论文引用:
Lou Y, Wu T, Xia F, Zhao A, Wang X. AI-enabled protein design facilitates future plant research and crop breeding. Plant Communications. 2026. Published by Oxford University Press on behalf of American Society of Plant Biologists. https://doi.org/(原文DOI待正式发表后补充)
通讯作者:xwang@cau.edu.cn
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
